GroundCount: Teaching Drones to Count Accurately with VLMs
A new framework, GroundCount, significantly improves Vision-Language Model (VLM) counting accuracy by integrating object detection, offering a practical solution for drones to precisely count objects in real-time.

TL;DR: Vision-Language Models (VLMs) are terrible at counting, even the latest ones.
GroundCountfixes this by combining VLMs with reliable object detection models likeYOLO, improving counting accuracy by up to 7.5 percentage points and making drone perception far more trustworthy for real-world tasks.
Finally, Drones Can Count
You've seen the impressive feats of Vision-Language Models (VLMs) – describing complex scenes, answering nuanced questions about images. But ask them to count how many propellers are on a drone, and they often stumble. This isn't just a minor glitch; it's a fundamental limitation that hinders serious autonomous applications. A new paper introduces GroundCount, a practical framework designed to solve this exact problem, making VLM counting accurate enough for deployment on your next drone project.
The VLM Counting Conundrum
For all their prowess in visual reasoning, modern VLMs, even state-of-the-art ones, consistently hallucinate when it comes to simple counting tasks. Their accuracy for counting is "substantially lower than other visual reasoning tasks (excluding sentiment)" according to the authors. This isn't just about misidentifying an object; it's about failing at basic enumeration – a critical function for drones performing inventory, surveillance, or resource management. Current VLMs struggle because their internal representations often blend spatial and semantic information in a way that makes precise instance counting difficult. They might "see" a group of similar objects but fail to distinguish individual instances reliably. Object Detection Models (ODMs) like YOLO, on the other hand, are exceptionally good at finding and bounding individual objects, but they lack the broader contextual understanding of VLMs. This creates a frustrating gap: intelligent reasoning without reliable numbers, or reliable numbers without intelligent reasoning.
How GroundCount Teaches VLMs to Tally
GroundCount bridges this gap by marrying the strengths of VLMs with the precision of ODMs. The core idea is simple: if the VLM struggles to count, let a model that excels at counting do that part, then feed that reliable count back into the VLM for its reasoning.
The paper explores three main strategies for this fusion, but the most immediately practical and effective is GroundCount A, a prompt-based augmentation.
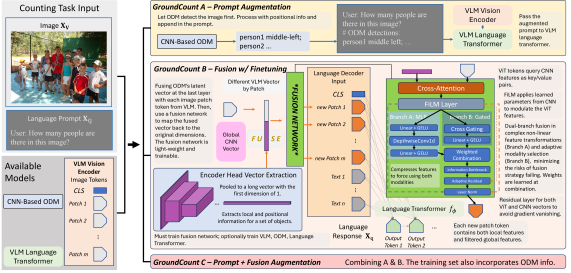 Figure 1: Structural overview of three strategies in our proposed fusion framework - A, B and C. In GroundCount A, we run inference with ODM on the image, and then include its output in the VLM prompt. In GroundCount B, we fuse the VLM and ODM on the visual patch latent vector using a light-weight network. To ensure correct information delivery, we finetune the network with our original counting task mutation from COCO. The fusion block is required to be trained; Other modules - VLM, ODM, and language transformer - are optionally frozen. GroundCount C incorporates both plans by including both prompt-level information and architectural-level integration. The training data also includes ODM detections in the textual input.
Figure 1: Structural overview of three strategies in our proposed fusion framework - A, B and C. In GroundCount A, we run inference with ODM on the image, and then include its output in the VLM prompt. In GroundCount B, we fuse the VLM and ODM on the visual patch latent vector using a light-weight network. To ensure correct information delivery, we finetune the network with our original counting task mutation from COCO. The fusion block is required to be trained; Other modules - VLM, ODM, and language transformer - are optionally frozen. GroundCount C incorporates both plans by including both prompt-level information and architectural-level integration. The training data also includes ODM detections in the textual input.
In GroundCount A, an ODM (like YOLOv13x) first processes the input image, detecting objects and providing their bounding box coordinates and confidence scores. This raw detection data is then converted into a structured textual description.
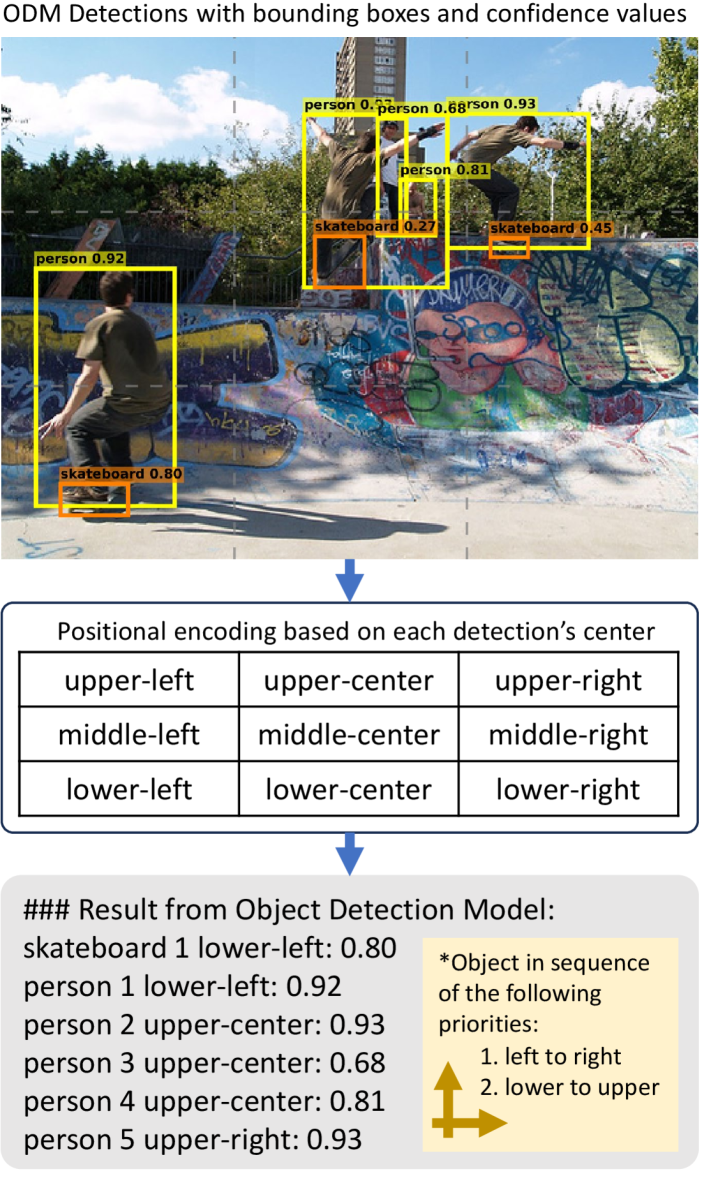 Figure 2: Our pipeline of converting ODM outputs to descriptive text. The image is #000000000077.jpg from COCO-train2017, showing 5 young people skateboarding. The bounding boxes (bbox) come from YOLOv13x’s detection: yellow ones are person objects; orange ones are skateboard objects. The location of each object is determined by the center of their corresponding bbox. Two skateboard objects were not included due to low confidence.
Figure 2: Our pipeline of converting ODM outputs to descriptive text. The image is #000000000077.jpg from COCO-train2017, showing 5 young people skateboarding. The bounding boxes (bbox) come from YOLOv13x’s detection: yellow ones are person objects; orange ones are skateboard objects. The location of each object is determined by the center of their corresponding bbox. Two skateboard objects were not included due to low confidence.
This descriptive text, detailing object types, counts, and even their rough locations (e.g., "There are 5 persons in the image, located at (x1,y1), (x2,y2)..."), is then appended to the original prompt given to the VLM. The VLM then answers the question, now equipped with explicit, accurate counting information.
 Figure 3: Illustration with real evaluation example for ODM prompt augmentation in GroundCount A. The image is #000000189241.jpg from COCO-val2014, which is used for a counting question in our selected benchmark, PhD. The tested VLM is Qwen3-VL-2B-Thinking. The question asks for a correctness judgment on the number of bowls in the image. There are indeed 2 bowls in the image, with one bowl partially covered by another. The baseline VLM, whose output is showcased in the left frame, fails to find the second bowl and re-thinks iteratively, exhibiting behaviors of hallucination. On the other hand, with information from the object detection model (ODM) appended in the prompt, the VLM successfully finds the second bowl with a double-check.
Figure 3: Illustration with real evaluation example for ODM prompt augmentation in GroundCount A. The image is #000000189241.jpg from COCO-val2014, which is used for a counting question in our selected benchmark, PhD. The tested VLM is Qwen3-VL-2B-Thinking. The question asks for a correctness judgment on the number of bowls in the image. There are indeed 2 bowls in the image, with one bowl partially covered by another. The baseline VLM, whose output is showcased in the left frame, fails to find the second bowl and re-thinks iteratively, exhibiting behaviors of hallucination. On the other hand, with information from the object detection model (ODM) appended in the prompt, the VLM successfully finds the second bowl with a double-check.
The paper also explored feature-level fusion (GroundCount B and C), where ODM and VLM features are merged before the VLM's final output. However, the explicit symbolic grounding via structured prompts (GroundCount A) generally outperformed these more complex architectural integrations.
The Numbers Don't Lie: Impressive Results
The results are compelling, especially for stronger VLM models. This isn't just a marginal gain; it's a significant leap towards reliable numerical perception.
- Accuracy Boost:
GroundCount Aachieved an 81.3% counting accuracy onOvis2.5-2B, a significant 6.6 percentage point (pp) improvement over the baseline VLM. Across four of five evaluated VLM architectures, improvements ranged from 6.2 to 7.5 pp. - Speed Up: For stronger models,
GroundCount Aactually reduced inference time by 22%. This is counter-intuitive, but the authors explain it: by providing accurate information upfront, the VLM avoids "hallucination-driven reasoning loops" where it wastes time trying to figure out a count it's bad at. - Ablation Insights: Positional encoding (telling the VLM where objects are) was critical for stronger models but surprisingly detrimental for weaker ones. Confidence scores from the ODM, often seen as important, introduced noise for most architectures, with performance improving when they were removed in four of five models. This suggests simpler, clearer input is often better.
- Fusion Strategy: Explicit prompt-based grounding consistently outperformed implicit feature fusion, highlighting the power of direct, symbolic information transfer over complex architectural integrations.
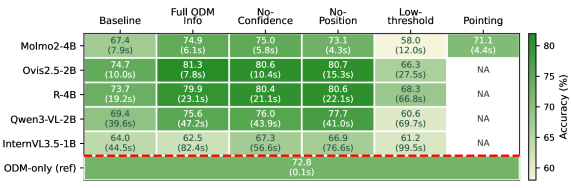 Figure 4: Results of GroundCount A across all model families and including ablation studies. Each block contains the accuracy and average inference time for that group of experiment on the PhD counting subset. The bottom row marks the result of running the object detection model only. The right-most column records the special pointing mode for Molmo2 model only.
Figure 4: Results of GroundCount A across all model families and including ablation studies. Each block contains the accuracy and average inference time for that group of experiment on the PhD counting subset. The bottom row marks the result of running the object detection model only. The right-most column records the special pointing mode for Molmo2 model only.
Why GroundCount Matters for Drones
For drone operations, GroundCount isn't just a research curiosity; it's a practical enabler. Reliable counting is foundational for many autonomous tasks:
- Inventory & Logistics: Consider a drone autonomously counting packages in a warehouse or monitoring livestock on a farm. Accurate counts are paramount, and
GroundCountdelivers them without needing specialized, heavy hardware. - Environmental Monitoring: Drones could track wildlife populations, count specific plant species, or assess damage after a disaster, providing reliable numerical data for analysis.
- Search and Rescue: Counting individuals in a disaster zone or identifying the number of specific objects (e.g., life rafts) becomes far more reliable.
- Enhanced Autonomy: When a drone's decision-making system (its "brain") relies on accurate perception, it can make better, safer choices. If a VLM-powered drone needs to confirm
Nobjects are present before proceeding with a task,GroundCountensures thatNis correct. This is crucial for applications where the drone interacts with or reports on discrete entities. The ability to trust the numbers coming from a drone's vision system opens up a new realm of reliable autonomous tasks.
The Fine Print: Limitations & Next Steps
While GroundCount is a significant step forward, it's not a silver bullet. Understanding its boundaries is crucial for real-world deployment:
- VLM Compatibility: One VLM architecture (
Molmo2) actually saw degraded performance. The authors attribute this to "incompatibility between its iterative reflection mechanisms and structured prompts." This highlights that while the approach is broadly effective, some VLMs might need adjustments or be unsuitable. - ODM Dependence: The framework's accuracy is inherently tied to the performance of the underlying Object Detection Model. If the ODM fails to detect an object,
GroundCountwon't magically invent it. This means the choice and training of the ODM remain critical. - Positional Encoding Nuance: While beneficial for stronger models, positional encoding (the
(x,y)coordinates) was "detrimental for weaker ones." This suggests a need for careful tuning or an adaptive strategy based on the VLM's capabilities. - Real-world Edge Cases: The evaluation was on standard datasets (
COCO,PhD). Real-world drone deployments often involve rapidly changing lighting, occlusions, motion blur, and novel objects not seen during ODM training. HowGroundCounthandles these complex, dynamic environments at the edge needs further validation.
DIY: Counting on Your Drone
The beauty of GroundCount A is its relative simplicity for implementation. You don't need to retrain a massive VLM, which is a huge win for hobbyists and smaller development teams.
- Hardware: A decent edge AI processor capable of running an ODM (like
YOLOv8or evenYOLOv5on aJetson Orin NanoorRaspberry Pi 5with aCoral Edge TPU) and a VLM (many smaller VLMs can run on such hardware, or offload to a server) would be sufficient. The paper notes a 22% reduction in inference time for stronger models, which is excellent for edge deployment. - Software:
YOLOmodels are open-source and widely available. Many VLMs also have open-source versions or APIs. The key is the prompt engineering and the pipeline to convert ODM outputs to structured text. This part is entirely software-based and highly replicable for anyone comfortable with Python and basic NLP. - Open-Source Potential: While the specific
GroundCountcode isn't explicitly linked as open-source in the abstract, the method itself is well-described and relies on readily available components. This makes it highly feasible for hobbyists and developers to experiment with and integrate into their drone projects.
Building on Better Perception
This work doesn't exist in a vacuum. Reliable perception from GroundCount directly feeds into improving higher-level drone intelligence. For instance, more accurate object counts can significantly improve decision-making policies, as explored in papers like "PPGuide: Steering Diffusion Policies with Performance Predictive Guidance." If a drone's control policy is being guided by predicting its performance, having an accurate count of objects in its environment means better, more reliable predictions and safer actions. Furthermore, enabling such sophisticated VLM capabilities on a drone requires robust communication. Papers like "Exploiting Spatial Modulation for Strong PhaseNoise Mitigation in mmWave Massive MIMO" address the challenge of high-bandwidth, reliable data links crucial for transmitting complex VLM outputs, especially when off-board processing is involved. Finally, GroundCount bolsters the 'sensing' aspect of Integrated Sensing And Communication (ISAC) systems, which are becoming vital for drones. As "Distortion Is Not Noise: On the Limits of the Kappa Model for Monostatic ISAC" examines the nuances of sensing models, GroundCount ensures the VLM contribution to sensing is numerically precise, making ISAC applications more robust and reliable.
With GroundCount, drones are finally getting closer to truly understanding and accurately quantifying the world around them – a crucial step towards ubiquitous, reliable autonomous operations.
Paper Details
Title: GroundCount: Grounding Vision-Language Models with Object Detection for Mitigating Counting Hallucinations Authors: Boyuan Chen, Minghao Shao, Siddharth Garg, Ramesh Karri, Muhammad Shafique Published: March 2024 arXiv: 2603.10978 | PDF RELATED PAPERS: PPGuide: Steering Diffusion Policies with Performance Predictive Guidance, Exploiting Spatial Modulation for Strong PhaseNoise Mitigation in mmWave Massive MIMO, Distortion Is Not Noise: On the Limits of the Kappa Model for Monostatic ISAC
Written by
The Flight DeskSharing knowledge about drones and aerial technology.


