Putting a VLM Brain in Your Drone: Florence-2's ROS 2 Wrapper Unlocks Advanced Perception
A new ROS 2 wrapper makes Florence-2, a powerful multi-mode vision-language model, accessible for local execution on robotic systems. This integration simplifies deploying advanced semantic perception for drone tasks like object detection and captioning.

TL;DR: A new ROS 2 wrapper integrates Florence-2, a versatile vision-language model, enabling local, multi-modal semantic perception on robotic hardware. This means your drone can now "see" and "understand" its environment with rich detail, supporting tasks from object detection to captioning, all on consumer-grade GPUs.
Unlocking Semantic Superpowers for Your Drone
Drones are getting smarter, but true semantic understanding of their environment often remains stuck in the lab or the cloud. We're talking about systems that don't just detect an object, but can describe it, read text on it, or ground specific commands. The challenge has always been getting these large, complex "brain-like" vision-language models (VLMs) to run efficiently on compact, power-constrained drone hardware. This paper tackles that head-on, delivering a practical ROS 2 integration for Florence-2, a VLM capable of an impressive range of vision-language tasks, designed for local execution.
The Bottleneck of Narrow Vision
Current drone perception systems typically rely on specialized, narrow computer vision models. These are great for specific tasks like detecting power lines or identifying a landing pad. However, they lack generality. If you need to switch tasks—say, from recognizing a specific type of anomaly to reading a serial number—you often need to swap out or retrain entirely different models. This approach is costly in development time, computational resources, and memory footprint. Furthermore, offloading VLM inference to the cloud introduces latency and dependency on network connectivity, which is a non-starter for truly autonomous, real-time drone operations in remote or contested environments. The goal is a more unified, flexible perception system that runs on the drone itself, without breaking the bank or requiring a supercomputer.
How Florence-2 Gets a ROS 2 Upgrade
The core of this work is a ROS 2 wrapper that exposes Florence-2's capabilities through standardized ROS 2 interfaces. Florence-2 itself is a multi-mode VLM from Microsoft, notable for consolidating tasks like image captioning, optical character recognition (OCR), open-vocabulary object detection, and grounding into a single, comparatively lightweight model. The wrapper provides three interaction modes: continuous topic-driven processing for constant streams, synchronous service calls for on-demand queries, and asynchronous actions for longer-running tasks. This flexibility allows developers to choose the best integration strategy for their specific application.
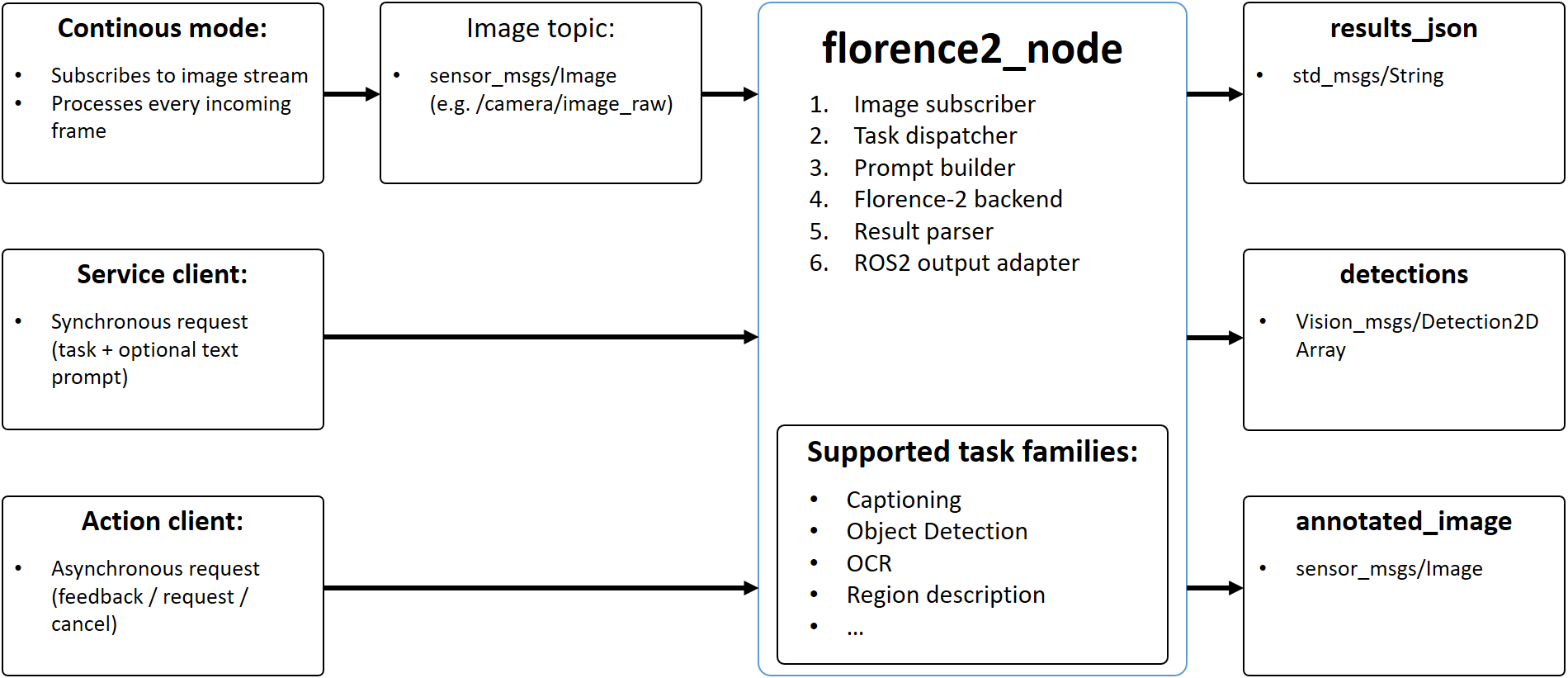 Figure 1: Architecture of the proposed Florence-2 ROS 2 wrapper. Diagram showing the main node, its ROS 2 interfaces, and the flow from image acquisition to model inference and result publication.
Figure 1: Architecture of the proposed Florence-2 ROS 2 wrapper. Diagram showing the main node, its ROS 2 interfaces, and the flow from image acquisition to model inference and result publication.
The wrapper processes incoming sensor_msgs/Image messages, passes them to the Florence-2 model for inference, and then publishes the results. Importantly, it leverages generic JSON outputs for versatility alongside standard ROS 2 message bindings for structured data like bounding box detections (vision_msgs/Detection2DArray). This hybrid approach offers both human-readable flexibility and machine-interpretable data for downstream drone autonomy systems. The entire setup is designed for local execution, supporting both native installation and Docker container deployment, simplifying integration into diverse robotic platforms.
Figure 2: [LOGO]
Performance on the Edge
The authors conducted functional validation and a throughput study across various NVIDIA GPUs. A key finding is that local deployment is indeed feasible on consumer-grade hardware, making this accessible for many hobbyists and smaller research labs.
Performance metrics on different GPUs:
NVIDIA RTX 3060 Laptop: Achieved inference speeds of 3.2 FPS for fullFlorence-2on600x600images.NVIDIA RTX 3070: Improved to 3.8 FPS.NVIDIA RTX 4090: Reached 8.3 FPS.
These numbers, while not 60 FPS for real-time video, are perfectly acceptable for many drone inspection, mapping, and semantic understanding tasks where a few frames per second of rich semantic data are more valuable than high frame rates of raw pixels. The model's unified nature means you get multiple perception modes (captioning, OCR, detection) from a single inference pass, which is a significant efficiency gain over running separate, specialized models.
Why This Matters for Your Drone Operations
This is a big step towards giving drones a more comprehensive understanding of their operational environment, moving beyond simple object recognition. Consider the possibilities:
- Intelligent Inspection: A drone could not only detect anomalies on a wind turbine but also read serial numbers or warning labels (
OCR), and describe the anomaly in natural language (captioning) to a human operator. This enriches inspection data significantly. - Advanced
Autonomous Navigation: Instead of just avoiding obstacles, a drone could understand the type of obstacle (open-vocabulary detection) or identify specific landmarks described by text prompts (grounding). For instance, "navigate to the generator labeled 'Unit B-7'." - Search and Rescue: A drone could scan a disaster zone, identify specific objects (e.g., "red backpack", "collapsed structure"), and provide semantic descriptions without prior training for those exact items.
- Swarm Robotics: With a shared semantic understanding, multiple drones in a
swarmcould collaborate on more complex tasks. One drone might caption a scene, while another usesOCRto read a sign, feeding into a shared task plan. This directly ties into concepts explored in related work like "Collaborative Task and Path Planning for Heterogeneous Robotic Teams using Multi-Agent PPO." - Human-Drone Interaction: Natural language commands could become far more sophisticated, allowing users to ask a drone to "find the blue truck with the broken headlight" rather than just "find a truck."
 Figure 3: AI-generated illustration
Figure 3: AI-generated illustration
The Current Gaps and Future Horizons
While promising, this integration isn't a silver bullet. There are practical limitations to consider:
- Computational Intensity: Even on consumer-grade
GPUs, Florence-2 is demanding. A3.2 FPSinference rate on a laptopRTX 3060is feasible for many tasks, but it's not suitable for high-speed, real-time control loops requiring millisecond-level latency. Integrating this on smaller, more power-constrained droneedge AIhardware (likeNVIDIA Jetsonplatforms) would require further optimization or model quantization, which isn't covered in depth here. - Model Size: Florence-2, while "comparatively manageable," is still a multi-billion parameter model. This means a significant memory footprint, which can be an issue for highly constrained drone platforms.
- Lack of
3DUnderstanding: The perception is primarily2Dimage-based. While it provides rich semantic information, it doesn't inherently offer3Dspatial understanding of the environment beyond what's derivable from2Dbounding boxes. For tasks like precise manipulation or complex3Dmapping, this would need to be augmented with other sensors or3Dperception techniques. Related work like "Open-Set Supervised 3D Anomaly Detection" highlights the need for3Dcontext in industrial applications. - Energy Consumption: Running a
VLMon a drone's onboardGPUwill significantly impact battery life. Optimizing the model for lower power consumption or exploring event-driven inference strategies will be crucial for extended flight times.
Building Your Own Intelligent Drone
This is where the paper shines for our audience. The entire ROS 2 wrapper is open-source and publicly available on GitHub. This means a hobbyist or researcher with some ROS 2 experience and access to an NVIDIA GPU (even a desktop one for development) can get this up and running relatively easily. The support for Docker containers further simplifies environment setup, abstracting away dependency hell. You'd need a drone platform capable of streaming ROS 2 image topics (e.g., using a companion computer like an NVIDIA Jetson Orin Nano or even a small x86 board with an eGPU if you're building a larger drone). The authors' focus on local execution and consumer-grade GPU feasibility makes this a very tangible project for those looking to push the boundaries of drone intelligence.
The Broader AI Landscape for Drones
The immediate practicality of this Florence-2 integration opens doors for several advanced drone capabilities. For instance, while Florence-2 provides robust 2D semantic understanding, integrating it with depth perception is key for true 3D awareness. "Lightweight Prompt-Guided CLIP Adaptation for Monocular Depth Estimation" by Ahani Manghotay and Liang is a perfect complement here, showing how other VLMs like CLIP can be optimized for essential drone perception tasks, such as lightweight monocular depth estimation. This suggests a future where Florence-2 handles 2D semantics, and an adapted CLIP provides efficient depth, both running on edge AI hardware.
Beyond individual drone perception, this technology enables more sophisticated multi-robot missions. If drones can "understand" their environment better with VLMs, they can participate in more complex, collaborative tasks. This leads directly to the work by Rubio, Richter, Kolvenbach et al. on "Collaborative Task and Path Planning for Heterogeneous Robotic Teams using Multi-Agent PPO." Their research demonstrates how heterogeneous robotic teams—which could now include VLM-enhanced drones—can perform advanced task and path planning, directly relating to swarm drones and autonomous navigation applications.
Finally, the enhanced semantic understanding from Florence-2 has direct implications for industrial applications. "Open-Set Supervised 3D Anomaly Detection: An Industrial Dataset and a Generalisable Framework for Unknown Defects" by Liang et al. showcases a powerful application area for VLM-enhanced drones: industrial inspection and anomaly detection. Drones equipped with advanced vision-language understanding could provide richer semantic context to identify and categorize unknown defects in complex 3D environments, extending their utility beyond basic visual checks and showcasing a real-world impact of the main paper's technology.
The Future of Onboard Intelligence
This ROS 2 wrapper for Florence-2 isn't just another research paper; it's a practical blueprint for embedding sophisticated vision-language intelligence directly into your drone, paving the way for truly adaptive and semantically aware autonomous systems.
Paper Details
Title: A ROS 2 Wrapper for Florence-2: Multi-Mode Local Vision-Language Inference for Robotic Systems Authors: J. E. Domínguez-Vidal Published: April 2026 arXiv: 2604.01179 | PDF
Written by
The Flight DeskSharing knowledge about drones and aerial technology.


