Drone's New Eye: VLMs Rate Photo Quality Like Humans
New research shows Vision-Language Models can assess image quality (colorfulness, contrast, preference) with high human alignment, promising smarter drone photography and data collection.
TL;DR: Vision-Language Models (VLMs) are now capable of assessing image quality attributes such as colorfulness, contrast, and overall preference, closely mirroring human perception with strong alignment in some areas. This development paves the way for drones to autonomously evaluate and optimize their captured imagery, shifting from mere data collection to understanding visual fidelity.
Giving Drones a Perceptual Edge
Your drone isn't just a flying camera anymore. What if it could tell if the photo it just took was actually good? Not just in focus or properly exposed, but perceptually pleasing, vibrant, and well-contrasted? New research dives into this exact question, exploring whether advanced AI — specifically Vision-Language Models (VLMs) — can develop an "eye for quality" that rivals human judgment. This isn't about making pretty pictures for Instagram; it's about enabling autonomous systems to make intelligent decisions about the data they collect.
The Cost of Human Eyes
Currently, assessing image quality, especially in a nuanced, perceptual way, relies heavily on human evaluators. Psychophysical experiments, where people compare images, remain the gold standard. But they're slow, expensive, and don't scale well for the sheer volume of data drones can generate. Consider a drone conducting an infrastructure inspection, capturing thousands of images. Manually reviewing each one for optimal contrast or vibrant color is simply impractical. Traditional automated metrics often fall short because they don't always align with how humans actually perceive quality. What's needed is a system that can efficiently approximate human judgment, ideally right on the drone or in the field, reducing post-processing load and improving data utility.
How AI Learns to See "Good"
The researchers benchmarked six different VLMs – four proprietary and two open-weight models – against extensive human psychophysical data. The central idea was to determine if a VLM, trained on vast amounts of image and text data, could "understand" and rate image quality attributes in a way that correlates strongly with human perception. They focused on three key quality scales: contrast, colorfulness, and overall preference.
The process involved feeding both human evaluators and VLMs identical image pairs and asking them to compare quality. For humans, this meant direct pairwise comparisons. For VLMs, it’s prompt-based, asking questions like "Which image has better contrast?" or "Which image do you prefer?". Responses from both sources were then standardized and filtered to create a unified dataset for comparison.
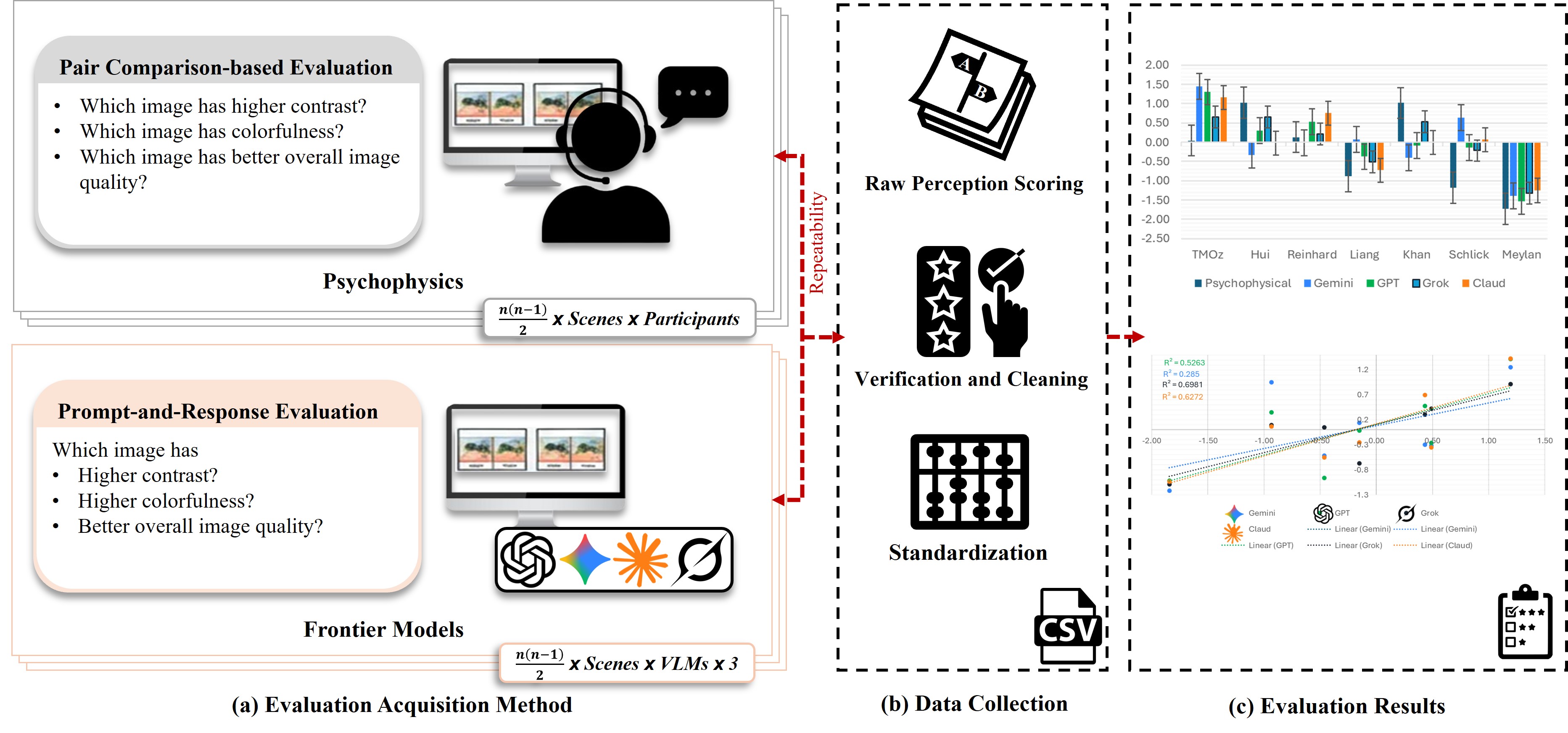 Figure 1: Workflow for comparing perceptual IQA between human observers and VLMs. (a) Evaluation acquisition: Human psychophysical data are obtained through pairwise comparisons, while VLM assessments are collected via prompt-based image comparisons using an identical query. (b) Data processing: Responses from both sources undergo repeatability filtering, verification, and score standardization to produce a unified evaluation dataset. (c) Evaluation results: Standardized human and VLM scores are compared to quantify model–human alignment, revealing attribute-dependent performance and varying agreement with the psychophysical baseline.
Figure 1: Workflow for comparing perceptual IQA between human observers and VLMs. (a) Evaluation acquisition: Human psychophysical data are obtained through pairwise comparisons, while VLM assessments are collected via prompt-based image comparisons using an identical query. (b) Data processing: Responses from both sources undergo repeatability filtering, verification, and score standardization to produce a unified evaluation dataset. (c) Evaluation results: Standardized human and VLM scores are compared to quantify model–human alignment, revealing attribute-dependent performance and varying agreement with the psychophysical baseline.
This systematic approach enabled the team to quantify VLM-human alignment using metrics like Spearman’s rank correlation coefficient (ρ), providing a clear picture of how well these models mimic human perception.
The Numbers on Perception
The findings reveal both strengths and weaknesses in current VLMs:
- High Alignment for Colorfulness: Some VLMs showed strong human alignment for colorfulness, with Spearman's ρ reaching up to 0.93. This indicates they are adept at identifying which images humans would consider more colorful.
- Variable Performance: Contrast assessment presented a different challenge. Models that excelled at colorfulness often underperformed on contrast, and vice-versa. This suggests an attribute-dependent variability, meaning no single VLM is yet a universal expert across all quality dimensions.
- Preference Weighting Matches Humans: When evaluating overall preference, most VLMs, similar to human observers, assigned higher weights to colorfulness compared to contrast. This points to a shared perceptual bias for vibrant imagery.
- Consistency vs. Alignment Trade-off: Counterintuitively, the models most consistent in their own judgments weren't necessarily the most human-aligned. This suggests that some "response variability" in VLMs might actually reflect a sensitivity to scene-dependent perceptual cues, much like humans adapt their judgment based on context.
- Clearer Differences, Better Agreement: Human-VLM agreement improved significantly with perceptual separability. In simpler terms, when the difference in quality between two images was clear and obvious, VLMs were much more reliable. Subtle differences proved harder for them to consistently match human judgment.
 Figure 2: Attribute weighting for overall preference. The x-axis represents the contrast weight (α) and the y-axis represents the colorfulness weight (β).
Figure 2: Attribute weighting for overall preference. The x-axis represents the contrast weight (α) and the y-axis represents the colorfulness weight (β).
Smarter Drones, Better Data
This research opens up significant opportunities for autonomous drone operations.
- Smart Autonomous Photography: Consider a drone capturing aerial photos for real estate. Instead of blindly snapping shots, it could use an onboard VLM to evaluate image quality in real-time. If a photo lacks sufficient contrast or colorfulness according to the VLM's human-aligned perception, the drone could automatically adjust camera settings, re-position, or retake the shot until optimal quality is achieved.
- Efficient Data Collection: For tasks like agricultural monitoring or infrastructure inspection, a drone could prioritize capturing high-quality data points, ensuring critical visual information isn't compromised by poor lighting or atmospheric conditions. This reduces the need for expensive post-processing and manual review.
- Enhanced SLAM and Navigation: While not directly about navigation, understanding visual quality could indirectly benefit visual SLAM (Simultaneous Localization and Mapping). Cleaner, perceptually "better" images might lead to more robust feature extraction and more accurate pose estimation, especially in challenging visual environments.
- Adaptive Mission Planning: A drone could dynamically alter its flight path or mission parameters based on real-time image quality feedback. For instance, if a specific area consistently yields low-contrast images, the drone could be programmed to fly closer, adjust lighting, or even flag the area for a return visit under different conditions.
Here are examples of images with varying quality attributes that VLMs could learn to differentiate:
 (a) Example image.
(a) Example image.
 (b) Another example image.
(b) Another example image.
 (c) A third example image.
(c) A third example image.
The Road Ahead for Drone Vision
While promising, this research also highlights several areas needing further development:
- Attribute Specialization: The strong attribute-dependent variability (good at colorfulness, bad at contrast, or vice-versa) means we don't yet have a single "generalist" VLM for IQA. Deploying this would likely require specialized models or more complex ensembles.
- Computational Overhead: Running sophisticated VLMs, especially proprietary ones, on a drone's edge hardware can be computationally intensive, impacting power consumption and potentially real-time performance. Mini drones, in particular, have strict weight and power budgets.
- Limited Attributes: The study focused on contrast, colorfulness, and overall preference. Real-world image quality involves many more factors like sharpness, noise, distortion, dynamic range, and semantic relevance. Future work needs to expand this scope.
- Perceptual Separability: The finding that VLMs perform better with clearly expressed stimulus differences implies that for subtle quality variations, they might still struggle to match human nuance. This could be problematic for applications requiring very fine-grained quality control.
- Real-world Robustness: The study was conducted in a controlled environment. How these VLMs perform in diverse, unpredictable drone environments (varying weather, lighting, motion blur, atmospheric haze) remains to be thoroughly tested.
Building Your Own Quality Eye?
Replicating this research directly might be challenging for a hobbyist due to the reliance on proprietary VLMs and the need for extensive psychophysical datasets. However, the two open-weight models benchmarked (likely CLIP or similar architectures) offer a starting point. An advanced hobbyist could experiment with fine-tuning open-source VLMs like CLIP or LLaVA on smaller, custom image quality datasets. Integrating such a VLM onto a Raspberry Pi or a Jetson Nano on a drone would require significant optimization for edge inference, but the underlying concept is approachable for dedicated builders.
This work also complements other VLM applications. For instance, VFIG: Vectorizing Complex Figures in SVG demonstrates how VLMs can transform visual data into editable formats. A drone not only assessing quality but also intelligently vectorizing captured architectural details would be a powerful tool for survey applications. Similarly, CliPPER: Contextual Video-Language Pretraining highlights VLMs' potential for event recognition in long-form video. Combine that with quality assessment, and a drone could autonomously identify critical events and ensure the captured footage is of optimal viewing quality. And for the drone's own perception, EndoVGGT: GNN-Enhanced Depth Estimation addresses robust 3D reconstruction, a critical component for autonomous navigation where high-quality input imagery (validated by a VLM perhaps) could further improve performance in challenging low-texture or occluded scenes.
The Future of Autonomous Vision
Integrating human-aligned image quality assessment into drone platforms is more than a technical novelty; it's a significant step towards truly intelligent autonomous systems. These systems will not only see the world but also understand and optimize how they see it, fundamentally changing how we collect and use aerial data.
Paper Details
Title: Vision-Language Models vs Human: Perceptual Image Quality Assessment Authors: Imran Mehmood, Imad Ali Shah, Ming Ronnier Luo, Brian Deegan Published: March 26, 2024 arXiv: 2603.24578 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.