Drones Get Hands-On: Mastering 6-DOF Object Manipulation in 3D
A new multimodal transformer, GMT, is enabling robots to synthesize incredibly precise 6-DOF object manipulation trajectories in complex 3D scenes, outperforming current human motion baselines. This pushes drones towards active interaction, not just observation.
TL;DR: Researchers have developed GMT, a multimodal transformer that allows robots, including future drones, to generate highly accurate and physically feasible 6-DOF (six degrees of freedom) trajectories for manipulating objects in complex 3D environments. It combines geometric, semantic, and contextual information to plan efficient, collision-free movements, marking a significant step towards truly autonomous drone interaction.
Beyond Just Flying: Drones That 'Do'
Drones are fantastic at flying, but what about doing? Moving beyond simple flight paths to intricate object interaction in a cluttered 3D world is the next frontier. Forget just observing a scene; imagine a drone actively picking up, placing, or assembling components with the precision of a surgeon. This isn't just about navigating; it's about doing. This research introduces GMT, a system designed to plan these complex, goal-conditioned object manipulation trajectories in full 6-DOF.
The Real Challenge: Precise Interaction in 3D
Achieving this level of interaction is a massive challenge. Current approaches often fall short because they rely on limited 2D representations or partial 3D data. This restricts their ability to grasp the full geometry of a scene, leading to imprecise trajectories and frequent collisions. For a drone, this means less reliable operation, wasted energy from inefficient movements, and a higher risk of damaging itself or its surroundings. To generate truly intelligent and safe manipulation paths, a system is needed that can understand the entire 3D context, from object shapes to semantic labels.
GMT's Secret Sauce: Crafting Intelligent Trajectories
GMT tackles this by integrating multiple data streams into a multimodal transformer framework. It doesn't just look at one aspect of a scene; it fuses 3D bounding box geometry, dense point cloud context, semantic object categories, and the target end-pose. This rich input allows it to build a comprehensive understanding of the environment and the desired interaction.
The core idea is to represent trajectories as continuous 6-DOF pose sequences, rather than discrete steps. GMT uses a sophisticated conditioning strategy to weave together geometric, semantic, contextual, and goal-oriented information. This multimodal input is processed by a transformer that prioritizes geometric feasibility before applying semantic preferences. The fused latent representation then directly feeds a prediction head, which the authors found more stable for long-horizon control than traditional decoding stages. This integrated approach ensures that generated trajectories are not only goal-directed but also physically plausible and collision-free.
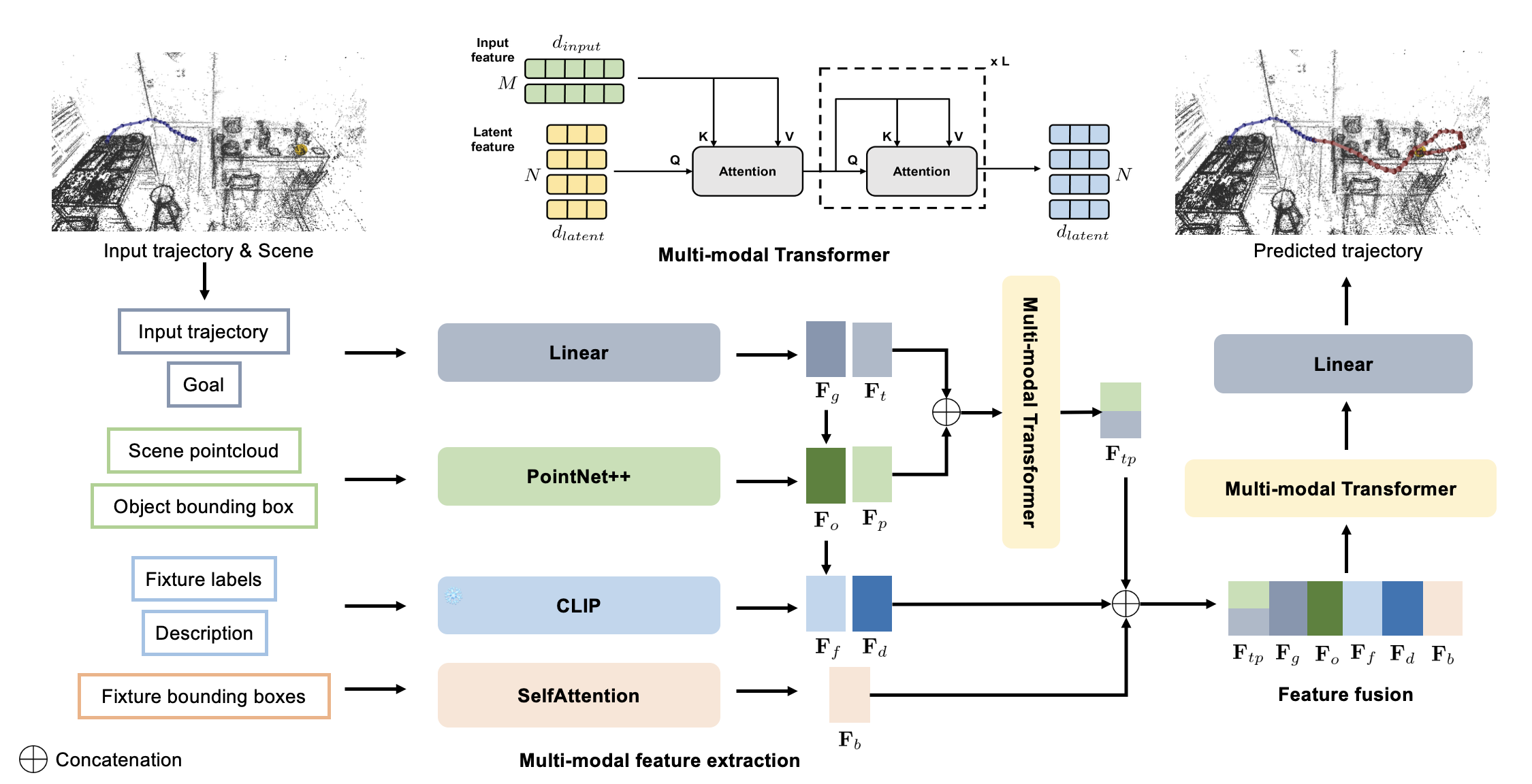 Figure 2: Pipeline overview. GMT encodes trajectory dynamics, local geometry from point clouds, semantic fixture boxes, natural language action descriptions, and a goal descriptor. A multimodal transformer fuses this information for 6-DOF trajectory prediction.
Figure 2: Pipeline overview. GMT encodes trajectory dynamics, local geometry from point clouds, semantic fixture boxes, natural language action descriptions, and a goal descriptor. A multimodal transformer fuses this information for 6-DOF trajectory prediction.
The pipeline is quite robust. For instance, to accurately localize small objects in cluttered scenes, it reconstructs 3D bounding boxes from monocular depth estimation and SLAM data, aligning and scaling them for precision. This is critical for any drone tasked with fine-grained manipulation.
 Figure 5: 3D bounding box reconstruction in the HD-EPIC dataset. This pipeline allows for accurate localization of small objects in complex scenes, a vital capability for precise object interaction.
Figure 5: 3D bounding box reconstruction in the HD-EPIC dataset. This pipeline allows for accurate localization of small objects in complex scenes, a vital capability for precise object interaction.
GMT Takes Flight: Outperforming the Competition
GMT isn't just a theoretical construct; it delivers tangible improvements. The paper details extensive experiments on both synthetic and real-world benchmarks, demonstrating significant gains over state-of-the-art human motion and human-object interaction baselines like CHOIS and GIMO.
Here’s what stands out:
- Spatial Accuracy: GMT achieves substantial gains in accurately placing and orienting objects.
- Orientation Control: The model demonstrates superior control over object orientation throughout the trajectory, a critical factor for successful manipulation.
- Efficiency: Generated trajectories are often shorter and more efficient than natural human motions, which means less energy consumption and faster task completion for a drone.
- Collision Avoidance: Unlike baselines, GMT consistently produces trajectories that avoid collisions while still reaching the target.
- Generalization: The system shows strong generalization capabilities across diverse objects and cluttered 3D environments.
For example, on the ADT dataset, GMT's trajectories successfully reach the target while avoiding obstacles and are often shorter than the ground truth. Competing models like Adaptive GIMO struggled without gaze information, and CHOIS accumulated errors, leading to failure. Similar results were seen on the HD-EPIC dataset, where baselines got stuck in repetitive motions while GMT generated efficient, goal-directed paths.
 Figure 3: Qualitative results on the ADT dataset. GMT (red) consistently produces collision-free, goal-reaching trajectories that are shorter than the natural human motion (black), outperforming baselines.
Figure 3: Qualitative results on the ADT dataset. GMT (red) consistently produces collision-free, goal-reaching trajectories that are shorter than the natural human motion (black), outperforming baselines.
Why This Matters for Drones
This is a big deal for advanced drone applications. Consider autonomous inspection drones that need to interact with infrastructure, not just fly past it. A drone equipped with a manipulator could use GMT to:
- Precision Assembly: Pick up and place components with millimeter accuracy in manufacturing or construction.
- Complex Maintenance: Perform delicate repairs on remote equipment, like tightening a bolt or connecting a wire, requiring exact 6-DOF positioning.
- Hazardous Material Handling: Manipulate dangerous objects without human intervention, planning safe paths around obstacles and achieving precise grips.
- Environmental Sampling: Collect specific samples from hard-to-reach locations, requiring careful trajectory planning to avoid disturbing the environment.
This moves drones from being purely observational or transport platforms to active, intelligent manipulators. It opens the door for drones to perform truly surgical tasks in 3D space, interacting with their environment in ways previously limited to ground robots or human operators.
The Roadblocks Ahead
While GMT is impressive, it's not without its limitations, and being aware of these is crucial for real-world deployment.
- Overshooting and Redundant Motion: The authors acknowledge that sometimes, generated trajectories can be longer than necessary or overshoot the destination, particularly with small object trajectories that don't have significant positional changes. This could lead to wasted energy or slower task completion.
- Short Duration Interactions: For very short interaction durations, the model can sometimes introduce redundant motion. This suggests areas for refinement in how it handles minimal movements.
- Real-world Physics and Dynamics: While the model focuses on geometric feasibility, integrating real-time physics simulation and external forces (like wind for a drone) into the planning loop would be essential for truly robust outdoor or dynamic scenarios. The current model's
6-DOFrefers to object pose, not necessarily the full dynamics of a drone manipulating it. - Hardware Integration: Deploying this on an actual drone requires robust hardware – manipulators, high-fidelity sensors (LiDAR, stereo cameras), and significant onboard computing power for the transformer model. The current work focuses on the planning algorithm, not the physical execution.
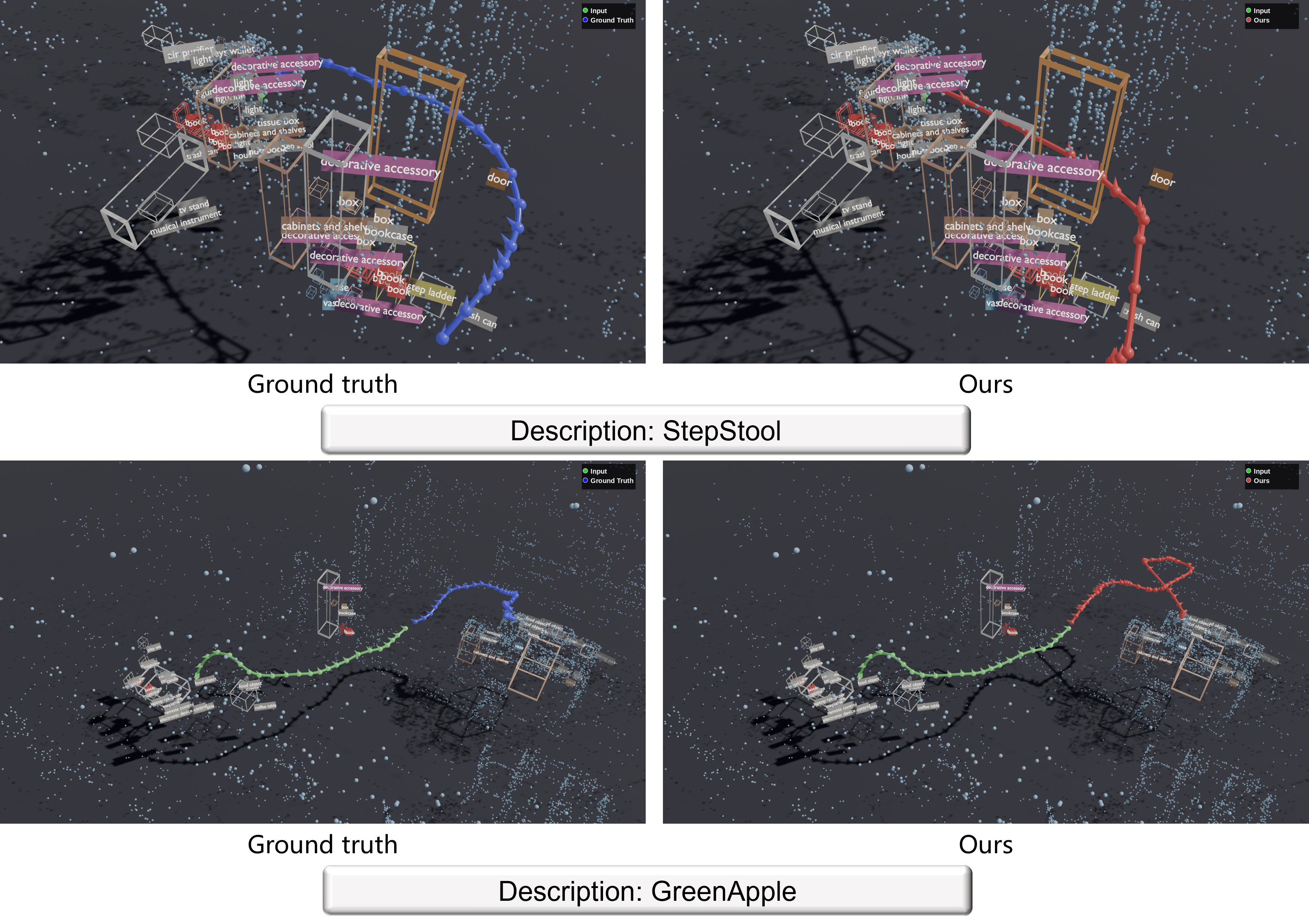 Figure 9: Failure Cases in the ADT dataset. Despite being goal-conditioned, generated trajectories can sometimes be longer than the ground truth or overshoot the target.
Figure 9: Failure Cases in the ADT dataset. Despite being goal-conditioned, generated trajectories can sometimes be longer than the ground truth or overshoot the target.
Building It Yourself: Hobbyist Feasibility
Replicating GMT from scratch as a hobbyist would be a substantial undertaking. The model relies on complex multimodal transformer architectures and extensive datasets for training. While the underlying concepts are accessible, the computational resources and deep learning expertise required for training are significant.
However, if the authors release pre-trained models or a well-documented framework, integrating it into a sophisticated ROS-based drone platform with a robotic arm could become more feasible for advanced builders. You'd need a drone capable of carrying a manipulator, precise SLAM capabilities for 3D scene reconstruction, and an onboard companion computer with a powerful GPU (like an NVIDIA Jetson Orin) to run the inference efficiently. The project page (https://huajian-zeng.github.io/projects/gmt/) might offer more insights into potential open-source releases.
The Broader Research Landscape
The push for more intelligent, context-aware robotics is clear across the research landscape. For GMT to operate effectively on a drone, robust perception is non-negotiable. This is where work like "Feeling the Space: Egomotion-Aware Video Representation for Efficient and Accurate 3D Scene Understanding" comes in. It offers a solution for multimodal large language models (MLLMs) to achieve accurate 3D scene understanding without the heavy computational cost of traditional 3D representations. This approach for efficient egomotion-aware video processing could be key to feeding GMT the necessary real-time scene context from a drone's perspective, without bogging down its limited onboard processing.
Furthermore, as drones take on more critical manipulation tasks, safety becomes paramount. "Specification-Aware Distribution Shaping for Robotics Foundation Models" addresses this by providing a framework to build formal guarantees into robotics models. This means ensuring that GMT-powered manipulation adheres to strict safety protocols and operational specifications, which is vital for trust and adoption in sensitive applications. Without such guarantees, even the most precise trajectory planning is a liability.
Finally, integrating GMT on an edge device like a drone demands efficiency. "Unified Spatio-Temporal Token Scoring for Efficient Video VLMs" directly tackles this by improving the computational efficiency of video-based vision-language models through token pruning. This kind of optimization could make the real-time, multimodal scene understanding and goal-conditioned planning required by GMT practical for on-board drone processing, extending flight time and sharpening response times in dynamic environments.
The Next Frontier
GMT represents a significant leap towards truly autonomous, dexterous drones. The challenge now is to bridge the gap between impressive simulation results and robust, safe real-world deployment, integrating advanced perception and efficiency optimizations to bring these capabilities to the skies.
Paper Details
Title: GMT: Goal-Conditioned Multimodal Transformer for 6-DOF Object Trajectory Synthesis in 3D Scenes Authors: Huajian Zeng, Abhishek Saroha, Daniel Cremers, Xi Wang Published: March 27, 2026 arXiv: 2603.17993 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.