Drones That Remember: Building a Persistent 3D World Map from a Single Camera
Researchers have developed a method for drones to generate a dynamic, 3D world scene graph from monocular video, enabling them to track objects and their relationships even when occluded or out of view. This advances autonomous systems.
TL;DR: Drones can now build a persistent, 3D "world scene graph" from a single camera, remembering objects and their relationships even when out of sight. This creates a dynamic, relational mental map of their environment, paving the way for advanced autonomy.
Beyond the Drone's Blinkered View
For years, drones have excelled at seeing—capturing stunning visuals, mapping environments, and navigating complex spaces. Yet, their "understanding" of the world often remains superficial, a series of instantaneous snapshots. What if a drone could do more than just see? What if it could form a persistent, evolving mental model of its surroundings, knowing where objects are even when out of sight, and understanding how they interact? The paper, "Towards Spatio-Temporal World Scene Graph Generation from Monocular Videos," presents a significant shift in how drones perceive and reason about their world.
The Problem with Short-Term Memory
Current drone vision systems typically operate with what the authors term a "frame-centric" view. They process only what's currently visible in the camera frame, usually in 2D. This approach has clear limitations: when an object moves behind another, or the drone flies past it, that object effectively vanishes from the drone's perception system. Its relationships with other objects are discarded, and its 3D location is lost. This leads to a fragmented, short-term understanding of the environment, making tasks requiring long-term planning, object persistence, or complex interaction understanding incredibly difficult. For a drone to truly operate autonomously in dynamic, real-world scenarios—such as package delivery in a bustling city or intricate inspection of a power plant—it needs a far more robust and persistent form of scene understanding.
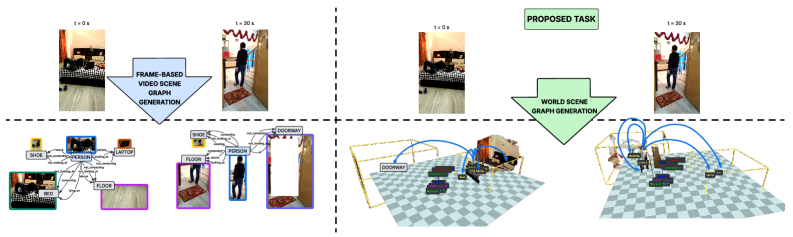 Figure 5: Unlike traditional Video Scene Graph Generation (left) that focuses on the instantaneous camera view, World Scene Graph Generation (right) maintains a persistent 3D understanding of all objects, even when unobserved.
Figure 5: Unlike traditional Video Scene Graph Generation (left) that focuses on the instantaneous camera view, World Scene Graph Generation (right) maintains a persistent 3D understanding of all objects, even when unobserved.
Building a World in the Machine's Mind
The core idea is World Scene Graph Generation (WSGG). Instead of a fleeting 2D understanding, WSGG aims to build a comprehensive, global 3D scene graph that persists over time. This graph represents every interacting object in the environment with a 3D oriented bounding box (OBB), tracking their locations and relationships regardless of whether they are currently visible to the camera. Here, the drone isn't just seeing; it's remembering and inferring.
To achieve this, the researchers first developed ActionGenome4D, a new dataset that upgrades existing Action Genome videos into 4D scenes. This involved sophisticated feed-forward 3D reconstruction, generating world-frame OBBs for every object, and dense relationship annotations—crucially, even for objects that are temporarily occluded or out of view. This dataset forms the foundation for training robust 3D world models.
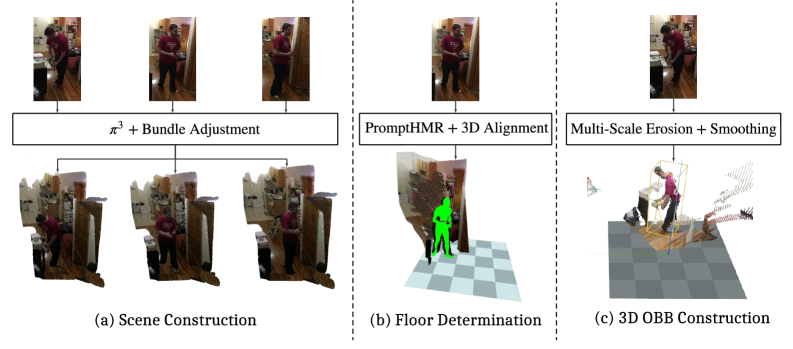 Figure 2: The pipeline for constructing the
Figure 2: The pipeline for constructing the ActionGenome4D dataset, transforming 2D videos into persistent 3D object annotations.
The paper proposes three complementary methods to address the critical challenge of reasoning about unobserved objects:
- PWG (Persistent World Graph): This method implements object permanence using a zero-order feature buffer. It maintains a "last-known-state" memory for objects that go out of view, propagating their historical features based on how long they've been unobserved.
- MWAE (Masked World Auto-Encoder): This reframes the problem of unobserved objects as a masked completion task. It strategically masks out visual streams for occluded objects and uses a cross-view associative retrieval mechanism to reconstruct their missing features, effectively filling in the blanks.
- 4DST (4D Scene Transformer): This more advanced approach replaces the static buffer with a differentiable, per-object temporal attention mechanism. It enriches this attention with 3D motion and camera-pose features, allowing for more dynamic and context-aware persistence of object information.
These methods, detailed in Figure 3, demonstrate different inductive biases for handling the crucial problem of objects leaving the camera's field of view.
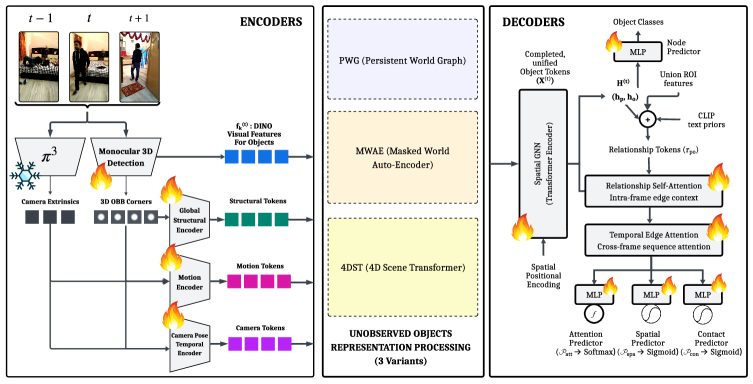 Figure 3: An overview of the three methods (PWG, MWAE, 4DST) developed to handle unobserved objects and maintain object permanence within the world scene graph.
Figure 3: An overview of the three methods (PWG, MWAE, 4DST) developed to handle unobserved objects and maintain object permanence within the world scene graph.
The full pipeline, as seen in Figure 9, integrates multi-modal inputs such as DINO visual features, monocular 3D geometries, and camera extrinsics. These are encoded into structural, motion, and ego-pose tokens, then fused with buffered memory features to address occlusions. A spatial GNN and relationship decoders then process the final unified tokens to predict object categories and their dynamic relationships over time.
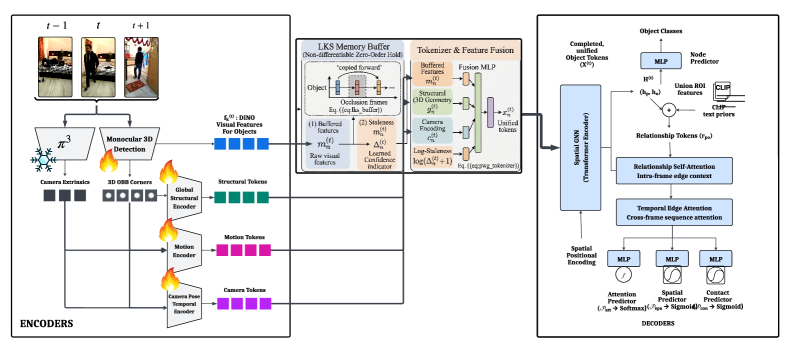 Figure 9: The complete
Figure 9: The complete WorldSGG framework, detailing the processing of multi-modal inputs, feature fusion, and the generation of node categories and scene graph relationships.
Furthermore, the authors integrate advanced Vision-Language Models (VLMs) into the WSGG task using Graph RAG-based approaches. This enables sophisticated, unlocalized relationship prediction, where the VLM can infer connections between objects even when their visual data is sparse or absent. This is a critical component for building semantic understanding, moving beyond simple geometric relationships.
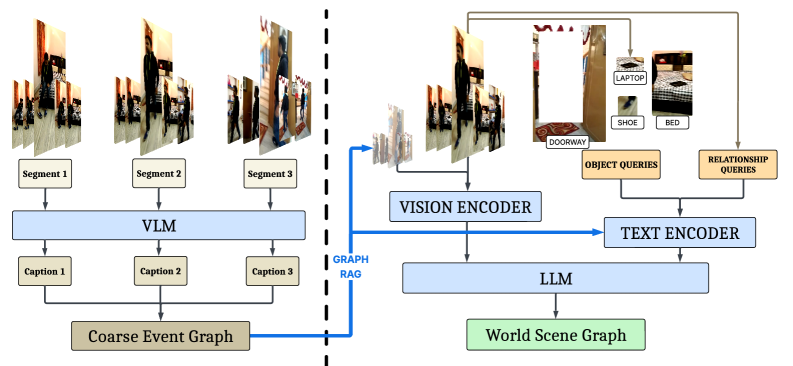 Figure 4: The Graph
Figure 4: The Graph RAG inference pipeline, leveraging Vision-Language Models to construct both coarse event graphs and fine-grained world scene graphs, enriching predictions with global contextual priors.
Hard Numbers and New Baselines
While specific numerical results detailing absolute accuracy gains over traditional methods would require a deeper dive into the paper's tables, the abstract clearly states that WSGG "advances video scene understanding toward world-centric, temporally persistent, and interpretable scene reasoning." The authors establish strong baselines for unlocalized relationship prediction using their Graph RAG-based approaches. This marks a fundamental shift in evaluation metrics: moving beyond just detecting what's visible, to accurately localizing and predicting relationships for all objects in the scene, observed or not. The focus is on consistency and completeness of the world model, a significant departure from previous frame-by-frame evaluations.
Why This Matters for Your Drone
This research opens new possibilities for drone autonomy and decision-making. Here’s why it matters:
- True Autonomous Navigation: Drones can remember obstacles behind corners, track dynamic entities (like people or vehicles) as they move in and out of view, and avoid collisions based on a persistent understanding of their environment, not just immediate sensor readings.
- Intelligent Interaction: For drones operating alongside humans, understanding the context of human actions and object interactions is crucial. A drone could predict where a person is going, what they're trying to do, and assist proactively, even if the person briefly steps out of sight.
- Long-Term Mission Planning: Consider an inspection drone that needs to monitor changes over days or weeks. With
WSGG, it maintains a consistent model of the facility, identifying subtle shifts in object positions or states, rather than re-learning the scene every time. - Enhanced Search and Rescue: A drone could build a comprehensive map of a disaster site, keeping track of potential victims or hazards even if they become obscured by debris or smoke, significantly improving efficiency.
- Robotics Manipulation: For drones equipped with manipulation capabilities, knowing the precise 3D location of an object, even if it's currently occluded, is essential for planning grasping and manipulation tasks.
This isn't just about better object detection; it's about building a drone that understands its environment, enabling a new class of intelligent aerial robots.
Limitations and What's Still Missing
While the concept is exciting, it's important to be pragmatic about current limitations:
- Data Source Constraints: The
ActionGenome4Ddataset is constructed by upgrading 2D videos into 4D scenes. While impressive, this is still a synthetic 4D representation, not a true real-world 4D capture. Real-world 4D data with ground truth for occluded objects is incredibly hard to acquire and remains a challenge. - Monocular Input Inheritances: Relying solely on monocular video, while efficient, means inherent ambiguities in depth and geometry. While the reconstruction methods are robust, a single camera can only infer so much. Integrating stereo vision or
LiDARcould significantly enhance robustness in complex real-world scenarios. - Computational Overhead: Building and maintaining a persistent 3D scene graph with object permanence and relationship prediction is computationally intensive. Deploying this in real-time on resource-constrained mini-drones will require significant optimization or powerful edge
AIhardware. - Generalization Beyond Human Actions: The
ActionGenomedataset focuses on human actions. While the methodology is general, its robustness in diverse environments—like outdoor industrial settings, dense forests, or fast-moving traffic—needs further validation. - Dynamic Environments and Scale: How well does the system handle highly dynamic environments with many moving objects or scale to very large outdoor areas? The current scope seems more suited to confined, human-centric spaces.
DIY Feasibility: Not Yet for the Garage
Replicating this research in a hobbyist workshop is currently a significant undertaking. The development of the ActionGenome4D dataset alone requires specialized 3D reconstruction pipelines and extensive annotation efforts. The models themselves, involving complex Transformer architectures and GNNs, demand substantial GPU resources for training. While underlying machine learning frameworks like PyTorch or TensorFlow are open-source, the specific code and pre-trained models for WSGG would need to be publicly released and well-documented for broader adoption. For now, this remains firmly in the realm of advanced research labs, but it sets a clear direction for future open-source tools.
This work represents a fundamental step towards drones that don't just react to their immediate surroundings but genuinely understand and remember their world. The challenge of maintaining a consistent world model when parts of the environment are unobserved is an active area of research. For instance, "Out of Sight, Out of Mind? Evaluating State Evolution in Video World Models" by Ma et al. directly addresses the stability of world models in such scenarios, highlighting the importance of the solutions proposed in the WSGG paper. Furthermore, foundational machine learning techniques required to model and predict object evolution, as explored in "Representation Learning for Spatiotemporal Physical Systems" by Qu et al., provide the underlying science that WSGG applies. While this paper focuses on high-level scene graphs, a drone still benefits from immediate, low-level environmental understanding. Research like "Panoramic Multimodal Semantic Occupancy Prediction for Quadruped Robots" by Zhao et al., which focuses on generating detailed 360° semantic occupancy maps, could complement WSGG by providing the robust, real-time spatial awareness needed for safe, immediate navigation.
This research brings us closer to drones that don't just fly through the world, but truly comprehend it.
Paper Details
Title: Towards Spatio-Temporal World Scene Graph Generation from Monocular Videos Authors: Rohith Peddi, Saurabh, Shravan Shanmugam, Likhitha Pallapothula, Yu Xiang, Parag Singla, Vibhav Gogate Published: March 18, 2024 (arXiv v1) arXiv: 2603.13185 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.