Drones That See the Future: ThinkJEPA's Dual AI Approach
ThinkJEPA combines dense, fine-grained motion prediction with long-horizon semantic reasoning, allowing drones to predict future world states and make proactive decisions.
TL;DR: ThinkJEPA is a new AI framework that merges two powerful prediction methods: one for detailed, immediate motion and another for understanding long-term semantic context. This fusion helps autonomous systems, like drones, forecast complex future events more accurately than previous methods, shifting from reactive to truly proactive decision-making.
Beyond Reactive Flight: Drones That 'Think' Ahead
The dream of truly autonomous drones isn't just about avoiding obstacles or following a GPS path. It's about proactive intelligence – a drone that can anticipate events, understand intentions, and make smart decisions before something happens. This isn't science fiction anymore. A new paper, "ThinkJEPA: Empowering Latent World Models with Large Vision-Language Reasoning Model," marks a significant stride towards giving our drones exactly that kind of foresight.
This research introduces an AI architecture that essentially lets a drone "see into the future" by combining two distinct but complementary ways of understanding its environment. It's a clear departure from purely reactive systems, paving the way for more robust and intelligent drone operations.
The Limits of Short-Sighted AI
Current approaches to predicting future drone states often fall into one of two camps, each with its own significant drawbacks. On one side, we have latent world models like V-JEPA2. These are excellent at making dense, fine-grained predictions from short video observations. They can extrapolate local motion with impressive detail, which is crucial for immediate interaction.
However, their focus on short observation windows and dense prediction means they often struggle to capture long-horizon semantics. They might predict how an object moves in the next second, but not why it might move that way or what its ultimate goal is. This "short-sightedness" limits their use for tasks requiring complex planning or understanding intent.
On the other side, Vision-Language Models (VLMs) offer strong semantic grounding and general knowledge. They can reason about scenes and provide high-level understanding by sampling frames, but they aren't built for dense, real-time prediction. VLMs typically use sparse sampling, have a language-output bottleneck that compresses fine-grained states into text, and often struggle with small, action-conditioned datasets relevant to robotics. They give you the "what" and "why" but not the precise "how" in a continuous, predictive sense. For autonomous drones, we need both.
Fusing Foresight and Fine Detail: ThinkJEPA's Architecture
ThinkJEPA addresses this by building a hybrid system, combining the strengths of both approaches. The core idea is a "dual-temporal pathway" that integrates a dense JEPA-style predictor with a VLM-driven semantic "thinker."
The system employs a dense JEPA branch for fine-grained motion and interaction cues. This branch operates on a short observation window, excelling at predicting immediate, detailed changes in the environment. It's the drone's reflex system, understanding moment-to-moment dynamics.
Simultaneously, a uniformly sampled VLM thinker branch provides long-horizon semantic guidance. This branch operates over a larger temporal stride, processing sparsely sampled frames to build a richer, knowledge-driven understanding of the scene. It's the drone's planning brain, comprehending context and intent over a longer timeframe.
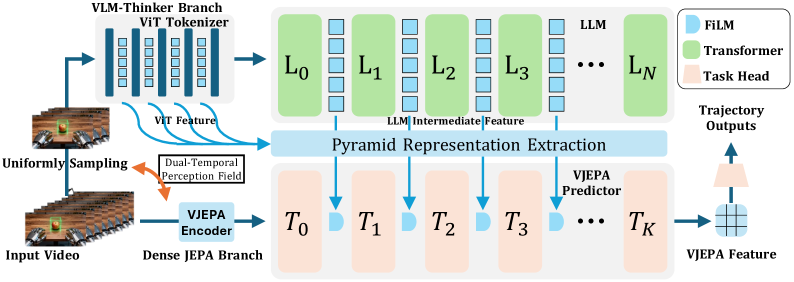 Figure 1: ThinkJEPA's overall architecture. It combines a dense JEPA branch for detailed dynamics with a VLM-thinker branch for long-horizon semantic guidance. VLM signals are distilled and injected into the JEPA predictor via layer-wise modulation.
Figure 1: ThinkJEPA's overall architecture. It combines a dense JEPA branch for detailed dynamics with a VLM-thinker branch for long-horizon semantic guidance. VLM signals are distilled and injected into the JEPA predictor via layer-wise modulation.
To effectively transfer the VLM's progressive reasoning signals, the authors introduce a hierarchical pyramid representation extraction module. This component aggregates multi-layer VLM representations into guidance features. These guidance features are then injected into the V-JEPA predictor via layer-wise modulation, essentially teaching the JEPA branch to incorporate the VLM's high-level understanding into its detailed predictions. This modulation allows the VLM's semantic knowledge to influence the JEPA's fine-grained dynamics.
Predicting Trajectories with Clarity
The proof is in the pudding, and ThinkJEPA shows tangible improvements. The paper specifically tests its capabilities on hand-manipulation trajectory prediction, a complex task that demands both precise motion forecasting and an understanding of human intent.
- Smoother Trajectories: ThinkJEPA produces demonstrably smoother predicted trajectories compared to baselines. This indicates better temporal consistency – a critical factor for realistic and actionable predictions.
- Improved Joint Alignment: Predictions show better alignment of individual joints over time, suggesting a more accurate understanding of the underlying physical movements.
- Outperforms Baselines: The method outperforms both a strong VLM-only baseline and a JEPA-predictor baseline. This isn't just a marginal win; it suggests that the fusion truly works better than either component in isolation.
- Robust Long-Horizon Rollout: ThinkJEPA exhibits more robust behavior when predicting further into the future. This is where the VLM's semantic guidance really shines, preventing the predictor from devolving into nonsensical extrapolation.
 Figure 2: Qualitative results showing predicted future hand-manipulation trajectories as heat maps. ThinkJEPA generates smoother, more temporally consistent trajectories with better joint alignment.
Figure 2: Qualitative results showing predicted future hand-manipulation trajectories as heat maps. ThinkJEPA generates smoother, more temporally consistent trajectories with better joint alignment.
These results, while demonstrated in hand manipulation, are highly indicative of what's possible for drone autonomy. Predicting the flight path of another drone, the movement of a pedestrian, or the trajectory of a thrown object with this level of accuracy could transform drone capabilities.
Real-World Impact: Smarter, Safer Drone Autonomy
For drone hobbyists and engineers, ThinkJEPA offers a compelling vision for the future of autonomous flight. This isn't just about better obstacle avoidance; it's about proactive navigation.
Consider a delivery drone not just seeing a car, but predicting that the car is about to turn into its path based on semantic cues like turn signals, road markings, and even driver behavior. Or a search-and-rescue drone predicting the likely movement path of a person in distress across varied terrain, rather than just reacting to their last known position. For drone racing, this could mean predicting rival drone maneuvers several seconds in advance, allowing for strategic counter-play.
This technology could lead to:
- Enhanced Safety: By predicting potential collisions or problematic scenarios much earlier, drones can take evasive action with more lead time, making operations safer.
- Optimized Path Planning: Drones could plan routes that avoid not just static obstacles, but also predicted dynamic obstacles, leading to more efficient and reliable missions.
- Improved Human-Drone Interaction: For drones working alongside humans, predicting human intent (e.g., a worker reaching for a tool) could make collaborative tasks smoother and safer.
- Complex Mission Execution: Drones could handle more intricate tasks requiring multi-agent coordination or long-term situational awareness. Swarm drones could predict the formation changes of other swarm members, improving coordination.
Where ThinkJEPA Still Needs to Grow: Current Limitations
While ThinkJEPA is a significant step, it's not a silver bullet. The paper points to several areas for improvement and inherent limitations:
- Computational Cost: Running both a dense JEPA predictor and a VLM "thinker" simultaneously is computationally intensive. While the VLM branch uses sparse sampling, integrating complex VLMs on a drone's onboard computer still presents a formidable challenge in terms of
SWaP-C(Size, Weight, Power, and Cost). This is where research likeWorldCacheby Nawaz et al. (which proposes content-aware caching for video world models) becomes highly relevant, as acceleration techniques will be crucial for real-time deployment. - Data Regime Mismatch: The VLM component is trained on vast, diverse datasets, while action-conditioned robotics datasets are often smaller and more specific. Adapting large VLMs to these smaller, specialized datasets without losing their general knowledge remains a challenge.
- Generalization to Novel Scenarios: While VLMs provide general knowledge, how well ThinkJEPA generalizes to entirely novel, unobserved dynamic interactions in the real world—especially in unpredictable outdoor drone environments—is yet to be fully explored. The current experiments are in controlled hand-manipulation settings.
- Real-time Latency: Although the VLM branch is sparsely sampled, the overall system's latency for making predictions in real-time on drone hardware needs careful consideration. This is where efficient video understanding, like the techniques explored in
VideoDetectiveby Yang et al. for clue hunting in long videos, could help by feeding only the most relevant information to the world model.
Is This for Your Next Build? Practical Considerations
For the average hobbyist builder, directly replicating ThinkJEPA in its current form is likely out of reach. The model relies on large vision-language models and sophisticated JEPA architectures, requiring substantial computational resources for training and inference. Think NVIDIA A100 GPUs, not Raspberry Pis.
However, the concepts are highly valuable. Open-source implementations of V-JEPA exist, and foundational VLMs are increasingly accessible. As these models become more efficient and specialized for edge devices, we might see distilled or quantized versions that are feasible for powerful embedded systems like NVIDIA Jetson platforms. The underlying principles of combining different AI modalities for richer world understanding are certainly something to watch and eventually integrate into custom drone projects. Understanding how VLMs perform spatial reasoning, as detailed in "The Dual Mechanisms of Spatial Reasoning in Vision-Language Models" by Cui et al., will be key for those looking to fine-tune or adapt such models.
The Path to Truly Autonomous Drones
ThinkJEPA pushes the boundaries of what's possible for autonomous systems. By merging the precision of dense prediction with the wisdom of semantic reasoning, it offers a compelling vision for drones that don't just react to the world, but truly understand and anticipate it. This is a critical step towards a future where our drones are not just highly capable machines, but intelligent partners in the sky.
Figure 3: ThinkJEPA Logo.
Paper Details
Title: ThinkJEPA: Empowering Latent World Models with Large Vision-Language Reasoning Model Authors: Haichao Zhang, Yijiang Li, Shwai He, Tushar Nagarajan, Mingfei Chen, Jianglin Lu, Ang Li, Yun Fu Published: March 26, 2024 arXiv: 2603.22281 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.