Real-Time Drone Cognition: Thinking While Watching with Video Streaming LLMs
A new AI paradigm, `Video Streaming Thinking` (`VST`), enables drones to reason and make decisions simultaneously as they process live video feeds. This approach significantly reduces latency, moving drones beyond mere perception to active, real-time understanding.
TL;DR: Traditional drone AI struggles to perform complex reasoning on live video without introducing unacceptable delays.
Video Streaming Thinking(VST) tackles this by allowingLarge Language Models(LLMs) to 'think' about incoming video clips as they watch them, making real-time, cognitive drone operations a tangible reality.
Beyond Just Seeing: Drones That Understand
For too long, our drones have been excellent observers. They map, they detect, they track. But true autonomy demands more than just perception; it requires cognition – the ability to reason, understand context, and make intelligent decisions as events unfold. This isn't about pre-programmed responses; it's about a drone actively thinking its way through complex, dynamic environments. A new paper introduces Video Streaming Thinking (VST), a novel approach that could be the key to unlocking this next level of drone intelligence, allowing our aerial platforms to watch and think simultaneously.
The Latency Problem in Drone Brains
Current drone AI, especially when leveraging powerful Large Language Models (LLMs) for complex reasoning, hits a wall: latency. Consider a drone inspecting a damaged structure or navigating a cluttered disaster zone. It needs to process visual data, identify anomalies, infer causes, and decide on its next move, all in milliseconds. Traditional methods either focus on rapid perception (what's there?) or deep reasoning (what does it mean, and what should I do?). The problem is, combining deep reasoning with real-time video streams usually means waiting for the entire stream to be processed or for a query to be posed before the LLM can begin its Chain-of-Thought (CoT) analysis. This sequential approach simply doesn't work for real-time, mission-critical drone operations. The computational overhead, power consumption, and resulting delays are often unacceptable for edge devices. We need drones that can process information and reason about it continuously, without pausing.
Thinking While Watching: How VST Works
The core innovation of VST is its "thinking while watching" mechanism. Instead of waiting for a complete video segment or a specific query to begin reasoning, VST proactively activates reasoning processes over incoming video clips during streaming. This is a subtle but profound shift.
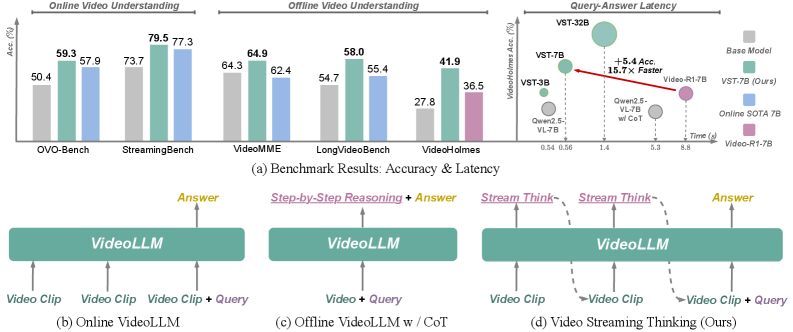
Figure 1: VST introduces proactive pre-query reasoning, interleaving it with video consumption to achieve both strong performance and efficient responsiveness, a stark contrast to traditional post-query reasoning.
As video frames stream in, VST generates stream thoughts – textual summaries or inferences about what's happening. These thoughts are then compressed into a long-term textual memory, constantly updated and refined. This approach amortizes the computationally intensive LLM reasoning latency over the video playback itself. When a query or a need for a decision arises, the model doesn't start from scratch; it already has a rich, reasoned understanding of the ongoing events, allowing for rapid, informed responses.
The VST pipeline leverages both a short-term visual buffer (for immediate visual context) and this long-term textual memory to efficiently reason over indefinite video streams with fixed memory budgets. This means a drone can continuously process and understand its environment without its memory ballooning out of control.
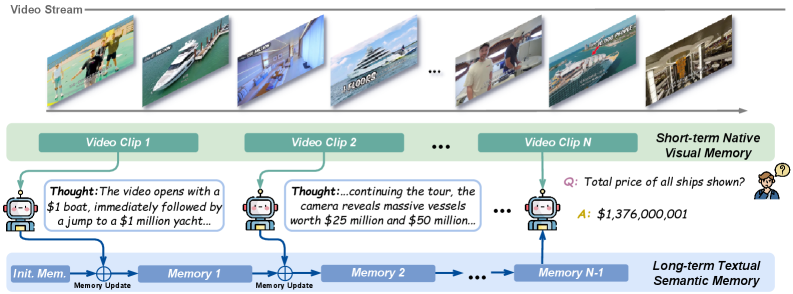
Figure 2: The VST pipeline uses a streaming thought mechanism to compress visual dynamics into long-term textual memory, enabling efficient reasoning over indefinite video streams.
To achieve this, the authors developed a comprehensive post-training pipeline. VST-SFT (Supervised Fine-Tuning) structurally adapts an offline VideoLLM to perform causal streaming reasoning, ensuring attention is restricted to current visual data and historical textual context. Then, VST-RL (Reinforcement Learning) uses an on-policy optimization loop to improve the quality of these streaming thoughts, with rewards computed from the final answer, pushing the model towards better, more verifiable reasoning.
A crucial part of training such a system is generating high-quality data. The team devised an automated data synthesis pipeline using video knowledge graphs. This system extracts entities and relations from videos, builds a knowledge graph, and then generates streaming QA pairs with entity-relation grounded streaming Chain-of-Thought. This ensures the model learns to enforce multi-evidence reasoning and sustain attention across the video stream, vital for complex drone tasks.
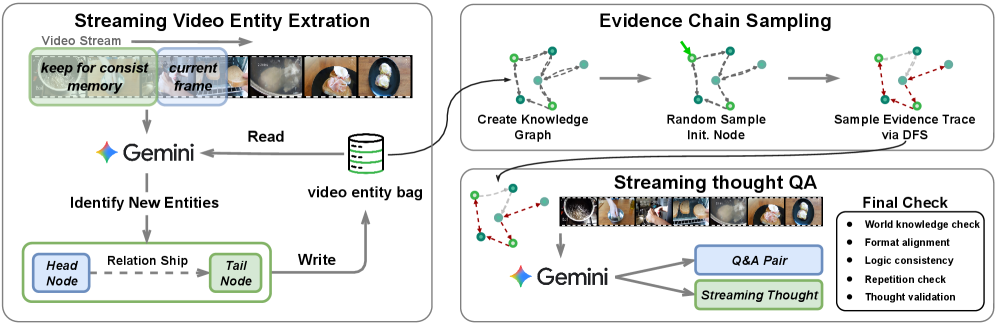
Figure 4: The data curation pipeline generates high-quality streaming QA pairs with grounded thoughts by leveraging video knowledge graphs and Gemini.
The Numbers Speak: Faster, Smarter Responses
The results are compelling. VST doesn't just promise faster responses; it delivers them while improving accuracy.
- Online Benchmarks:
VST-7Bscored an impressive 79.5% onStreamingBenchand 59.3% onOVO-Bench, demonstrating strong performance in real-time scenarios. - Speed & Efficiency: Compared to
Video-R1, a leading baseline,VST-7Bresponds 15.7 times faster. This is not a marginal gain; it's a difference that makes real-time applications feasible. - Accuracy Boost: On the
VideoHolmesreasoning benchmark,VSTachieved a +5.4% improvement overVideo-R1, indicating that this speed doesn't come at the cost of reasoning quality. - Generalization:
VSTremains competitive on offline long-form and reasoning benchmarks, showing its robust generalization across diverse video understanding tasks.
This combination of speed and accuracy is precisely what edge AI on drones needs. It means less time waiting for decisions and more intelligent, responsive drone behavior.

Figure 6: A case study demonstrating VST-7B's proactive reasoning and lower QA latency compared to Video-R1-7B's post-query Chain-of-Thought generation.
What This Means for Drone Autonomy
A drone equipped with Video Streaming Thinking moves beyond reactive control to proactive, cognitive autonomy.
Consider these applications:
- Intelligent Inspection: A drone inspecting power lines or wind turbines could not only detect a cracked component but
reasonabout its severity, the likely cause, and even suggest immediate actions or flag critical areas for human review, all in real-time. - Advanced Search & Rescue: In a disaster zone, a drone could identify a person, infer their state (e.g., trapped, conscious), understand the surrounding hazards, and dynamically adjust its search pattern or communicate critical information to ground teams with unprecedented speed and detail.
- Complex Navigation: Navigating through highly dynamic, cluttered environments like crowded urban areas or dense forests requires more than just obstacle avoidance. A
VST-enabled drone could understand the intent of moving objects (pedestrians, vehicles), predict their trajectories, and plan safer, more efficient paths by reasoning about the overall scene, not just individual pixels. - Human-Drone Collaboration: Picture a drone that can understand natural language instructions in context, reasoning about its visual feed to execute complex tasks like "find the blue toolbox next to the fallen tree" and provide detailed, reasoned updates on its progress.
This capability transforms drones into active participants in their missions, capable of understanding and interacting with the world in a much more nuanced way.
The Road Ahead: Limitations and Challenges
While VST represents a significant leap, it's essential to acknowledge its current limitations and the path to real-world deployment.
First, the current VST-7B model, while efficient, still represents a 7 billion parameter LLM. Running such a model on typical drone edge hardware (e.g., a Jetson Nano or a Raspberry Pi 5) is challenging due to power, weight, and computational constraints. While more powerful platforms like NVIDIA Jetson Orin or Qualcomm RB5 can handle it, optimizing for smaller, lighter payloads remains a hurdle.
Second, the automated training-data synthesis pipeline relies on Gemini for generating streaming QA pairs. While effective, this introduces a dependency on a proprietary model and raises questions about potential biases in the generated data, as well as the computational cost associated with large-scale data generation.
Third, the paper mentions reasoning over "indefinite video streams with fixed memory budgets." While this is a clever approach to managing memory, the robustness of this long-term textual memory in extremely long, complex, or ambiguous scenarios needs further exploration. How well does it maintain coherent cognition over hours of footage in highly dynamic environments?
Finally, real-world drone autonomy often requires robust sensor fusion beyond just video. Integrating VST's cognitive capabilities with data from LiDAR, radar, IMUs, and other sensors will be crucial for building truly resilient and reliable autonomous systems. The current approach focuses solely on video input for reasoning.
Getting Your Hands Dirty: DIY Feasibility
The good news for hobbyists and builders is that the authors plan to release code, data, and models on GitHub (https://github.com/1ranGuan/VST). This is critical for anyone looking to experiment or build upon this research.
Running a 7B parameter model on a drone is becoming increasingly feasible with advancements in edge AI accelerators. While training such models from scratch requires significant compute, fine-tuning a pre-trained VST model for specific drone tasks (e.g., identifying specific types of damage, understanding particular gestures) might be within reach for those with access to cloud GPUs or powerful local workstations. The open-source release will allow developers to explore how to integrate this "thinking" capability into their existing drone platforms and ROS setups.
Complementary Powers for True Autonomy
Video Streaming Thinking doesn't exist in a vacuum. Its effectiveness in real-world drone applications will be amplified by complementary research. For instance, EVATok: Adaptive Length Video Tokenization directly addresses the need for efficient video data compression, crucial for feeding VST on resource-constrained edge devices without overwhelming them. Similarly, Attend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing (AutoGaze) helps MLLMs process long, high-resolution videos by reducing spatiotemporal redundancy, which would make VST even more efficient in handling extended drone missions.
Beyond just processing, a truly cognitive drone needs to build a robust understanding of its environment. Spatial-TTT: Streaming Visual-based Spatial Intelligence focuses on continuously updating spatial evidence from video streams. This spatial understanding would perfectly complement VST's logical reasoning, giving the drone a comprehensive, reasoned awareness of its physical world. Ultimately, these pieces fit into a broader vision, as explored by OmniStream: Mastering Perception, Reconstruction and Action in Continuous Streams, which outlines the holistic capabilities a truly autonomous, 'thinking' drone would need to integrate.
The ability for a drone to not just see, but to actively reason and understand its world in real-time, is a monumental step towards truly intelligent autonomy. This research provides a solid foundation for building the next generation of cognitive drones.
Paper Details
Title: Video Streaming Thinking: VideoLLMs Can Watch and Think Simultaneously
Authors: Yiran Guan, Liang Yin, Dingkang Liang, Jianzhong Ju, Zhenbo Luo, Jian Luan, Yuliang Liu, Xiang Bai
Published: March 2024
arXiv: 2603.12262 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.