Verified Vision: The AI Logic Drones Need for True Autonomy
A new benchmark, MM-CondChain, pushes multimodal AI models to perform complex, visually grounded reasoning chains, crucial for drones moving beyond simple object detection to sophisticated, verified decision-making.
TL;DR: Current AI benchmarks for visual reasoning are too simple for real-world drone tasks. MM-CondChain introduces a new standard for MLLMs to prove they can handle deep, verifiable, conditional visual logic, revealing significant gaps in current model capabilities for true autonomous decision-making.
Giving Drones Real Brains, Not Just Eyes
Drones are getting smarter, but how smart is "smart enough" for truly autonomous, complex missions? We're moving past simple object avoidance and target tracking. The next frontier for drone autonomy isn't just seeing objects; it's understanding intricate visual conditions and acting on them with verifiable logic. Think about a drone inspecting a power grid: "If a specific connector is corroded AND the adjacent insulation shows a crack, then deploy a repair module." This isn't a single observation; it’s a chained, conditional decision, and it requires a level of AI sophistication that current benchmarks haven't adequately tested.
Why Current AI Falls Short for Drone Brains
Existing AI benchmarks for Multimodal Large Language Models (MLLMs)—the brains that process both vision and text—haven't cut it for this level of complexity. They often focus on what the authors call "shallow compositions" or "independent constraints." This means an MLLM might identify a red car and a blue truck, or answer "Is the car red?" and "Is the truck blue?" separately.
But real-world drone operations demand more. A drone can't just identify elements; it needs to reason over multiple visual cues simultaneously and sequentially. It needs to follow a branching logic path where one visual condition dictates the next step, and a slight change in the scene could completely alter the mission. Current MLLMs struggle with this deep, chained compositional reasoning. This limitation means drones are still largely reactive, not truly proactive decision-makers capable of navigating complex, conditional workflows without human oversight. The cost? Slower missions, higher risk of errors, and a heavy reliance on human intervention for anything beyond basic tasks.
Building a Smarter AI Test Track
Enter MM-CondChain, a benchmark designed to push MLLMs beyond their current limits. The researchers recognized that for MLLMs to power truly intelligent drone applications, they need to be tested on scenarios that mirror real-world decision workflows. MM-CondChain creates "multi-layer reasoning chains" where each step involves a non-trivial compositional condition. This condition is grounded in detailed visual evidence, requiring the MLLM to perceive multiple objects, attributes, or relationships within an image.
 Figure 1: MM-CondChain targets visually grounded deep conditional reasoning beyond prior benchmarks. Top: existing benchmarks typically evaluate either shallow single-layer visual compositions or independent instruction constraints. Bottom left: MM-CondChain introduces nested, inter-layer conditional chains with rich intra-layer compositional predicates, where a minimally perturbed condition can create a hard negative that changes the execution path and causes early termination. Bottom right: experiments show that even advanced MLLMs achieve limited performance on this benchmark, highlighting visually grounded deep compositional reasoning as a fundamental challenge.
Figure 1: MM-CondChain targets visually grounded deep conditional reasoning beyond prior benchmarks. Top: existing benchmarks typically evaluate either shallow single-layer visual compositions or independent instruction constraints. Bottom left: MM-CondChain introduces nested, inter-layer conditional chains with rich intra-layer compositional predicates, where a minimally perturbed condition can create a hard negative that changes the execution path and causes early termination. Bottom right: experiments show that even advanced MLLMs achieve limited performance on this benchmark, highlighting visually grounded deep compositional reasoning as a fundamental challenge.
The genius here isn't just the complexity, but how they built it. To generate this kind of data scalably, they developed an "agentic synthesis pipeline." This pipeline has three core components:
- The Planner: This orchestrates the layer-by-layer generation of compositional conditions. It ensures that each step builds logically on the previous one.
- Verifiable Programmatic Intermediate Representation (
VPIR): This is the backbone for ensuring accuracy. The Planner generates condition logic not just as natural language, but as aVPIRpredicate pair. ThisVPIRis mechanically verifiable, meaning code execution can confirm if the condition is true or false based on the visual input. This is critical because it removes ambiguity and guarantees the ground truth for the benchmark. For a drone, this means the AI's "understanding" can be mathematically validated. - The Composer: Once individual layers are verified, the Composer assembles them into complete, workflow-style instructions. It even creates "True-path" and "False-path" instances, where a minimal visual perturbation can change the execution path or lead to early termination – a crucial test for robust decision-making.
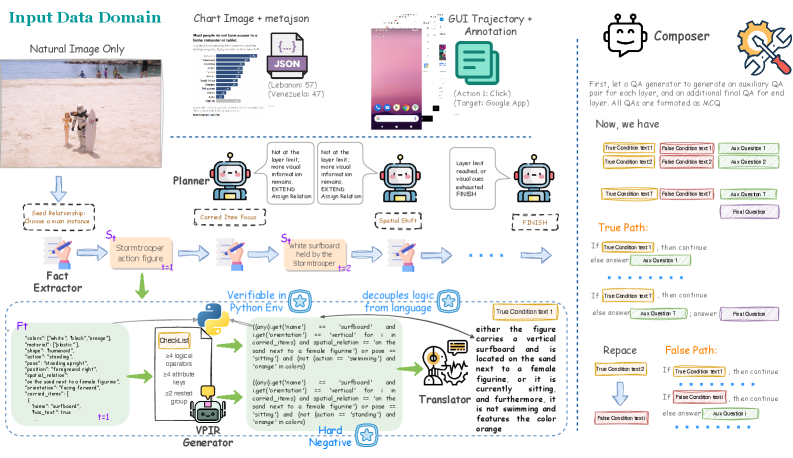 Figure 2: Overview of the MM-CondChain agentic synthesis pipeline. Given a multimodal input, the Planner iteratively extends a conditional chain: at each layer, structured facts are extracted, a VPIR predicate pair is generated and verified via code execution, and the logic is rendered into natural language. The Composer then compiles the verified chain into paired True-path and False-path instances for evaluation.
Figure 2: Overview of the MM-CondChain agentic synthesis pipeline. Given a multimodal input, the Planner iteratively extends a conditional chain: at each layer, structured facts are extracted, a VPIR predicate pair is generated and verified via code execution, and the logic is rendered into natural language. The Composer then compiles the verified chain into paired True-path and False-path instances for evaluation.
The VPIR is particularly interesting. It’s not just abstract logic; it instantiates into executable predicates. These cover a range of logical patterns, from comparing object attributes (color_of(obj1) == 'red') to spatial relationships (is_left_of(obj1, obj2)). This programmatic approach ensures that the visual conditions are precise and unambiguous, something a drone’s control system would demand.
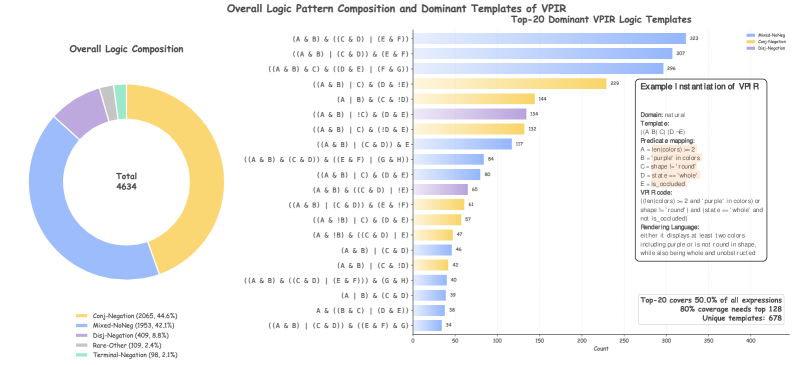 Figure 9: Logic pattern composition of VPIR expressions. Left: overall distribution of high-level VPIR logic families. Middle: top-20 dominant concrete VPIR templates. Right: an example showing how a VPIR template is instantiated into executable predicates and natural-language conditions.
Figure 9: Logic pattern composition of VPIR expressions. Left: overall distribution of high-level VPIR logic families. Middle: top-20 dominant concrete VPIR templates. Right: an example showing how a VPIR template is instantiated into executable predicates and natural-language conditions.
The Hard Numbers: Where AI Stumbles
The researchers tested a range of MLLMs on MM-CondChain across three domains: natural images, data charts, and GUI trajectories. The results are sobering. Even the strongest models managed only a 53.33 Path F1 score. Path F1 measures how well the MLLM correctly follows the entire conditional reasoning chain, not just individual steps.
Key findings include:
- Low Overall Performance: A 53.33 Path F1 is far from robust for real-world drone autonomy. It indicates that current
MLLMsfrequently fail to follow complex visual logic paths. - Sharp Drops on Hard Negatives: The benchmark includes "hard negatives" – scenarios where a subtle visual change alters the correct path.
MLLMsshowed significant performance degradation here, highlighting their brittleness. - Complexity is a Killer: As the depth of the reasoning chain or the complexity of the predicates within each layer increased,
MLLMperformance consistently dropped. This is a direct challenge for multi-step drone missions.
These numbers confirm that while MLLMs can identify objects, their ability to perform deep, verifiable, conditional reasoning is still a fundamental challenge. For drone builders, this means relying on these models for critical, chained decisions is currently risky.
Why it Matters for Drones: Beyond Simple Sight
This research isn't just an academic exercise; it's a critical step towards truly autonomous drones. Imagine:
- Automated Inspection Drones: A drone inspecting a bridge could identify "if a crack is present AND its length exceeds 5cm AND it intersects a rivet head, then flag for immediate human review and take high-resolution thermal images." This requires deep compositional reasoning.
- Search and Rescue: A drone searching a disaster zone might be instructed: "If a human form is detected AND it is partially obscured by rubble AND there are no visible signs of movement, then activate an acoustic beacon and send coordinates."
- Logistics and Delivery: A drone navigating a warehouse could follow instructions like: "If a package with a 'Fragile' label is detected AND its destination bin is full, then redirect to auxiliary storage AND notify human operator."
These scenarios demand more than simple object detection; they need an AI that can reason over multiple visual elements, understand their relationships, and execute a predefined, verifiable logic chain. MM-CondChain is directly testing the capabilities required for these advanced applications, pushing MLLMs closer to becoming reliable, intelligent agents rather than just sophisticated sensors.
Limitations & What's Still on the Horizon
While MM-CondChain is a significant leap, it's a benchmark, not a deployed system. Several limitations and challenges remain:
- Computational Cost:
MLLMsare notoriously resource-intensive. Running deep compositional reasoning on a drone's onboard hardware, with its limited power and processing, is a massive hurdle. The paper doesn't address the efficiency of these models, only their logical capability. - Real-world Noise: The benchmark data, while complex, is structured. Real-world drone environments are messy: varying lighting, occlusions, motion blur, and unexpected objects. How well these models generalize to such noisy conditions is an open question.
- Beyond Explicit Logic: While
VPIRensures verifiable programmatic logic, human instructions can be more ambiguous or rely on common sense not easily captured by explicit conditions. The benchmark focuses on programmatic reasoning, which is important but not exhaustive of all human-like intelligence. - Lack of Action Space:
MM-CondChainevaluates reasoning towards an "outcome" (true/false path). It doesn't directly evaluate the physical actions a drone would take, which involves control systems, path planning, and interaction with the environment.
DIY Feasibility: Concepts for the Builder
Directly replicating the MM-CondChain benchmark and its agentic synthesis pipeline is a significant undertaking, requiring expertise in MLLM architectures, programmatic verification, and large-scale data generation. It's not a weekend project for a hobbyist.
However, the concepts are highly relevant. Drone builders and engineers can take several lessons:
- Focus on Robust Logic: When designing autonomous behaviors, move beyond simple
if-thenstatements. Consider nestedif-else if-elsestructures that rely on multiple visual cues. - Verify Your Visual Conditions: The
VPIRconcept of mechanically verifiable conditions is powerful. Even in simpler systems, implementing checks to confirm visual states are unambiguously met before an action is taken can drastically improve reliability. - Open-Source MLLMs: As more capable
MLLMsbecome open-source, understanding benchmarks likeMM-CondChainhelps in selecting and fine-tuning models that are truly capable of complex decision-making, rather than just impressive chat.
Related Work: The Full Stack of Drone AI
To make the kind of deep compositional reasoning tested by MM-CondChain practical for drones, several other pieces of the AI puzzle need to fall into place. For instance, processing the sheer volume of high-resolution video data efficiently on a drone's limited onboard hardware is a major challenge. This is where "Attend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing" comes in. Their AutoGaze mechanism allows MLLMs to selectively "gaze" at important regions of video, drastically reducing computational load. This provides the crucial efficiency layer needed for MM-CondChain's advanced reasoning to run in real-time.
Furthermore, a drone needs to process video streams and reason simultaneously, not sequentially. "Video Streaming Thinking: VideoLLMs Can Watch and Think Simultaneously" directly addresses this, focusing on how VideoLLMs can achieve "synchronized logical reasoning." This capability is essential for a drone to respond dynamically to changing visual conditions, allowing it to "watch and think" concurrently, which is vital for real autonomy as envisioned by MM-CondChain.
Finally, before any sophisticated VideoLLM can even begin to reason, the raw video data needs efficient preparation. "EVATok: Adaptive Length Video Tokenization for Efficient Visual Autoregressive Generation" offers a solution for adaptive length video tokenization. This optimizes the compression of pixels into discrete tokens, managing computational costs and maintaining reconstruction quality. EVATok provides a foundational efficiency layer, ensuring that the visual data is ready for the advanced processing and reasoning described in MM-CondChain and other related works.
These papers collectively paint a picture of the holistic advancements required: efficient video processing, real-time synchronized reasoning, and robust, verifiable conditional logic.
The path to truly autonomous drones hinges on their ability to not just see, but to understand and reason with verifiable logic. This benchmark is a stark reminder of how far we still have to go, but also a clear roadmap for what comes next.
Paper Details
Title: MM-CondChain: A Programmatically Verified Benchmark for Visually Grounded Deep Compositional Reasoning
Authors: Haozhan Shen, Shilin Yan, Hongwei Xue, Shuaiqi Lu, Xiaojun Tang, Guannan Zhang, Tiancheng Zhao, Jianwei Yin
Published: March 2026 (based on arXiv ID 2603.12266)
arXiv: 2603.12266 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.