Voice Control for Drones: Loc3R-VLM Teaches Drones 3D Spatial Language
New research introduces Loc3R-VLM, a framework enabling drones to understand natural language for 3D localization and reasoning from monocular video. It tackles current VLM limitations in spatial awareness, promising intuitive, voice-driven drone control.
TL;DR: Loc3R-VLM trains vision-language models to truly understand 3D space and an agent's position within it, not just describe images. This is done through explicit spatial supervision, allowing drones to localize themselves and answer questions based on natural language commands and monocular video input.
Controlling a drone with a joystick works for precise maneuvers, but imagine simply telling it, "Hover above the red car," or "Find the box to my left and inspect it." This isn't a futuristic concept; new research from Kevin Qu and his team at institutions like ETH Zurich and Google is pushing vision-language models (VLMs) toward this exact capability. Their new framework, Loc3R-VLM, aims to equip drones with sophisticated 3D spatial understanding directly from a single camera feed, translating human language into actionable, viewpoint-aware navigation.
The Spatial Reasoning Gap in Today's AI
Modern multimodal large language models (MLLMs) are impressive at connecting images and text. They can describe what they see, identify objects, and even answer questions about scenes. The challenge is that they often operate in a fundamentally 2D space, or they rely on computationally heavy 3D representations impractical for a small drone. These models struggle significantly with genuine spatial understanding, like knowing where an object is relative to the drone itself, or understanding commands that rely on egocentric perspective ("to my right," "above me"). Current approaches often try to infer geometry from visual cues, but they lack the explicit spatial grounding needed for robust, reliable drone navigation. A drone might see a red car, but it doesn't intrinsically understand its position in a 3D coordinate system or how to navigate to it based on a high-level command. This gap limits truly autonomous, language-driven missions, often pushing developers back to cumbersome joystick controls or pre-programmed waypoints.
How Loc3R-VLM Builds a 3D Cognitive Map
Loc3R-VLM addresses this by directly teaching VLMs to reason in 3D, inspired by how humans understand space. The core idea involves augmenting standard 2D VLM inputs with geometric cues, then training the model using two complementary spatial objectives. It takes monocular video as input, which is crucial for drones constrained by size, weight, and power. Instead of relying on expensive 3D sensors, it leverages lightweight camera pose priors extracted from a pre-trained 3D foundation model like CUT3R. These priors give the VLM an initial sense of its own movement and orientation.
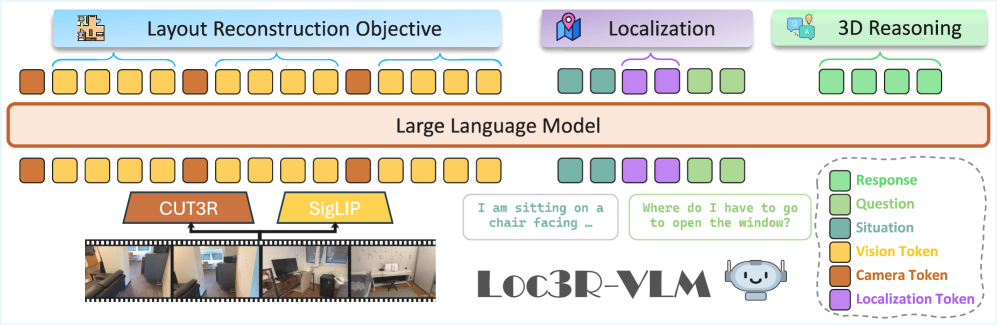 Figure 2: Overview of Loc3R-VLM. The framework uses monocular video and augments vision tokens with camera pose priors. It's trained with layout reconstruction and situation modeling objectives to enable viewpoint-aware 3D reasoning.
Figure 2: Overview of Loc3R-VLM. The framework uses monocular video and augments vision tokens with camera pose priors. It's trained with layout reconstruction and situation modeling objectives to enable viewpoint-aware 3D reasoning.
The first objective is global layout reconstruction. This grounds vision patch tokens from the input video into a bird's-eye-view (BEV) space, effectively building a holistic, 3D map of the scene. Picture the drone constructing a mental floor plan as it flies. This BEV representation captures the global scene structure, allowing the model to understand the relative positions of objects and landmarks.
The second objective is explicit situation modeling. This utilizes dedicated localization query tokens to anchor the drone's egocentric perspective. It's not just about mapping the environment; it's about knowing where the drone is within that map and which way it's facing. This provides direct spatial supervision, grounding both visual perception and language understanding in a consistent 3D context. The entire framework is trained end-to-end, combining losses from layout reconstruction, localization, and language comprehension.
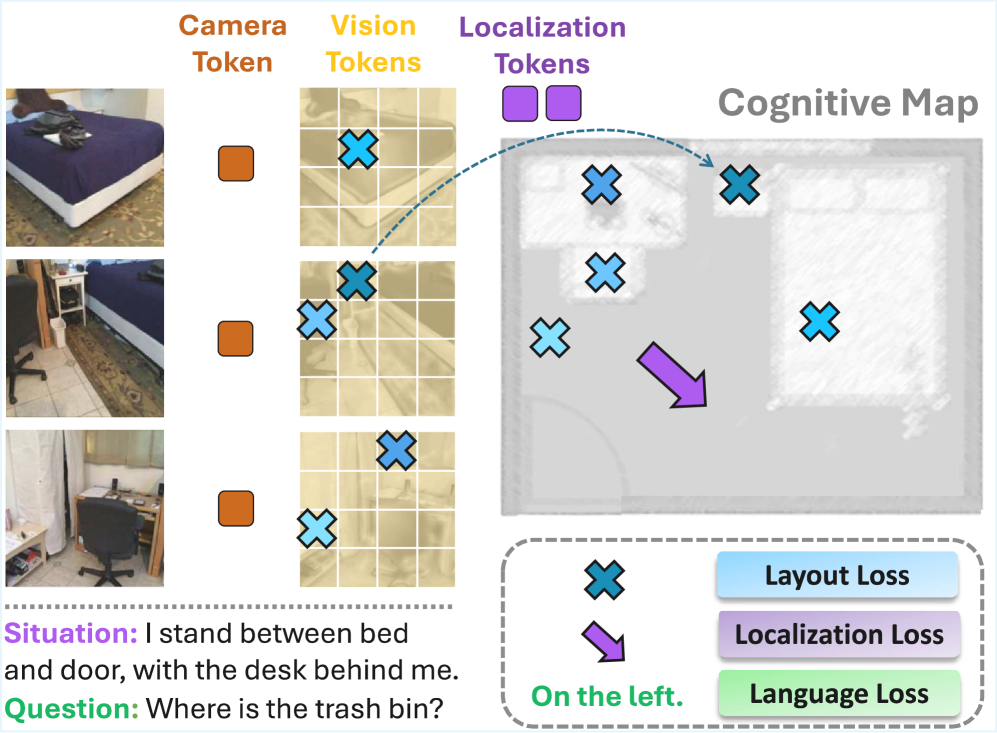 Figure 3: Spatial Supervision Framework introduces complementary training signals. The model learns to ground vision patch tokens onto BEV coordinates for global scene structure and uses localization tokens to model agent position and orientation.
Figure 3: Spatial Supervision Framework introduces complementary training signals. The model learns to ground vision patch tokens onto BEV coordinates for global scene structure and uses localization tokens to model agent position and orientation.
Quantifiable Leaps in Understanding
Loc3R-VLM delivers quantifiable improvements, moving beyond mere promises of better understanding. The authors report that the framework achieves state-of-the-art performance in language-based localization. Specifically, it significantly outperforms existing 2D- and video-based approaches on situated and general 3D question-answering benchmarks. The model can accurately determine its position based on a descriptive command and answer complex questions requiring true 3D reasoning.
- Improved Localization Accuracy: The model can localize an agent with a position error of less than 1.0 meter and an orientation error of less than 45 degrees, which is crucial for practical drone navigation based on language commands.
- Enhanced QA Performance: The accuracy of answering situated questions (e.g., "What is to my left?") is substantially higher when Loc3R-VLM correctly localizes the agent. This directly demonstrates that its learned situation representation leads to effective viewpoint-aware reasoning.
- Reliable Uncertainty Estimates: The model can also predict its own positional uncertainty. When localization is inaccurate, the predicted uncertainty is notably higher, providing a valuable metric for the reliability of its spatial understanding.
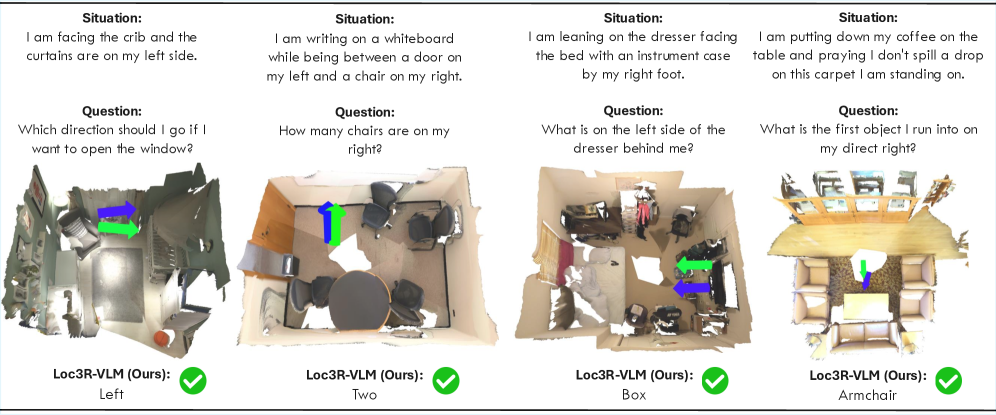 Figure 4: Qualitative Results for language-based localization and situated QA. Loc3R-VLM accurately grounds described situations (blue: prediction, green: ground truth) and provides correct viewpoint-dependent answers.
Figure 4: Qualitative Results for language-based localization and situated QA. Loc3R-VLM accurately grounds described situations (blue: prediction, green: ground truth) and provides correct viewpoint-dependent answers.
Why This Matters for Drones
For drone hobbyists, builders, and engineers, Loc3R-VLM is a significant step towards truly intuitive drone control and advanced autonomy. You could give your drone a mission like, "Fly around the building, find the damaged window on the third floor facing north, and take a high-resolution photo." Instead of manually flying or pre-programming a complex flight path, the drone could interpret this directly.
The technology could enable:
- Natural Language Mission Planning: Define complex tasks using everyday language, reducing the need for specialized programming or tedious waypoint setting.
- Autonomous Inspection: Drones could identify specific features or anomalies based on descriptive commands, making inspections faster and more precise.
- Search and Rescue: A drone could be instructed to "search the area to the west for a person in a red jacket," allowing human operators to focus on strategy rather than stick movements.
- Enhanced Human-Drone Collaboration: Operators could verbally guide drones in real-time for dynamic tasks, making autonomous systems more accessible and responsive.
Limitations and What's Still Missing
While Loc3R-VLM represents substantial progress, it's not a silver bullet. Reliance on CUT3R or similar pre-trained 3D foundation models for camera pose priors means it's not entirely self-contained; it builds on existing, complex vision systems. Monocular video input, while efficient, can still be challenged by poor lighting, highly textureless environments, or significant occlusions, potentially impacting the accuracy of its layout reconstruction. Running full MLLMs on resource-constrained drone hardware presents significant computational demands, which remain a hurdle. While the authors don't explicitly detail real-time performance on edge devices, the nature of these models suggests substantial processing power is still needed.
For real-world deployment, robust handling of dynamic environments (moving objects, changing conditions) and seamless integration with low-level flight control systems are critical next steps. The model understands where things are and what to do, but translating that into precise, safe motor commands in real-time is a separate engineering challenge. Furthermore, the current framework focuses on localization and reasoning; the explicit generation of a safe, collision-free trajectory based on complex language commands is still an area for further development.
DIY Feasibility: A Long Road Ahead
Replicating Loc3R-VLM as a hobbyist would be a monumental undertaking. The framework requires significant computational resources for training and inference, access to large datasets, and expertise in deep learning, MLLMs, and 3D vision. While the underlying components (monocular cameras, powerful single-board computers like NVIDIA Jetson or Raspberry Pi 5 with AI accelerators) are accessible, training such a sophisticated model from scratch or fine-tuning it effectively demands substantial GPU time and advanced knowledge. The authors leverage a pre-trained 3D foundation model, implying a complex development pipeline. This is currently research-grade technology, not something easily implemented with off-the-shelf hobbyist tools.
Connecting the Dots: Building a Smarter Drone
This research connects with other vital work. For a drone to truly act on language commands, it needs a deep understanding of its surroundings. The paper "Feeling the Space: Egomotion-Aware Video Representation for Efficient and Accurate 3D Scene Understanding" directly addresses the drone's fundamental ability to 'see' and 'understand' its environment robustly. It provides efficient video representations that could feed into systems like Loc3R-VLM, enhancing spatial awareness without excessive overhead. Furthermore, bringing complex VLMs to small drones requires serious optimization. "Unified Spatio-Temporal Token Scoring for Efficient Video VLMs" offers solutions for efficient token pruning, making the advanced language processing of Loc3R-VLM more viable on edge devices by reducing computational load. Once a drone understands where to go, it needs to execute that movement safely. "Specification-Aware Distribution Shaping for Robotics Foundation Models" is crucial for ensuring that these autonomous systems operate within formal safety parameters, building trust in their capabilities. Finally, bridging the gap from where to go to what to do when it gets there is critical. "GMT: Goal-Conditioned Multimodal Transformer for 6-DOF Object Trajectory Synthesis in 3D Scenes" provides a path for translating a localized goal into precise manipulation trajectories, completing the loop of intelligent, language-driven drone interaction with the physical world.
Loc3R-VLM is a compelling step towards drones that don't just follow commands, but truly comprehend their missions in the physical world, turning abstract language into concrete action. What specific language commands would you want your drone to understand first?
Paper Details
Title: Loc3R-VLM: Language-based Localization and 3D Reasoning with Vision-Language Models Authors: Kevin Qu, Haozhe Qi, Mihai Dusmanu, Mahdi Rad, Rui Wang, Marc Pollefeys Published: March 26, 2026 (based on arXiv ID, actual date may vary slightly) arXiv: 2603.18002 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.