Audio-Driven 3D Modeling: How VR Research Could Shape Drone Communication
New research on 3D facial animation from audio could enable drones to enhance telepresence and immersive communication with spatially aware modeling.

TL;DR: A new dual-stream AI model generates realistic 3D facial animations for two people in conversation using only audio input. It models spatial relationships, mutual gaze, and head orientation, paving the way for applications in VR, telepresence, and even drones.
Rethinking Communication with 3D Modeling
Imagine drones that could make remote collaboration feel as natural as an in-person meeting. That’s the promise of a new 3D modeling system designed for two-person interactions. Research by Shan et al. introduces a method to create highly realistic, spatially aware 3D animations of conversational partners using just audio input—no cameras or motion capture required. While the technology is primarily aimed at VR and telepresence, its potential applications for drones are worth exploring.
The Challenges of Realistic 3D Avatars
Creating believable 3D avatars for conversations is no small feat. Current systems often fall short in key areas:
- Lack of spatial dynamics: Most tools produce static “talking heads” that feel more like video calls than real conversations.
- Poor interaction modeling: Many models focus on one participant at a time, leading to disjointed and unnatural interactions.
- Limited spatial awareness: Simulating real-world layouts, such as where two people are positioned relative to each other, is a challenge.
- Unconvincing eye contact: Few systems can accurately replicate mutual gaze, a critical aspect of human communication.
For drones to serve as effective communication tools—whether in telepresence, search and rescue, or other scenarios—these limitations need to be addressed.
The Dual-Stream Model: A New Approach
The researchers propose a dual-stream diffusion architecture to tackle these challenges. This system uses two synchronized models to simulate a conversation between two people. Here’s how it works:
- Dual Streams: Each stream independently processes one participant’s behavior, such as facial expressions, lip-sync, and head movement, while exchanging data to model interactions.
- Role Embeddings: The model distinguishes between “speaker” and “listener” roles to disentangle mixed audio signals.
- Eye Gaze Loss: A specialized loss function ensures natural eye contact dynamics during conversational shifts.
- Extensive Training Data: The team curated over 2 million dyadic video pairs and synthesized additional data to train the model on various conversational scenarios.
How It Works
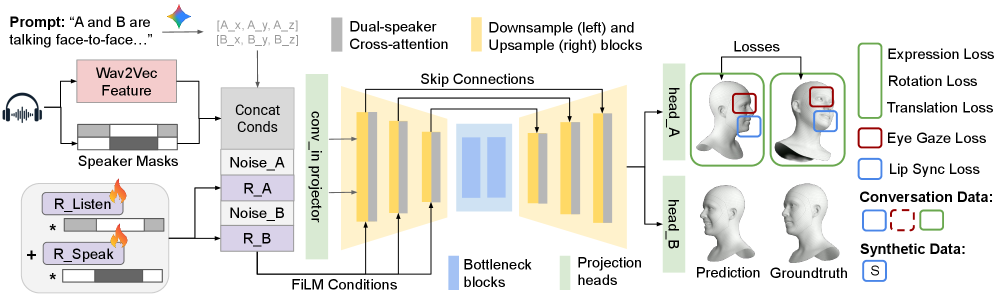
The U-Net backbone processes noisy input, disentangles multi-speaker audio, and outputs 3D animation parameters.
Training Data
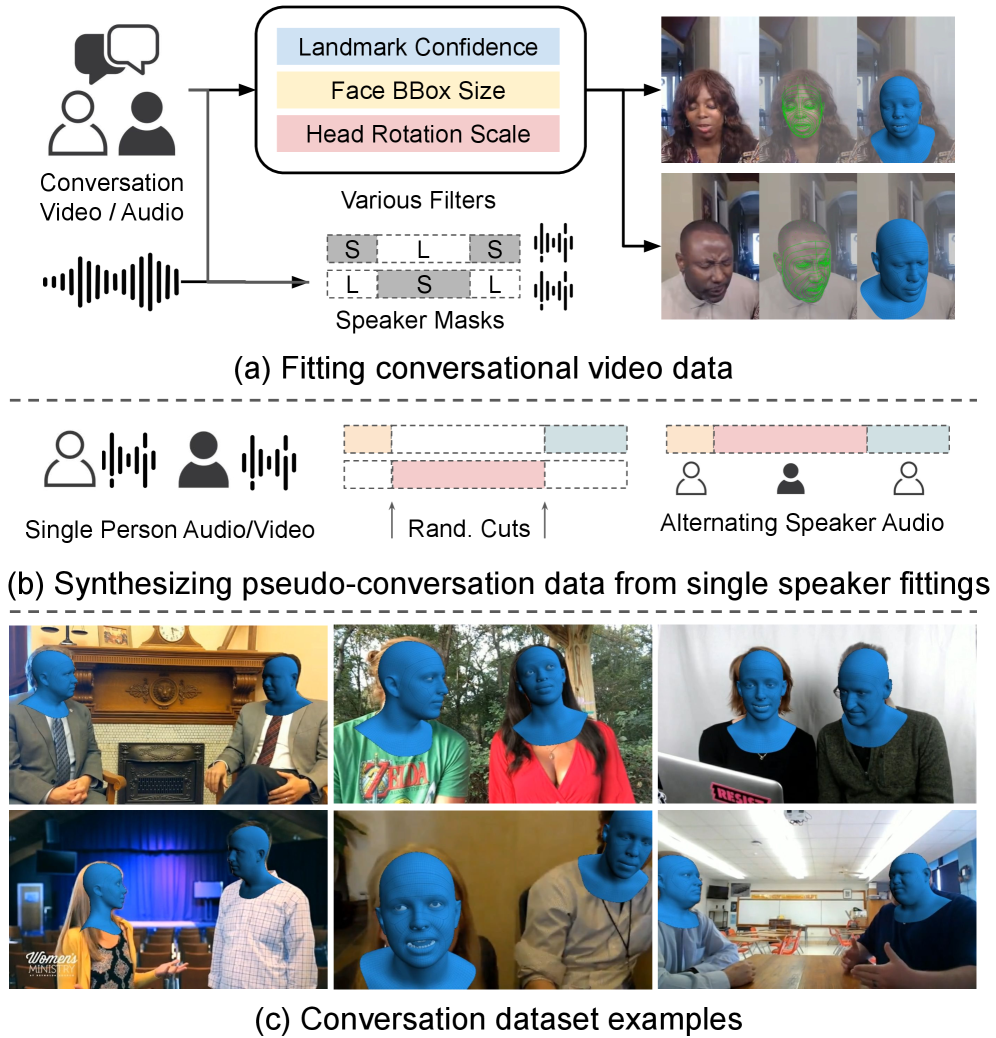
The dataset combines real dyadic videos with synthetic “pseudo-conversations” to create a robust training set.
Performance: Setting a New Benchmark
The model significantly outperforms existing approaches in realism and interaction quality. Key metrics include:
- Perceived Realism: Human evaluators rated the animations 20-30% more realistic than competing systems.
- Mutual Gaze Accuracy: Improved by over 40% due to the novel eye gaze loss.
- Lip-Sync Quality: Outperformed existing methods by 15% in lip movement synchronization.
Visual Results
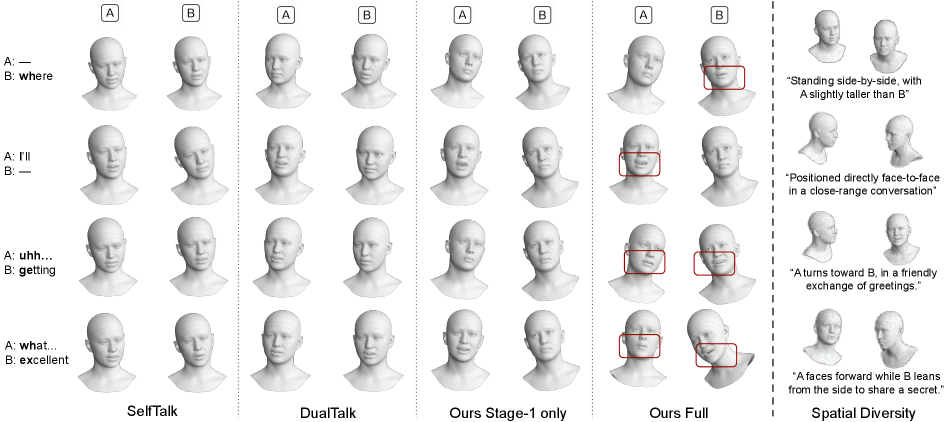
Left: Interaction quality comparison with baselines. Right: Adaptability to various spatial layouts.
Drone Applications: Why This Matters
While the research is focused on VR and telepresence, the implications for drones are intriguing. Here’s how this technology could be applied:
- Telepresence Drones: Drones could act as virtual avatars in remote meetings, complete with realistic facial expressions and mutual gaze.
- Interactive Tours: Imagine drones providing real-time, interactive guided tours, communicating as if they were physically present.
- Search and Rescue: In emergencies, drones equipped with this tech could facilitate clear, engaging communication with multiple people on the ground.
- Social UAVs: Swarm drones designed for human interaction could use this system to model natural conversational dynamics and spatial awareness.
Limitations and Challenges
No research is without its hurdles, and this study is no exception. Here are some of the key limitations:
- Hardware Constraints: The system requires significant computational power to generate 3D models in real-time. Lightweight drones would need advanced edge AI hardware to make this feasible.
- Audio Dependency: The model assumes clean audio input, but noisy environments—common for drones—could hinder performance.
- Dataset Bias: The training data is curated and synthetic, which may limit the model’s ability to generalize to real-world scenarios.
- Limited to Two Participants: The system is designed for dyadic interactions. Adapting it for group conversations or multi-drone contexts would require substantial modifications.
Can You Build This at Home?
For hobbyists, replicating this system is currently out of reach due to several factors:
- Hardware Requirements: The model relies on powerful GPUs and a U-Net-based architecture. Deploying it on a drone would require advanced edge AI modules like the
NVIDIA Jetson AGX Orin. - Dataset Access: The extensive dataset used for training is not publicly available, making it challenging to replicate the results.
- Code Availability: As of now, the authors have not released an open-source implementation.
However, related research, such as “Retrieval-Augmented Gaussian Avatars” and “Scale Space Diffusion,” might offer simpler alternatives for specific tasks like avatar generation or motion fidelity.
Related Work
This research builds on and complements other studies in the field:
- Retrieval-Augmented Gaussian Avatars: Focuses on improving expression generalization for 3D avatars without rigid templates, which could aid in drone-based telepresence.
- Scale Space Diffusion: Explores techniques for enhancing the fidelity of generated models through hierarchical noise reversal, potentially improving audio-to-3D pipelines.
- UNBOX: Investigates interpretability in vision models, which could be crucial for trust-critical applications like search and rescue.
Looking Ahead
While this research is primarily aimed at VR, its potential for drones is undeniable. The challenge lies in adapting the technology to be lightweight, robust, and capable of operating in real-world conditions. As edge AI continues to advance, the day when drones can communicate as naturally as humans may not be far off.
Paper Details
Title: Talking Together: Synthesizing Co-Located 3D Conversations from Audio
Authors: Mengyi Shan, Shouchieh Chang, Ziqian Bai, Shichen Liu, Yinda Zhang, Luchuan Song, Rohit Pandey, Sean Fanello, Zeng Huang
Published: 2023
arXiv: 2603.08674 | PDF
Final Thoughts
This research represents a significant step forward in audio-driven 3D modeling. While it’s not yet ready for drone applications, its potential to revolutionize communication and telepresence is clear. The next challenge is making it practical for real-world use cases.
Written by
The Flight DeskSharing knowledge about drones and aerial technology.
More from Mini Drone Shop
Stop Wandering: Metacognitive AI Makes Drones Smarter, Not Just Faster

Unmasking the Invisible: Polarization Powers Drone Camouflage Detection

Smarter Drone Comms: AI-Powered Beams Cut Through the Noise
