Beyond Labels: Drones Learn Movement from Generated Worlds
GenOpticalFlow introduces a novel generative approach to unsupervised optical flow learning, synthesizing high-quality motion data for training without human annotations. This method promises more adaptable and robust autonomous drone navigation.
TL;DR: Forget expensive, hand-labeled datasets.
GenOpticalFlowshows how drones can learn to 'see' and understand motion by training on entirely synthetic, perfectly aligned visual data. This generative approach makes autonomous flight systems smarter and more adaptable, without ever being explicitly taught by humans.
The Silent Language of Motion
For an autonomous drone to truly navigate, avoid obstacles, and perform complex tasks, it needs to understand more than just where objects are; it needs to grasp how they — and the drone itself — are moving. This fundamental understanding comes from optical flow: the apparent motion of objects, surfaces, and edges in a visual scene. It’s how a drone can track a moving target, anticipate a collision, or even stabilize its own flight in windy conditions. The challenge, historically, has been teaching drones this nuanced visual language.
The Annotation Bottleneck
Traditional computer vision models, particularly for optical flow, demand vast amounts of precisely labeled training data. This means painstakingly annotating pixel-level motion vectors across thousands of image pairs—a process that is not only prohibitively expensive and time-consuming but also prone to human error and difficult to scale. Manually tracking every pixel's movement in a high-resolution video stream is simply not practical for the diverse and dynamic environments drones operate in.
While unsupervised and semi-supervised methods have emerged to mitigate this annotation reliance, they often fall short. They typically depend on assumptions like brightness constancy (pixels don't change color between frames) and motion smoothness, which frequently break down in real-world scenarios involving lighting changes, reflections, occlusions, or rapidly moving objects. For a drone relying on this data for critical decisions, such inaccuracies can be the difference between a successful mission and a crash. We need a more robust way to generate reliable supervision without human intervention.
Building a Synthetic Reality for Learning
This is where GenOpticalFlow steps in with a genuinely clever solution. Instead of trying to extract optical flow from real-world data without labels (and thus making risky assumptions), they decided to generate the perfect training data from scratch. Think of it as creating a flawless simulated world where every piece of motion is known with absolute certainty. The core idea is to synthesize perfectly aligned frame-flow data pairs that can then be used for supervised training of an optical flow network, but critically, without any human annotations.
Here’s the high-level breakdown:
-
Pseudo
Optical FlowGeneration: The process starts with a pre-trained depth estimation network. This network analyzes a single image and predicts its depth map. From this depth map and a simulated camera movement, the system can mathematically derive apseudo optical flow— essentially, a perfect prediction of how pixels would move given that depth and camera motion. Thispseudo optical flowbecomes the 'ground truth' for their synthetic world.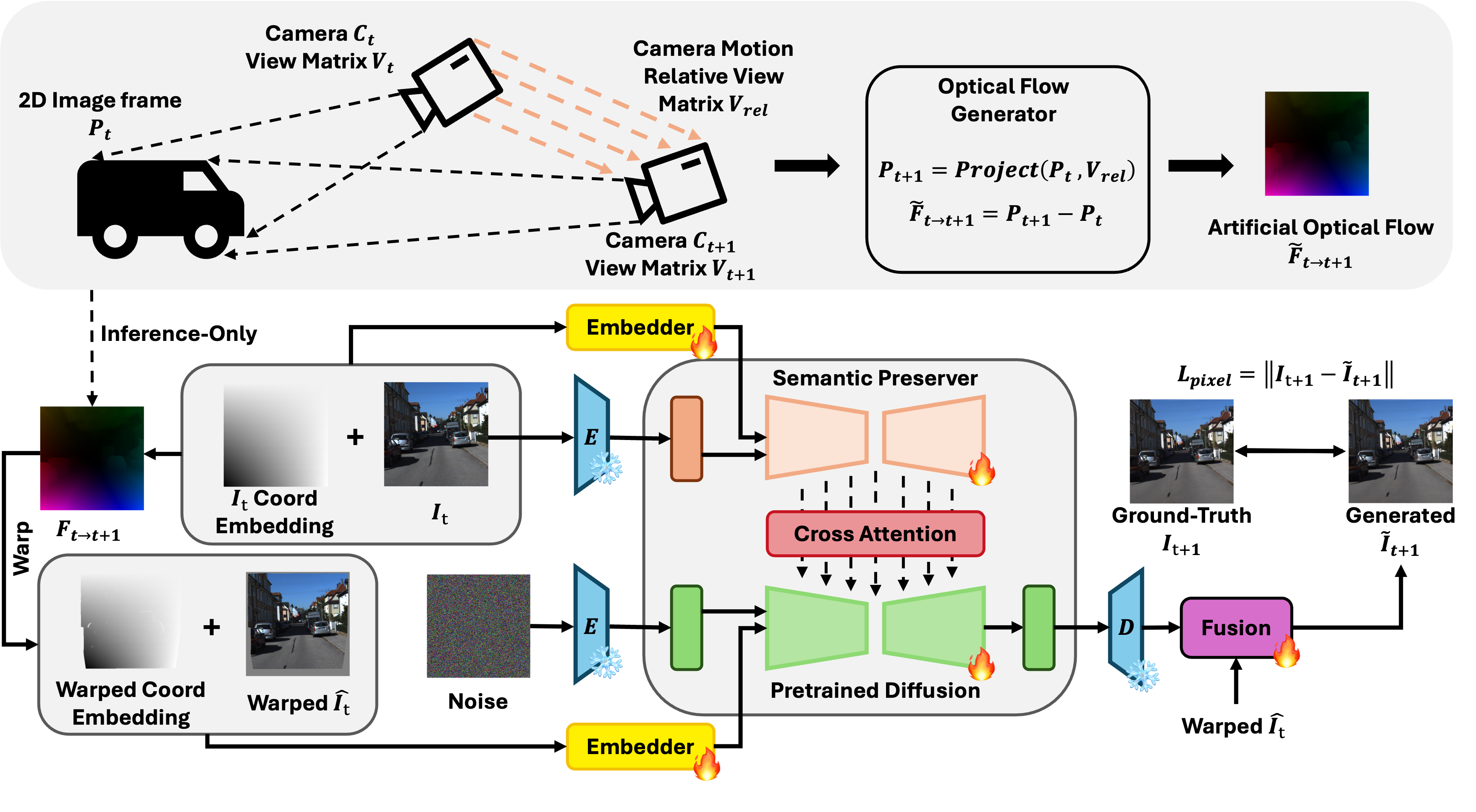
Figure 2: Overview of the conditioned next-frame framework and artificial
optical flowgeneration. Given an input view and its correspondingoptical flow, our framework constructs two types of embeddings: a 2D coordinate embedding of the input view and a warped coordinate embedding of the target view derived from theoptical flow. A semantic preserver network extracts high-level semantic features from the input view, while a diffusion model conditioned on these embeddings learns the geometric warping necessary to generate the novel view and accurately align pixel-level motion. To further enhance spatial correspondence, we augment the self-attention mechanism with cross-view attention and jointly aggregate features across views. Notably, ground-truthoptical flowis used only during pre-training, while synthetic datasets are constructed using artificialoptical flowproduced via a geometry-based camera-motion model. -
Conditioned Next-Frame Generation: With this
pseudo optical flowin hand, they train a sophisticated next-frame generation model, leveraging a diffusion architecture. This model takes an initial reference frame (I_t) and thepseudo optical flow(F~t→t+1) as inputs. Its task is to predict the subsequent frame (I~t+1) that perfectly matches the motion described by thepseudo optical flow. This creates a perfectly synchronized triplet: an initial frame, its corresponding ground-truth motion (thepseudo flow), and the next frame that perfectly embodies that motion.
Figure 1: Visualization of the synthesized data triplet on
KITTI2012, including the reference frameI_t, the artificially generatedoptical flowF~t→t+1, and the conditioned next-frame generation prediction resultI~t+1.This process allows
GenOpticalFlowto generate an essentially limitless supply of high-quality, pixel-aligned synthetic data. To make this data even more robust, they propose aninconsistent pixel filteringstrategy. This identifies and removes any unreliable pixels within the generated frames, ensuring that the final dataset is as clean and accurate as possible for training real-worldoptical flownetworks.
Figure 3: Qualitative results of
optical flowgeneration on theKITTI(top) andSintel(bottom) datasets. In each panel, the first row displays the conditioning input frame, while the second row visualizes a correspondingoptical flowmap randomly sampled from our model. The results highlight the model’s ability to generate dense, structurally aligned flow predictions across varying scene complexities.
Figure 4: Visualization of next-frame generation results. The figure demonstrates the temporal consistency of our method on the
KITTIandSintelbenchmarks. The top rows show the reference input frames, while the bottom rows display the synthesized next frames. Our framework effectively preserves texture details and object geometry during the generation process.
Performance: Outperforming the Unsupervised Pack
GenOpticalFlow isn't just a theoretical concept; it delivers on its promise. Extensive experiments on standard benchmarks like KITTI2012, KITTI2015, and Sintel demonstrate that the approach achieves competitive, and in many cases, superior results compared to existing unsupervised and semi-supervised optical flow methods. While specific numerical metrics aren't detailed in the abstract, the qualitative results shown in the figures clearly indicate dense, structurally aligned flow predictions across diverse scenes, from urban streets to complex indoor environments. This means the models trained on GenOpticalFlow's synthetic data are better at understanding motion than those trained using previous annotation-free methods.
Why It Matters for Autonomous Flight Systems
For drone enthusiasts, builders, and engineers, GenOpticalFlow represents a significant leap forward in creating smarter, more adaptable autonomous systems. Here’s why it matters:
- Unleashing Adaptability: Drones can now learn robust motion understanding in virtually any environment, simulated or real, without the need for manual data labeling. This opens the door for training specialized
optical flowmodels for niche applications—like navigating dense foliage or inspecting complex industrial structures—where ground-truth data is almost impossible to acquire. - Enhancing Robustness and Reliability: Better
optical flowdirectly translates to more stable flight control, precise object tracking, superior obstacle avoidance, and accurate state estimation (knowing where the drone is and how it's moving). This foundational improvement makes drones more reliable and safer in unpredictable real-world conditions. - Boosting Edge AI: By reducing the reliance on massive, pre-annotated datasets and enabling more efficient training,
GenOpticalFlowcontributes to the feasibility of deploying sophisticated AI on resource-constrained drone hardware. Smaller, more accurate models can run faster onNVIDIA JetsonorGoogle Coraldevices, making real-time autonomous decisions possible without offloading computation to the cloud. - Advanced Mapping and 3D Reconstruction: Accurate
optical flowis a cornerstone of Simultaneous Localization and Mapping (SLAM) and 3D reconstruction. With improved motion perception, drones can build more precise and geometrically consistent maps of their surroundings, essential for applications from aerial surveying to volumetric capture.
Real-World Hurdles and Future Skies
While GenOpticalFlow is a compelling step, it’s important to acknowledge the practicalities and remaining challenges:
- Generalization to Novel Scenarios: How well will models trained exclusively on synthetic data generalize to every conceivable real-world lighting condition, weather anomaly, or never-before-seen object? While the filtering strategy helps, real-world data diversity is immense.
- Computational Intensity: Generating this high-fidelity synthetic data, especially with diffusion models, is computationally demanding. While it shifts the burden from annotation to computation, it still requires significant GPU resources for training, making it less accessible for hobbyists without serious hardware.
- Reliance on Depth Estimation: The quality of the generated
pseudo optical flowis directly dependent on the accuracy of the initial pre-trained depth estimation network. Errors in depth will propagate into the synthetic motion data. - Dynamic Scene Complexity: While the method handles complex scenes, highly dynamic environments with rapid, unpredictable movements or significant occlusions might still pose challenges for perfectly accurate
pseudo optical flowgeneration.
Getting Your Hands Dirty: A DIY Perspective
For the ambitious hobbyist or research team, the prospect of GenOpticalFlow's code release is exciting. The paper states, "We will release our code upon acceptance," which is great news. However, replicating this full pipeline at home won't be a weekend project. It requires substantial GPU power (likely NVIDIA RTX 3090 or better) for both the depth estimation and the diffusion-based next-frame generation. Access to large-scale datasets for initial depth model pre-training would also be beneficial. While the core idea is accessible, the implementation and training would be a significant undertaking, leaning more towards academic or well-funded research groups than typical drone builders, at least initially.
Broader Implications: Contextualizing Motion
This work doesn't exist in a vacuum. Efficient optical flow is a critical component for many other emerging AI capabilities relevant to drones. For instance, the principles of WorldCache by Nawaz et al. show how content-aware caching can accelerate video world models, which directly benefits from accurate and fast optical flow for real-time prediction at the drone's edge. Similarly, VideoDetective by Yang et al. tackles long video understanding for Multimodal Large Language Models (MLLMs), where optical flow provides the fundamental motion data that these models would use to interpret events in extended drone footage. And in Repurposing Geometric Foundation Models by Jang et al., robust motion understanding is deemed essential for generating geometrically consistent 3D models and novel views, crucial for advanced drone mapping and spatial awareness tasks.
This isn't just about better optical flow; it's about a new paradigm for how autonomous systems acquire fundamental visual intelligence, pushing us closer to truly intelligent and independent drones.
Paper Details
Title: GenOpticalFlow: A Generative Approach to Unsupervised Optical Flow Learning
Authors: Yixuan Luo, Feng Qiao, Zhexiao Xiong, Yanjing Li, Nathan Jacobs
Published: Preprint (March 2026)
arXiv: 2603.22270 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.