Drones Get Smarter: LMMs Unlock Precision Object Interaction
Large Multimodal Models (LMMs) are upgrading drone capabilities beyond basic sensing. This review dives into how LMMs, combined with object-centric vision, enable drones to precisely understand, segment, edit, and generate visual data at an object level, moving towards truly intelligent aerial agents.
TL;DR: Large Multimodal Models (LMMs) are moving beyond general scene understanding to give drones object-level intelligence. This comprehensive review highlights how integrating LMMs with object-centric vision allows drones to precisely understand, segment, manipulate, and even generate visual content tied to specific objects, opening doors for highly interactive aerial operations.
From Dumb Cameras to Intelligent Eyes
For years, our drones have been incredible flying cameras. They capture stunning visuals, map environments, and perform inspections, but their understanding of what they're seeing has been largely superficial. They're great at identifying "a tree" or "a building," but struggle with "the specific branch I need to trim" or "that loose bolt on the antenna." A new wave of AI, specifically Large Multimodal Models (LMMs) coupled with object-centric vision, is changing that. This isn't just about better image recognition; it's about transforming drones into active, intelligent agents capable of nuanced interaction with their environment.
The Current Vision Blind Spot
Current drone vision systems, even those leveraging powerful AI, often hit a wall when tasks demand fine-grained detail. General-purpose vision-language models excel at broad understanding – "a drone flying over a city" – but falter on precise object-level grounding. They struggle with identifying a specific instance of an object amidst clutter, maintaining its identity across different views or interactions, or localizing and modifying designated regions with high precision. This limitation means drones remain reactive or semi-autonomous, requiring human oversight for complex manipulations. We need systems that can distinguish "this red wire" from "that red wire" and understand its context, not just detect "wires."
How LMMs Are Sharpening Drone Perception
The core idea is to move from holistic scene understanding to object-centric intelligence. LMMs, which combine large language models with visual processing, are being enhanced to explicitly represent and operate on individual visual entities. Think of it less like a drone taking a photo and more like it having a mental model of every distinct item it sees. This paper organizes the convergence of LMMs and object-centric vision into four critical capabilities: object understanding, object segmentation, object editing, and object generation.
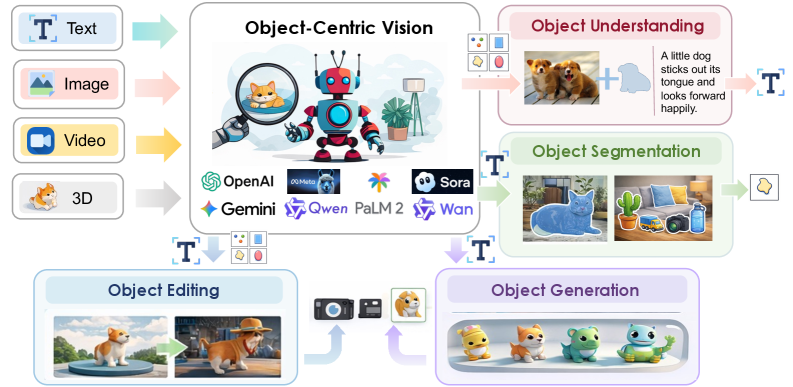
Figure 1: Overview of object-centric vision in the era of large multimodal models. The modalities considered in this paper include images, videos, and 3D data. Object-centric representations enable four fundamental capabilities: object understanding, object segmentation, object editing, and object generation.
For object-centric visual understanding, the goal is to make LMMs grasp the attributes, relationships, and functions of individual objects. This isn't just labeling; it's understanding why an object is there and what it does. The review highlights a spectrum of representative models that achieve these capabilities.
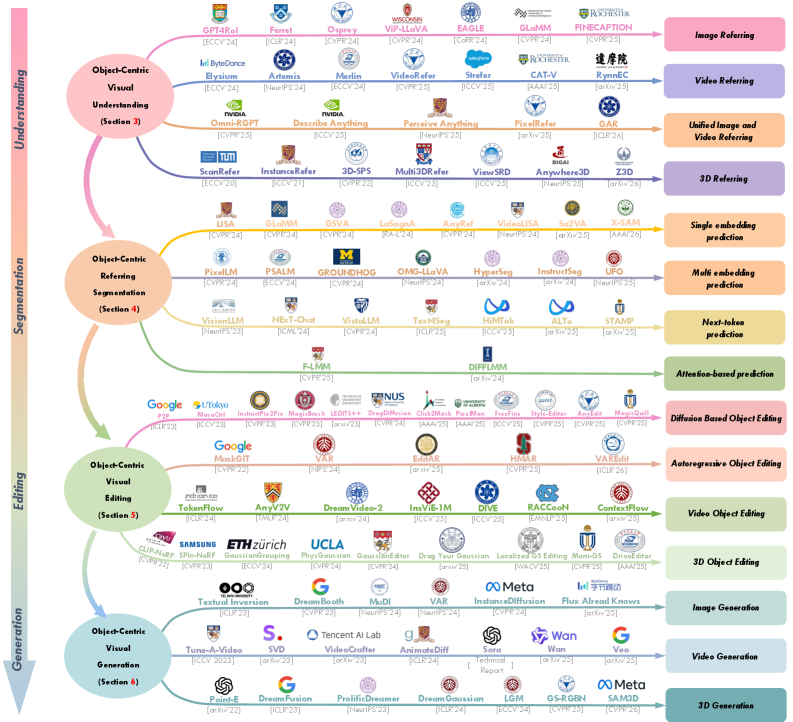
Figure 2: Summary of representative models spanning object-centric visual understanding, segmentation, editing, and generation. For a comprehensive list of related approaches, along with detailed discussions of their specifications, configurations, and technical aspects, please refer to Section 3, Section 4, Section 5, and Section 6, respectively.
When it comes to segmentation, LMMs are learning to precisely outline objects based on natural language queries, going beyond simple bounding boxes to pixel-perfect masks. Visual prompts play a huge role here, allowing different ways for an LMM to incorporate visual cues, whether as text, injected tokens, or fused directly with visual representations.
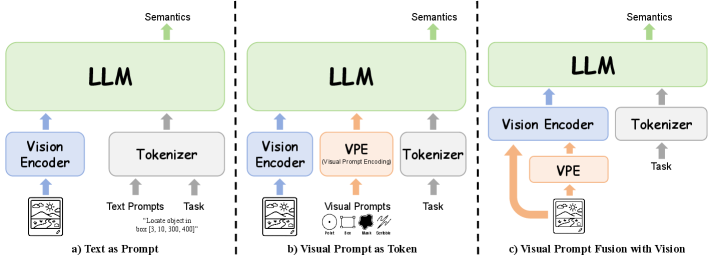
Figure 3: Illustration of three representative paradigms for incorporating visual prompts into multimodal large language models: Text as Prompt, Visual Prompt as Token, and Visual Prompt Fusion with Vision. These paradigms differ in whether visual prompts are expressed as language, injected as prompt tokens, or fused directly with visual representations before language modeling.
The review details how various language-pixel interfaces are being developed for this, from predicting single embeddings to attention-based spatial fields, each offering different levels of granularity and control for segmentation.
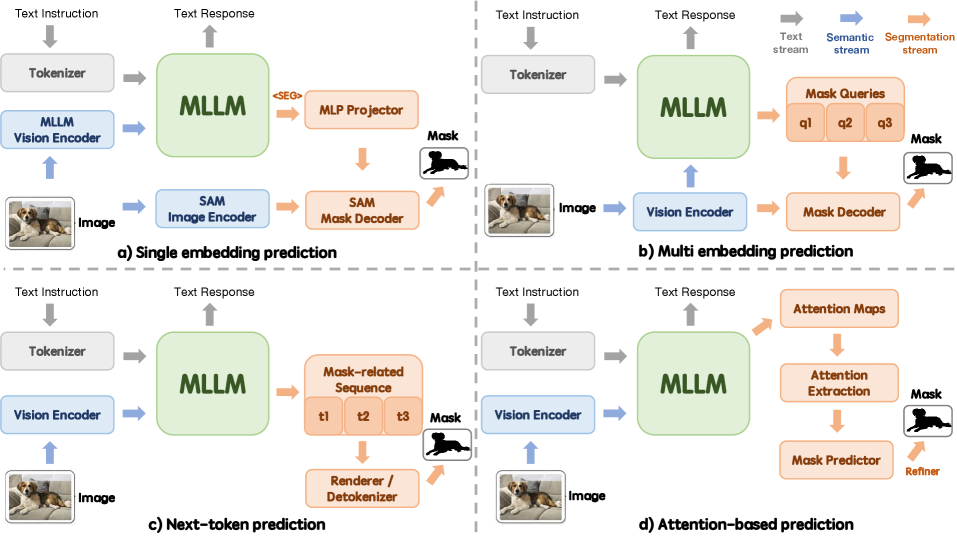
Figure 4: Four representative language–pixel interfaces for LMM-based object-centric referring segmentation: (a) single embedding prediction, (b) multi embedding prediction, (c) next-token prediction, and (d) attention-based prediction. They differ in whether the segmentation signal is expressed as one prompt embedding, multiple mask-aware queries, a generated mask-related sequence, or an attention-derived spatial field.
Beyond understanding and segmenting, LMMs are enabling object editing and generation. This means a drone could not only identify a damaged component but also conceptually "edit" it in its visual model or even "generate" a representation of how it should look. Advanced generative models achieve this, like diffusion models for 2D images, or 3D-aware models for geometry and texture modifications.
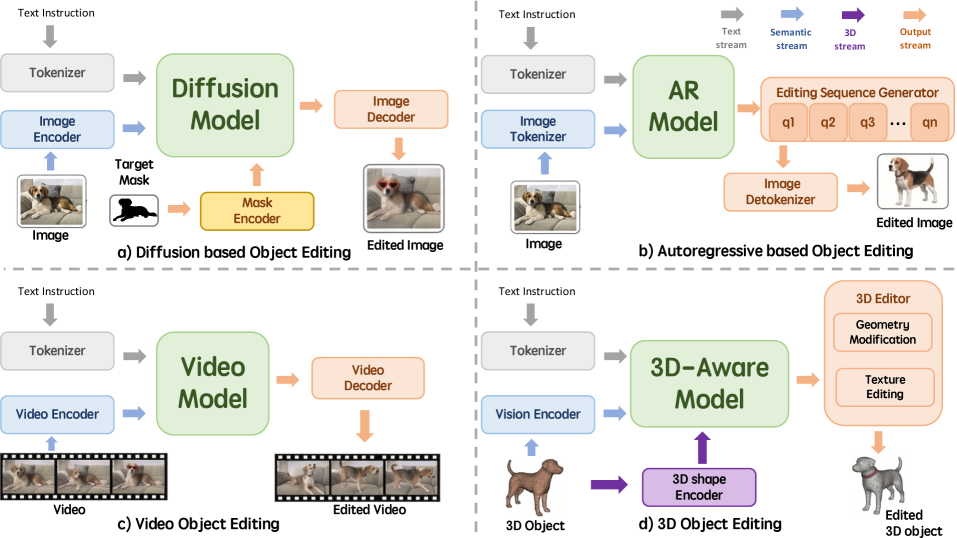
Figure 5: Four representative paradigms for generative model-based object editing: (a) Diffusion-based Object Editing, (b) Autoregressive-based Object Editing, (c) Video Object Editing, and (d) 3D Object Editing. They differ in their core generative mechanisms and target modalities, specifically utilizing diffusion processes for standard 2D images, autoregressive models to generate tokenized editing sequences, video models for temporal frame sequences, and 3D-aware models for geometry and texture modifications.
These generative capabilities extend to multimodal content creation, enabling the synthesis of new images, videos, and even 3D data based on complex prompts and object-centric understanding.
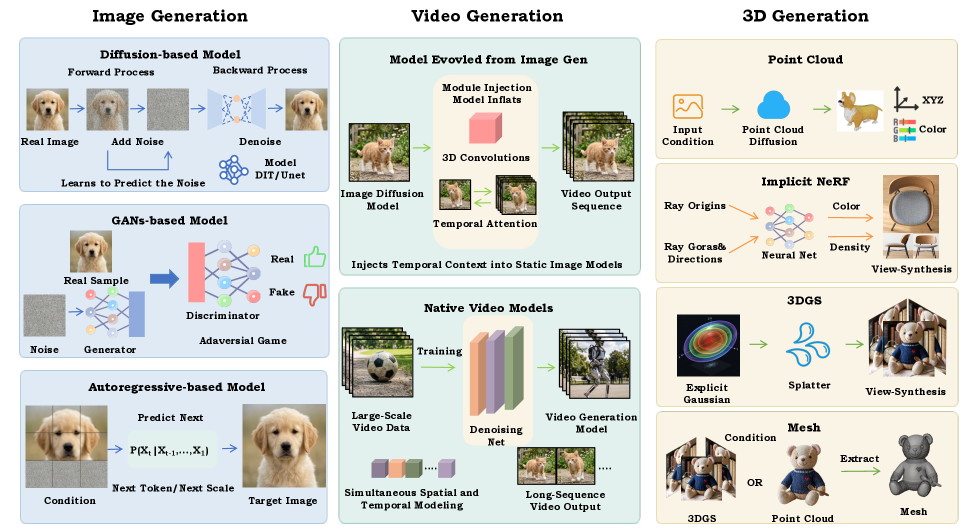
Figure 6: Overview of generative methodologies for multimodal content creation. The figure categorizes mainstream approaches for image, video, and 3D generation, highlighting the evolution from static 2D synthesis to complex spatial and temporal modeling.
These capabilities, detailed across various modeling paradigms and learning strategies, push the envelope from simple scene classification to intelligent, interactive manipulation.
The Impact of Object-Centric LMMs
While this paper is a review, the collective advancements it highlights point to a significant leap in visual AI. The capabilities described—object understanding, segmentation, editing, and generation—represent a shift from approximate, global scene comprehension to highly granular, instance-specific intelligence.
- Enhanced Precision: LMMs can now achieve pixel-level segmentation accuracy for objects specified by natural language, far surpassing traditional bounding box detection for tasks requiring fine manipulation.
- Semantic Depth: Models are moving beyond simple labels, inferring object attributes, states, and potential actions, which is critical for autonomous decision-making.
- Controllable Manipulation: The integration of generative models allows for not just understanding existing objects but also envisioning and manipulating their appearance or state, enabling sophisticated visual editing and synthesis.
- Bridging Modalities: The ability to seamlessly integrate visual prompts with language processing means instructions can be more intuitive and context-rich, making human-drone interaction significantly more natural and effective.
These advancements are not merely theoretical; they are driving the development of systems that can engage with the physical world in increasingly sophisticated ways.
What This Means for Drone Capabilities
This isn't just academic; it's foundational for the next generation of drone applications.
- Precision Inspection: A drone could identify a hairline crack on a specific turbine blade, not just "damage on a turbine." It could then track that crack over time, updating its internal 3D model with extreme fidelity.
- Automated Assembly & Repair: For automated assembly, a drone could be tasked with picking up and placing a specific component. With object-centric vision, it can precisely identify the target, understand its orientation, and execute the placement with fine-tuned control. This moves beyond simple pick-and-place to nuanced interaction.
- Environmental Interaction: For agriculture, a drone could identify individual diseased plants, segment them, and apply targeted treatment, rather than broad-stroke spraying. Or, in search and rescue, it could locate a specific piece of debris and guide ground teams with high spatial accuracy.
- Smart Surveillance: Instead of just detecting "a person," the drone could identify "the person in the red jacket carrying a backpack," and track them robustly even if they are partially obscured or change appearance slightly.
- Interactive Mapping: Drones could build highly detailed 3D models where individual objects are not just point clouds, but semantically understood entities that can be queried or manipulated.
This level of object-centric understanding is what bridges the gap from a drone being a sensor platform to a truly autonomous robotic agent.
The Road Ahead: Challenges and Hurdles
While the potential is immense, this field is far from mature. The paper acknowledges several significant challenges that need addressing for real-world deployment.
- Robust Instance Permanence: LMMs still struggle to consistently track and identify the same object instance across varying viewpoints, occlusions, and temporal changes. A drone needs to know if "the wrench" it saw a minute ago is the exact same wrench it's looking at now, even if its pose has changed.
- Fine-Grained Spatial Control: Translating object-centric understanding into precise physical actions is difficult. Knowing what an object is and where it is, is one thing; knowing how to grasp it and where exactly to place it requires even finer spatial reasoning and control.
- Consistent Multi-Step Interaction: Many real-world tasks involve a sequence of interactions. Maintaining object identity and context across these steps, especially when the environment changes, is a complex problem.
- Hardware Constraints: Running these sophisticated LMMs on drone hardware presents significant challenges. These models are computationally intensive and demand substantial memory and processing power, which directly impacts drone payload, battery life, and cost. Edge AI solutions are critical here.
- Reliable Benchmarking: With such diverse capabilities, developing standardized, robust evaluation protocols that truly reflect real-world performance under varying conditions is crucial.
Is This Within a Hobbyist's Reach?
Not yet, for full LMM deployment on a custom drone. These models are massive, typically requiring powerful GPUs (like NVIDIA A100 or H100 clusters) for training and even significant resources for inference. However, the foundational concepts and smaller, specialized models are accessible. Hobbyists can experiment with existing open-source object detection (YOLO, EfficientDet) and segmentation (SAM) models on platforms like Raspberry Pi or NVIDIA Jetson to build object-aware drone applications. The full, unified LMM approach, as described, is currently the domain of well-funded research labs and industry giants. We'll likely see quantized or distilled versions suitable for edge devices in the coming years.
Building on the Foundation: Related Innovations
The push for intelligent, interactive drones relies on advancements across multiple AI and robotics domains. This paper reviews the high-level LMM integration, but specific challenges are being tackled by other researchers. For instance, the ability to precisely place an object once an LMM has identified it is critical. A paper by He et al., "Disentangled Point Diffusion for Precise Object Placement," directly addresses this, offering methods for high-precision robotic manipulation. This bridges the gap from an LMM's intelligent perception to accurate physical action, a necessary step for drones that do more than just observe.
Furthermore, for LMMs to provide reliable object grounding, the underlying visual perception must be robust. Nordström et al.'s work, "Who Handles Orientation? Investigating Invariance in Feature Matching," delves into making feature matching more stable under challenging conditions like large in-plane rotations, which is paramount for a drone's stable localization and mapping in dynamic environments. And as drones start building and interacting with complex 3D models of their surroundings, the quality of those reconstructions becomes paramount. Li et al.'s "SyncFix: Fixing 3D Reconstructions via Multi-View Synchronization" offers a method to ensure the consistency and accuracy of 3D reconstructions, providing a more reliable spatial foundation for LMMs to operate on. These complementary efforts are all essential pieces of the puzzle for truly intelligent aerial robotics.
The Future of Interactive Drones
The convergence of LMMs and object-centric vision isn't just an incremental improvement; it's a fundamental shift in how drones will perceive and interact with the world. We're moving from drones that merely see to drones that understand, opening up a future where your aerial companion is not just a tool, but an intelligent agent capable of complex, precise tasks. The next few years will dictate how quickly this research translates into tangible capabilities for your next drone build.
Paper Details
Title: LMMs Meet Object-Centric Vision: Understanding, Segmentation, Editing and Generation Authors: Yuqian Yuan, Wenqiao Zhang, Juekai Lin, Yu Zhong, Mingjian Gao, Binhe Yu, Yunqi Cao, Wentong Li, Yueting Zhuang, Beng Chin Ooi Published: Preprint (April 2026) arXiv: 2604.11789 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.