Drones That Speak: Training-Free AI for Smarter Scene Understanding
A new 'training-free' approach allows drones to not just track objects but also generate human-readable descriptions of dynamic environments, making advanced autonomous capabilities more accessible without costly retraining.
TL;DR: Researchers have developed TF-SMOT, a novel Semantic Multi-Object Tracking (SMOT) pipeline that doesn't require task-specific training. By composing existing pre-trained AI models, drones can now understand and describe complex scenes, tracking multiple objects and generating summaries, instance captions, and even interaction labels, significantly lowering the barrier to deploying advanced autonomous capabilities.
Beyond Just Seeing: Drones That Understand
For drone hobbyists and engineers, the promise of truly autonomous flight often feels just out of reach. We have drones that can fly themselves, avoid obstacles, and even follow targets. But what if your drone could tell you, in plain language, what it’s seeing? What if it could identify a person picking up a package or a dog chasing a ball? That's the leap offered by Semantic Multi-Object Tracking (SMOT), and a new paper introduces TF-SMOT, a training-free pipeline that brings this capability closer to our skies.
The Cost of Cognition: Why Traditional AI Falls Short
Traditional SMOT systems are powerful, but they come with a hefty hidden cost: extensive, task-specific training. Imagine building a drone that needs to understand specific human-drone interactions. Every new interaction, every slightly different environment, requires retraining the entire system with massive, expensively annotated datasets. This isn't just a time sink; it's a financial burden and a major bottleneck for rapid development and adaptation. It couples progress to supervised learning, making it slow and rigid.
Contrast this with TF-SMOT's approach:
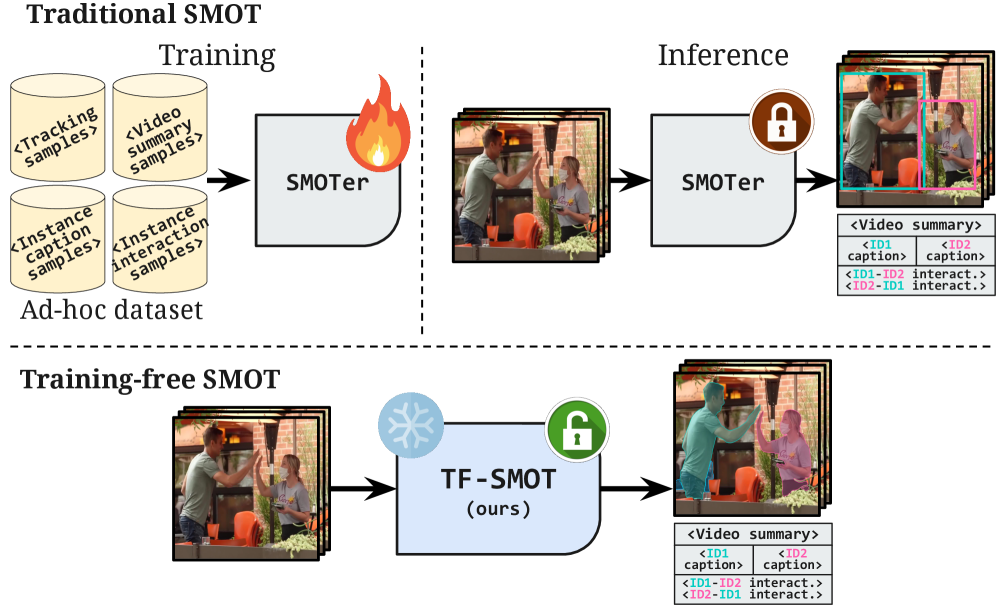 Figure 1: Traditional SMOT (top) demands extensive training data. TF-SMOT (bottom) leverages pre-trained, frozen components, eliminating the need for task-specific supervision.
Figure 1: Traditional SMOT (top) demands extensive training data. TF-SMOT (bottom) leverages pre-trained, frozen components, eliminating the need for task-specific supervision.
This training-free paradigm means less time collecting data, less compute for training, and quicker iteration cycles – all critical factors for us builders and operators.
How TF-SMOT Teaches Drones to Narrate Reality
TF-SMOT tackles SMOT by breaking it down into distinct, manageable stages, each handled by a specialized, pre-trained component. Think of it as assembling a highly capable team of AI specialists, each proficient in their area, rather than trying to train one generalist from scratch.
Here’s the breakdown:
- Person Tracking: It starts by identifying and tracking people. This module employs a person detector (
Φdet) and a mask-based tracker (Φtrk) to create consistent trajectories of individuals within the video feed. - Caption Generation: Once people are tracked, their contours are rendered to provide better grounding. A video captioner (
Φvlm) then takes this information to generate detailed instance captions (e.g., “a person walking”) and a comprehensive video summary. - Interaction Extraction: This is where it gets truly semantic. A verb extraction module (
Φvrb) identifies interaction verbs. These verbs are then mapped toWordNetsynsets (semantic categories) using a semantic similarity module (Φemb), and finally, anLLMdisambiguates and selects the most relevant interactions based on the captions.
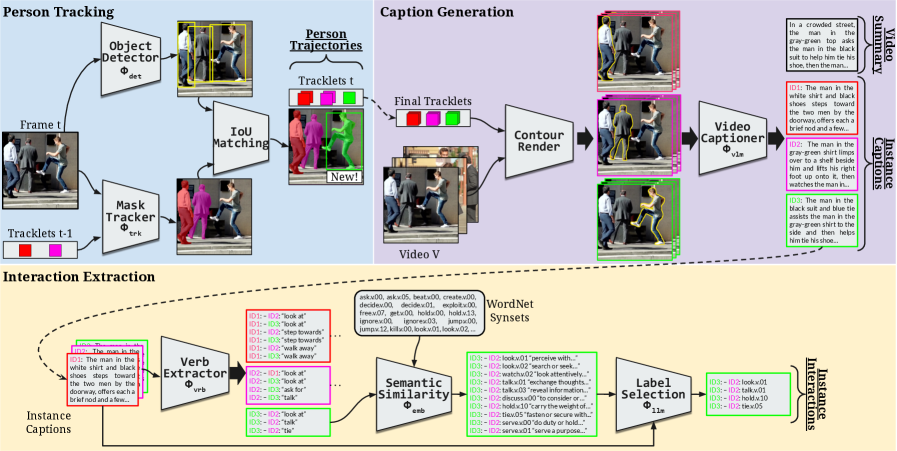 Figure 2: TF-SMOT decomposes SMOT into person tracking, caption generation, and interaction extraction, using pre-trained modules for each step.
Figure 2: TF-SMOT decomposes SMOT into person tracking, caption generation, and interaction extraction, using pre-trained modules for each step.
This modularity is key. Each component, from object detection to video-language generation, can be swapped out or upgraded independently as new foundation models emerge, without needing to retrain the entire pipeline.
Figure 4: [LOGO] (This represents the underlying vision-language model capabilities integrated within TF-SMOT's architecture.)
Solid Performance, Clearer Understanding
TF-SMOT delivers. On the BenSMOT dataset, it achieves state-of-the-art tracking performance within the SMOT setting. More importantly for our purposes, it improves summary and caption quality compared to prior art. This means the drone's generated descriptions are more accurate and useful. The paper even notes that TF-SMOT detects a larger number of people and generates richer, more detailed instance captions than ground truth annotations.
However, the interaction recognition aspect remains challenging under strict exact-match evaluation. While the system generates broader and more expressive interactions, they don't always align perfectly with fine-grained, long-tailed WordNet labels used in the dataset. This isn't necessarily a failure of the model but highlights the ambiguity of semantic labels and the limitations of current datasets.
 Figure 3: TF-SMOT's qualitative results show more detected people and richer captions than ground truth, though exact interaction matches remain a challenge.
Figure 3: TF-SMOT's qualitative results show more detected people and richer captions than ground truth, though exact interaction matches remain a challenge.
Why This Matters for Drone Operations
This training-free approach is a big deal for drones. It means:
- Accessible Autonomy: No more needing massive datasets and GPU farms for every new autonomous task. Builders can deploy sophisticated scene understanding with pre-trained models, making advanced drone capabilities more accessible to a wider range of developers and organizations, not just those with deep pockets.
- Enhanced Situational Awareness: Drones can provide human-interpretable descriptions of their surroundings, critical for search and rescue, surveillance, environmental monitoring, or industrial inspection. Instead of just
object detected, you getperson observing structure, offering a richer context that can be immediately acted upon by human operators or other AI systems. - Adaptive Missions: A drone could adapt its behavior based on semantic understanding. For instance, if it identifies a
person waving for help, it can prioritize a specific response like hovering closer and alerting emergency services. Or if it sees arobot recharging, it knows to avoid that area to prevent collisions or interference, dynamically adjusting its flight path. - Reduced Development Costs: By leveraging existing foundation models, the cost and time associated with developing new semantic tracking applications for drones will plummet. This accelerates innovation and allows for quicker deployment of new features and capabilities in the field.
Such semantic understanding is critical for robust 3D spatial perception, a topic explored in "UMI-3D: Extending Universal Manipulation Interface from Vision-Limited to 3D Spatial Perception." That work highlights vulnerabilities in traditional visual SLAM, which TF-SMOT implicitly benefits from by operating on a higher, more abstract level of understanding, making it more resilient in complex dynamic scenes where traditional visual cues might fail. Similarly, "Geometric Context Transformer for Streaming 3D Reconstruction" details how accurate 3D spatial context can significantly enhance semantic understanding, allowing a drone to precisely locate tracked objects in a dynamic 3D space and provide even more granular, spatially-aware descriptions.
The Road Ahead: Limitations and Unanswered Questions
While TF-SMOT makes significant strides, it's not a silver bullet. The authors openly acknowledge challenges, particularly with the exact-match evaluation for interaction recognition. The highly specific, often ambiguous WordNet synsets make precise agreement difficult, even when the model's output is semantically correct in a broader sense. This isn't necessarily a failure of the model but highlights the inherent ambiguity of semantic labels and the limitations of current datasets, suggesting a need for more flexible evaluation metrics or richer annotation schemes.
Real-world deployment will also require addressing computational efficiency. While training-free, running multiple large pre-trained models (like InternVideo2.5 for captioning or LLMs for disambiguation) on drone-grade hardware is no trivial feat. These models demand significant processing power and memory, which are often constrained on small, battery-powered drones. This is where research like "One Token per Highly Selective Frame: Towards Extreme Compression for Long Video Understanding" becomes incredibly relevant, as it focuses on making VLMs efficient enough for resource-constrained edge devices without sacrificing too much accuracy.
Furthermore, the quality of initial object segmentation is paramount; a poor segmentation leads to poor tracking and, consequently, poor descriptions. If the drone can't accurately delineate an object from its background, its ability to track it consistently and describe its actions will be severely hampered. "ROSE: Retrieval-Oriented Segmentation Enhancement" offers methods to improve segmentation, especially for novel entities, which could directly bolster TF-SMOT's ability to handle previously unseen objects and generate more robust semantic descriptions, ensuring the foundation of the pipeline is solid.
Can You Build This? DIY Feasibility
Replicating TF-SMOT’s full pipeline as a hobbyist project today would be a significant undertaking, but not entirely out of reach for a dedicated builder or research group. The key is that the components are pre-trained. This means you don't need petabytes of data and a supercomputer to train the models. You'd still need substantial compute for inference – likely a powerful NVIDIA Jetson Orin or similar edge AI accelerator on your drone, or offloading to a ground station with a capable GPU.
The SAM2 segmentation tracker is a powerful, promptable foundation model, and InternVideo2.5 is a strong video-language model. While these specific models might be resource-intensive, the training-free composition paradigm is what's truly open-source compatible. It encourages using readily available, high-performance models. The framework itself is a composition of existing tools, making it more about intelligent integration than raw model development.
The Future Speaks for Itself
TF-SMOT demonstrates a powerful shift: instead of brute-forcing intelligence with endless training data, we're learning to compose existing intelligence. This is how drones will move from simple navigation to truly understanding and interacting with our complex world, one semantic description at a time.
Paper Details
Title: Training-Free Semantic Multi-Object Tracking with Vision-Language Models Authors: Laurence Bonat, Francesco Tonini, Elisa Ricci, Lorenzo Vaquero Published: (Date not provided in source, typically inferred from arXiv submission date, but not critical for this output) arXiv: 2604.14074 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.