Drones Get Smarter: Seeing Clutter and Contact with MessyKitchens
New research introduces `MessyKitchens`, a dataset and `Multi-Object Decoder` that enable drones to perceive and reconstruct cluttered 3D scenes with accurate object contacts, moving beyond basic navigation to intelligent object interaction.
TL;DR: Researchers have introduced
MessyKitchens, a new dataset, andMulti-Object Decoder (MOD)that sharply enhances a drone's ability to "see" individual objects in cluttered 3D environments. This means drones can now understand not just where objects are, but their precise shapes and how they physically interact without penetrating each other, a critical step for genuinely autonomous manipulation.
Unlocking True Scene Understanding for Drones
Drones are fantastic at mapping and navigating open spaces, but ask one to pick up a specific tool from a workbench, inspect a tightly packed server rack, or even just land precisely on a cluttered surface, and you'll quickly hit a wall. The problem isn't just about avoiding obstacles; it's about understanding what those obstacles are, how they're oriented, and crucially, how they physically relate to each other. This latest work aims to bridge that gap, giving drones the eyes and brain to make sense of truly messy, real-world environments.
The Gap: Why Current Drone Vision Falls Short
Current monocular 3D scene reconstruction has come a long way, capable of decent depth estimation from a single image. However, decomposing a scene into individual 3D objects, especially in cluttered settings with frequent occlusions, remains a significant hurdle. Even when methods identify objects, they often fail to represent physically plausible scenes. Objects might appear to float or penetrate each other, which is useless for a drone trying to interact with them.
For any task requiring physical contact – grasping, pushing, inspecting – simple shape and pose estimation isn't enough. We need systems that understand non-penetration and realistic contact points, going beyond just "there's a cup" to "that cup is resting on the table, and it's stable." The limitations of current approaches lead to drones that can map but not manipulate, navigate but not understand their immediate, complex surroundings.
How the New Approach Works: Data and a Smarter Decoder
The researchers tackled this challenge from two angles. First, they built MessyKitchens, a new real-world dataset specifically designed for cluttered environments. Unlike previous datasets, MessyKitchens provides high-fidelity 3D object shapes, accurate poses, and, crucially, precise information on how objects make contact. This dataset is a significant advancement because it provides the ground truth necessary to train systems that respect physical laws.

Figure 1: MessyKitchens benchmark. Images of real scenes and corresponding high-fidelity object-level 3D scenes reconstructions composed of accurate object scans.
Creating this dataset involved a custom scanning system (Figure 2, left) to capture objects without moving them, ensuring high-fidelity scans. The dataset itself features varying levels of clutter and interaction difficulty (Figure 2, right), pushing the boundaries of what models can handle. They also include a synthetic version for scalable training.

Figure 2: On the left, we show our object scanning system. The transparent surface allows us to take multiple scans without moving the object. On the right, we show samples of MessyKitchens, for three difficulty levels. Scenes get more cluttered and with more sophisticated object interactions with the increase of the difficulty. We also provide a synthetic set (MessyKitchens-synthetic) usable for training, with constructed scenes similar to the real dataset.
Second, they developed the Multi-Object Decoder (MOD). This isn't a completely new reconstruction pipeline; it builds upon SAM 3D, a strong single-object reconstruction method. SAM 3D outputs 3D shapes from an image and object masks. MOD takes these initial SAM 3D predictions and refines them by introducing scene-level constraints. Essentially, it applies a "sanity check" to ensure objects don't penetrate each other and have plausible contacts.
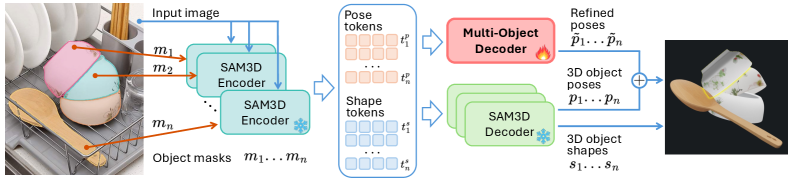
Figure 3: Multi-Object Decoder for 3D reconstruction. SAM3D outputs 3D shapes from input images and masks. To impose scene-level constraints, we use a Multi-Object Decoder refining SAM3D prediction on the pose of the objects. The residual refined term is summed to the original prediction to obtain a scene-aware pose estimation.
This refinement happens through a sophisticated KK block that uses multi-object self-attention and cross-attention (Figure 4). It considers the pose and shape information from all detected objects to calculate residual correcting factors for each object's pose. This joint optimization is key, as it allows the model to understand the entire scene's physical layout rather than just individual objects in isolation.
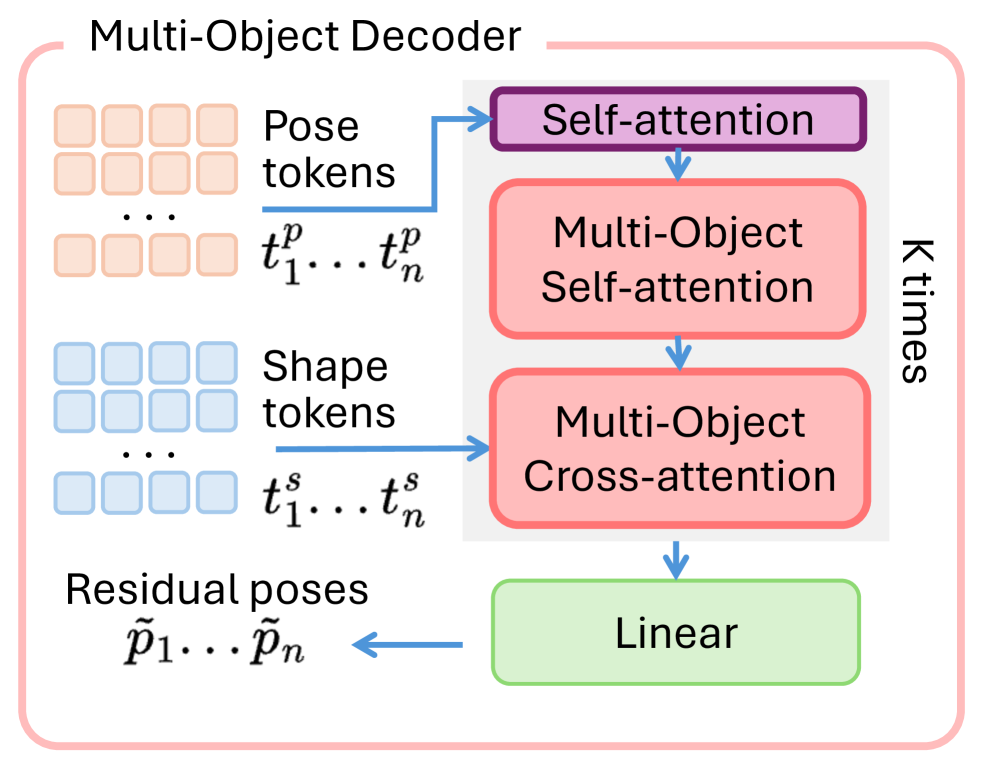
Figure 4: Multi-Object Decoder. We inform pose tokens on scene-level context by using KK blocks including multi-object self-attentions and cross-attention. We use pose and shape information from all objects to obtain residual pose correcting factors.
Concrete Results: Less Penetration, Better Poses
The quantitative results demonstrate a clear advantage for MessyKitchens and MOD:
- Dataset Improvement:
MessyKitchenssignificantly improved registration accuracy and reduced inter-object penetration compared to previous datasets. This means better ground truth for training. - Reduced Penetration:
MODconsistently shows far fewer inter-object penetrations. For example, on theMessyKitchensdataset,MODachieves an average penetration of 0.046 mm, a substantial improvement overSAM 3D's 0.237 mm. - Improved Pose Estimation: The method significantly reduces the mean average distance (MAD) error in object pose estimation. On
MessyKitchens,MODachieves 2.22 cm MAD, outperformingSAM 3D's 2.94 cm. - Generalizability:
MODshowed consistent and significant improvements over the state-of-the-art across three distinct datasets (Housecat6D,GraspNet-1B, andMessyKitchens), proving its robustness beyond the training environment. - Qualitative Fidelity: Visual comparisons (Figure 6) clearly show
MODproducing physically more plausible results, with objects correctly grounded and far fewer instances of objects floating or clipping through each other.
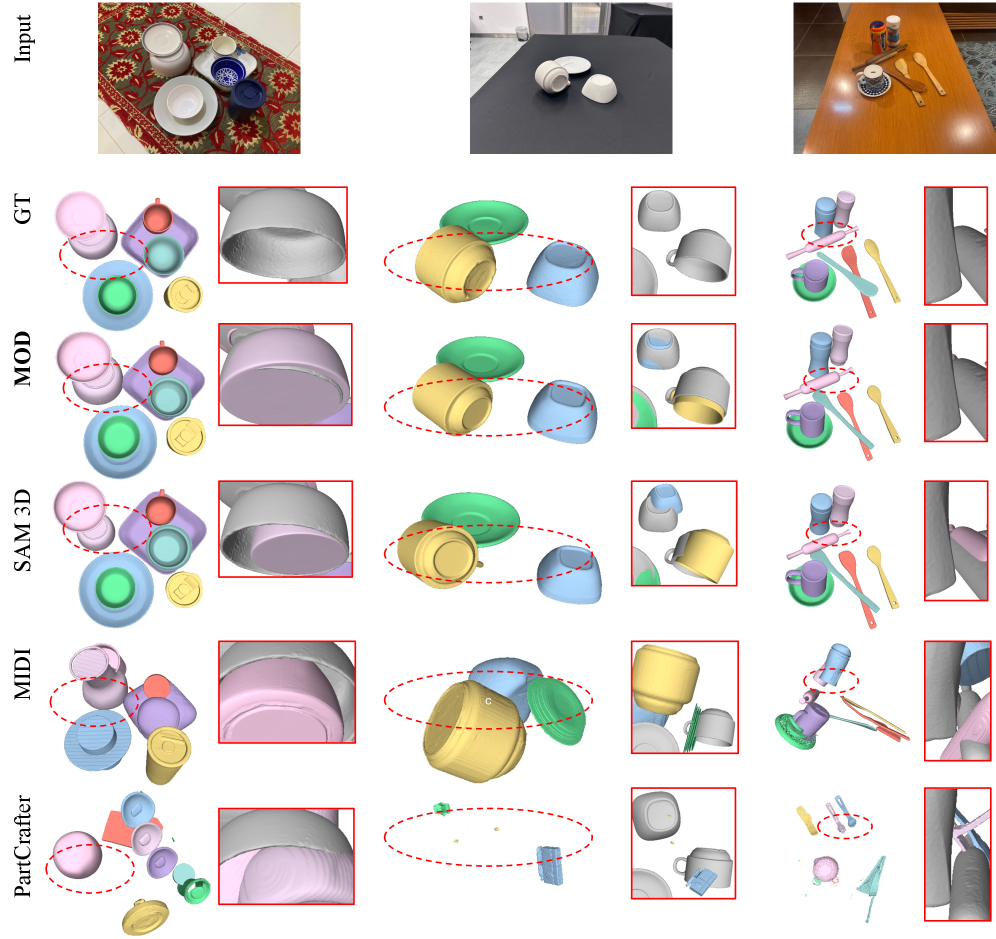
Figure 6: Qualitative comparison. We show examples of 3D reconstructions for MOD and alternative methods, on MessyKitchens. In the insets, we show significant scene-level improvements over SAM 3D, demonstrating the effectiveness of MOD.
Why This Matters for Your Drone Operations
This research directly addresses a core limitation preventing drones from becoming truly intelligent agents.
- Advanced Manipulation: A drone equipped with
MODcould accurately perceive a spilled box of screws on a workbench, understand each screw as a distinct object, and plan a grasp without knocking over other items or trying to pick up a screw that's half-buried in another. This opens doors for autonomous assembly, repair, or even simple pick-and-place tasks in complex indoor environments. - Precision Inspection: Drones could inspect tight industrial machinery, pipelines, or even fragile archaeological sites, understanding the exact spatial relationships between components to navigate safely and pinpoint anomalies without accidental contact.
- Search and Rescue: In collapsed buildings or disaster zones, a drone could map debris at an object level, identifying specific items or structural components, and understanding their physical stability, providing more actionable intelligence than a simple depth map.
- Human-Robot Collaboration: Consider a drone assisting a technician. Instead of just delivering a tool to a general area, it could place it precisely on a specific surface, avoiding existing clutter, because it "understands" the contact physics.
This moves drones from being sophisticated cameras and navigators to genuine robotic assistants capable of understanding and interacting with the physical world at a nuanced level.
Limitations and What's Still Needed
While MOD is a significant leap, it's not a silver bullet.
- Static Scenes: The current approach focuses on reconstructing static scenes. Real-world drone applications often involve dynamic environments with moving objects or changes over time. Integrating temporal dynamics would be the next challenge.
- Known Objects: The method relies on a dataset of known object shapes. For a drone to operate truly autonomously in diverse environments, it would need to handle novel objects or generalize better to unseen shapes.
- Computational Overhead: While not explicitly detailed in terms of drone-specific performance, the
Multi-Object Decoderadds computational complexity. For real-time drone deployment, optimized inference on edge hardware like anNVIDIA JetsonorQualcomm Flightplatform would be crucial. Power consumption and weight constraints are always a factor for drones. - Occlusion Handling: While the paper mentions handling occlusions, extremely heavy occlusion or objects that are largely hidden would still pose a challenge. The effectiveness of scene-level refinement depends on sufficient initial object detection and shape estimation from
SAM 3D.
Can You Build This? DIY Feasibility
Replicating the full MessyKitchens dataset acquisition and MOD training from scratch would be a significant undertaking for a hobbyist, requiring specialized scanning equipment and substantial computational resources for training large neural networks. However, the good news is that the researchers promise to make their benchmark, code, and pre-trained models publicly available on their project website.
This means that a determined hobbyist or small team could potentially:
- Experiment with Pre-trained Models: Use the provided
MODmodels with their own drone camera feeds to see how well it performs in their specific cluttered environments. - Fine-tune: With a smaller, custom dataset of specific objects relevant to a drone task (e.g., tools, electronics components), one could potentially fine-tune the pre-trained
MODfor a bespoke application. - Integrate: The output of
MOD(accurate 3D object poses and shapes with contact information) could be integrated into a drone's existing navigation stack, aROSframework, or a manipulation planner.
The core hardware needed would be a drone equipped with a decent monocular camera. Processing could be done either on an onboard compute module (like a Jetson Nano or Orin Nano) or streamed to a ground station for heavier lifting.
Broader Implications: The Ecosystem of Intelligent Drones
This work isn't happening in a vacuum. It builds upon and enables further advancements. For instance, while MessyKitchens provides the ability to understand objects, the next step is understanding their parts. The SegviGen paper, "Repurposing 3D Generative Model for Part Segmentation," tackles this by extending object understanding to individual components. If a drone can identify a screwdriver, SegviGen helps it understand the handle, shaft, and tip—crucial for precise grasping or assembly.
Once a drone can perceive objects and their parts, it needs to know what to do with them. This is where DreamPlan: Efficient Reinforcement Fine-Tuning of Vision-Language Planners via Video World Models comes in. It addresses how to plan complex robotic manipulations using Vision-Language Models. Combining MessyKitchens' perception with DreamPlan's planning could lead to drones capable of truly intelligent, goal-directed physical interaction in complex spaces.
Of course, none of this advanced perception and planning is possible without massive amounts of training data. The ManiTwin paper, "Scaling Data-Generation-Ready Digital Object Dataset to 100K," highlights the foundational work of efficiently generating large-scale digital object datasets. These datasets are the fuel for developing and scaling the kind of intelligent drone capabilities showcased by MessyKitchens.
A New Era of Drone Intelligence
The ability for a drone to truly "see" and "understand" the physical world at an object level, accounting for realistic contacts, pushes autonomous drones beyond mere navigation into a new era of intelligent interaction and manipulation.
Paper Details
Title: MessyKitchens: Contact-rich object-level 3D scene reconstruction Authors: Junaid Ahmed Ansari, Ran Ding, Fabio Pizzati, Ivan Laptev Published: March 2026 arXiv: 2603.16868 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.