Drones That Think: Real-time VideoLLMs for Proactive Autonomy
A new VideoLLM paradigm, Video Streaming Thinking (VST), enables drones to 'watch and think' simultaneously, amortizing reasoning latency across video streams for true real-time understanding and decision-making.
TL;DR: A new VideoLLM paradigm, Video Streaming Thinking (VST), allows drones to "watch and think" simultaneously. By performing reasoning over incoming video clips during streaming, VST drastically reduces decision latency, moving drones beyond mere perception to real-time, proactive understanding of their environment.
Beyond Just Seeing: Drones That Reason
For years, drones have excelled at seeing. They capture stunning aerial footage, survey vast landscapes, and provide critical visual data. But what if your drone could do more than just see? What if it could think – actively process, reason about, and understand its environment in real-time, making intelligent decisions as it flies? This isn't just about faster object detection; it's about true cognitive autonomy. New research on "Video Streaming Thinking" (VST) brings us a significant step closer to this reality, enabling Video Large Language Models (VideoLLMs) to watch and reason concurrently.
The Bottleneck of Reactive AI
Current online VideoLLMs are good at streaming perception – processing visual data as it comes in. However, they hit a wall when it comes to synchronized logical reasoning. Traditional approaches either perform minimal reasoning to maintain speed, or they apply heavy, step-by-step reasoning after the video stream or query. That post-query processing, often called Chain-of-Thought (CoT) reasoning, introduces unacceptable response latency.
For a drone navigating a complex environment or performing a critical inspection, waiting for the LLM to "think" after seeing something is a non-starter. Decisions need to be instant, proactive, and integrated with ongoing perception, not a reactive afterthought. This gap limits drones to either simple reactive behaviors or computationally expensive, off-board processing, which isn't viable for true autonomy at the edge.
The “Thinking While Watching” Breakthrough
Video Streaming Thinking (VST) tackles this by introducing a "thinking while watching" mechanism. Instead of waiting for a query or the end of a video segment, VST activates its reasoning processes over incoming video clips during the streaming itself. This is a crucial shift: the LLM's reasoning latency is effectively amortized over the video playback time, rather than becoming a bottleneck at the point of decision.
The core of VST involves a streaming thought mechanism that continuously compresses visual dynamics from the video stream into a long-term textual memory. This memory, combined with a short-term visual buffer, allows the model to efficiently reason over indefinite video streams while keeping memory usage fixed.
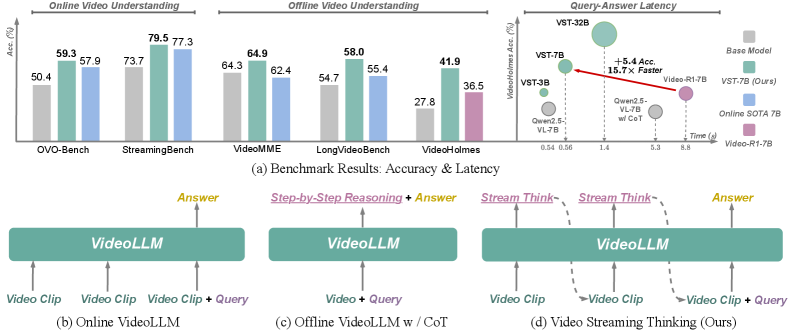 Figure 1: VST delivers strong performance on online and offline video understanding benchmarks while maintaining low QA latency, contrasting with existing streaming VideoLLMs that lack explicit analytical reasoning (b) or incur high latency with post-query CoT (c). VST (d) introduces proactive pre-query reasoning for efficiency and performance.
Figure 1: VST delivers strong performance on online and offline video understanding benchmarks while maintaining low QA latency, contrasting with existing streaming VideoLLMs that lack explicit analytical reasoning (b) or incur high latency with post-query CoT (c). VST (d) introduces proactive pre-query reasoning for efficiency and performance.
This proactive approach means the LLM is building a dynamic understanding of the scene before a specific question or command arrives. When a query is made, much of the necessary reasoning has already been done, leading to significantly faster responses. Figure 7 illustrates this perfectly: stream thoughts are generated before a user query, effectively hiding the reasoning latency.
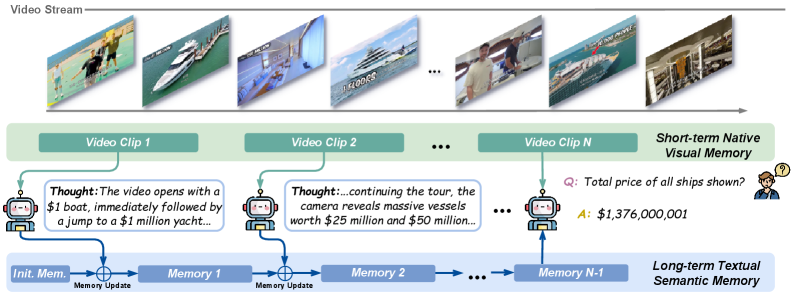 Figure 2: The Video Streaming Thinking pipeline. The model uses a streaming thought mechanism to compress visual dynamics into a long-term textual memory, enabling efficient reasoning over indefinite video streams with fixed memory budgets.
Figure 2: The Video Streaming Thinking pipeline. The model uses a streaming thought mechanism to compress visual dynamics into a long-term textual memory, enabling efficient reasoning over indefinite video streams with fixed memory budgets.
The VST training pipeline is equally sophisticated. It integrates VST-SFT (Supervised Fine-Tuning), which structurally adapts an offline VideoLLM for causal streaming reasoning. This uses a streaming attention mask to enforce temporal causality, ensuring the model only attends to the current visual buffer and historical textual context (Figure 3a). Alongside this is VST-RL (Reinforcement Learning), which performs on-policy optimization through an agentic loop. This improves the quality of the generated streaming thoughts by using verifiable rewards computed from the final answer (Figure 3b).
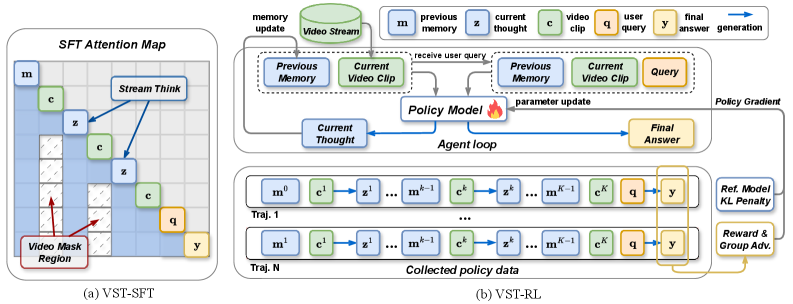 Figure 3: The training pipeline showing VST-SFT (a) which enforces temporal causality via a streaming attention mask, and VST-RL (b) which optimizes streaming thoughts via an agentic loop and verifiable rewards.
Figure 3: The training pipeline showing VST-SFT (a) which enforces temporal causality via a streaming attention mask, and VST-RL (b) which optimizes streaming thoughts via an agentic loop and verifiable rewards.
To feed this training, the authors devised an automated data synthesis pipeline. It builds video knowledge graphs by incrementally extracting entities and relations, then samples multi-hop evidence chains. This allows for the generation of high-quality streaming QA pairs with entity-relation grounded streaming Chain-of-Thought, enforcing multi-evidence reasoning and sustained attention to the video stream (Figure 4).
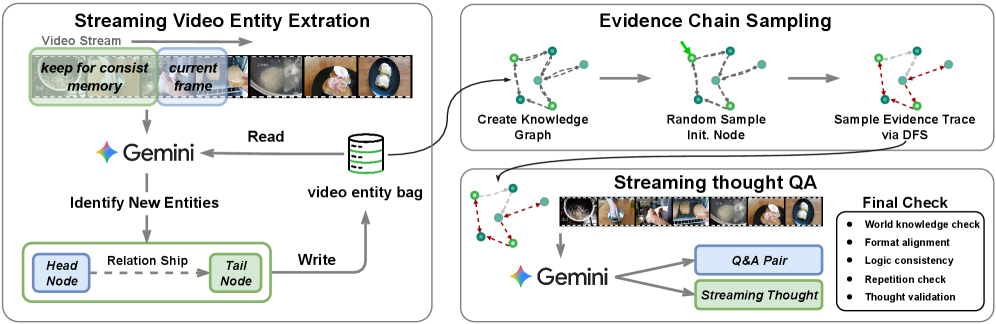 Figure 4: The Stream-Thought QA data curation pipeline, which builds video knowledge graphs to generate high-quality streaming QA pairs with grounded streaming thoughts for multi-evidence reasoning.
Figure 4: The Stream-Thought QA data curation pipeline, which builds video knowledge graphs to generate high-quality streaming QA pairs with grounded streaming thoughts for multi-evidence reasoning.
 Figure 7: VST's streaming inference pipeline. Stream thoughts are generated for incoming video clips before a user query arrives, effectively hiding reasoning latency and enabling rapid QA responses.
Figure 7: VST's streaming inference pipeline. Stream thoughts are generated for incoming video clips before a user query arrives, effectively hiding reasoning latency and enabling rapid QA responses.
The Numbers Don't Lie
The VST-7B model demonstrates impressive performance across various benchmarks, especially where real-time responsiveness is critical.
- On online benchmarks,
VST-7Bscored:- 79.5% on
StreamingBench - 59.3% on
OVO-Bench
- 79.5% on
- It also remains competitive on offline long-form video or reasoning benchmarks, showing strong generalization.
- The most compelling comparison is against
Video-R1, a leading VideoLLM that relies on post-query Chain-of-Thought (CoT) reasoning:- VST responds 15.7 times faster than
Video-R1. - Achieves a +5.4% improvement on the
VideoHolmesbenchmark, a challenging reasoning task.
- VST responds 15.7 times faster than
This performance showcases a significant leap in both efficiency and accuracy for real-time video understanding. The ability to achieve better results while being orders of magnitude faster is precisely what edge devices like drones demand.
 Figure 6: A
Figure 6: A VideoHolmes case study comparing VST-7B with Video-R1-7B. VST-7B processes the video stream and performs streaming thinking before the query, leading to faster, more accurate answers than Video-R1-7B's post-query CoT.
Proactive Autonomy: Why It Matters for Drones
For drone hobbyists, builders, and engineers, VST represents a fundamental shift in what's possible for autonomous systems. This isn't just about faster vision processing; it's about enabling true real-time understanding and proactive decision-making.
Consider a drone performing an inspection. Instead of merely transmitting video back to a human operator or running simple object detection, a VST-equipped drone could be continuously reasoning about the structural integrity of a bridge, identifying subtle anomalies, and even predicting potential failure points as it flies. In search and rescue, a drone could not only detect a person but understand their context, assess the severity of their situation, and relay actionable intelligence instantly, without waiting for a ground operator to ask specific questions.
This capability unlocks advanced autonomous navigation in complex, dynamic environments, smarter obstacle avoidance that understands intent, and sophisticated target tracking that anticipates movement. Essentially, drones can move from being reactive flying cameras to genuinely intelligent, on-board cognitive agents, reducing reliance on ground station processing and pushing more AI to the edge.
The Road Ahead: Limitations and Challenges
While VST is a significant step forward, it's important to acknowledge the practical hurdles and areas for future development.
First, computational overhead remains a concern. While VST amortizes latency, running a 7B parameter LLM model, even efficiently, on drone hardware still demands substantial processing power. This translates to higher power consumption and larger, heavier companion computers than most small drones typically carry. Integrating this into a truly compact, long-endurance platform is a considerable engineering challenge.
Second, the data dependency for training is non-trivial. The automated training-data synthesis pipeline relies on creating high-quality video knowledge graphs. While automated, generating and verifying these graphs for the immense diversity of real-world drone operational environments (e.g., varied weather, lighting, terrain, clutter) will require significant effort to ensure robustness and generalizability.
Third, generalization outside of benchmark datasets is always a question for LLMs. While VST performs well on StreamingBench and OVO-Bench, real-world drone perception involves extreme variations in lighting, atmospheric conditions, sensor noise, and novel objects or scenarios not seen in training. How well VST maintains its "thinking while watching" coherence and accuracy in truly unconstrained and unpredictable environments needs rigorous testing.
Finally, hardware integration and optimization for specific drone platforms is crucial. While the academic paper demonstrates the algorithmic breakthrough, moving from a lab setup to a robust, flight-ready system requires specialized embedded hardware (e.g., NVIDIA Jetson Orin, Qualcomm Robotics RB5), optimized inference engines (TensorRT), and careful thermal management. The authors acknowledge the need for real-time responsiveness, but the full implications for mass-market drone deployment are still being explored.
Hacking Your Drone's Brain: DIY Feasibility
For the ambitious hobbyist or builder, VST offers a promising avenue for experimentation. The authors state that "Code, data, and models will be released at https://github.com/1ranGuan/VST." This is excellent news, as it means the fundamental components will be accessible.
However, replicating or deploying this on a typical DIY drone won't be a plug-and-play affair. Running a 7B parameter model in real-time requires serious compute. You'd likely need a powerful companion computer like an NVIDIA Jetson Orin Nano or NX, or a Qualcomm Snapdragon robotics platform, paired with a decent camera. This is a step up from basic Raspberry Pi setups. Expertise in machine learning, PyTorch, and integrating complex software with drone flight controllers (e.g., PX4, ArduPilot) will be essential. While fine-tuning the model for specific, niche drone applications might be challenging, the release of pre-trained models provides a solid starting point for those willing to dive deep.
The Collaborative AI Landscape
VST isn't developed in a vacuum; it builds on and complements other advancements in video understanding and efficient AI. For instance, the need for efficiency in VST's "watching" component resonates with papers like "Attend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing" by Baifeng Shi, Stephanie Fu, Long Lian et al., which focuses on intelligent "gazing" to process only important pixels, directly supporting the efficient visual input VST requires to maintain its real-time performance on resource-constrained drone hardware.
Similarly, "EVATok: Adaptive Length Video Tokenization for Efficient Visual Autoregressive Generation" by Tianwei Xiong, Jun Hao Liew, Zilong Huang et al. addresses the foundational challenge of efficient video tokenization. VST's ability to process indefinite video streams relies heavily on optimizing how visual information is compressed. EVATok's adaptive tokenization can provide a more streamlined input, directly enhancing the responsive, low-latency processing critical for VST to "watch and think simultaneously."
As drones become more capable of complex reasoning with VST, the need to verify these complex decisions grows. "MM-CondChain: A Programmatically Verified Benchmark for Visually Grounded Deep Compositional Reasoning" by Haozhan Shen, Shilin Yan, Hongwei Xue et al. offers a benchmark for precisely this. It ensures that multimodal LLMs can execute complex, conditional workflows reliably, a crucial step for intelligent drones making multi-step decisions based on their environment.
And finally, for any drone to "think" effectively about its environment, accurate spatial data is paramount. "DVD: Deterministic Video Depth Estimation with Generative Priors" by Hongfei Zhang, Harold Haodong Chen, Chenfei Liao et al. provides a robust method for video depth estimation. Providing VST with high-quality, deterministic 3D perception data from a drone's cameras would significantly enhance the quality and reliability of its real-time reasoning about the physical world.
The Next Generation of Aerial Intelligence
The advent of Video Streaming Thinking pushes drones beyond mere visual input into an era of true cognitive awareness. We're moving from drones that react to drones that proactively understand, reason, and make intelligent decisions in real-time, fundamentally changing the landscape of autonomous aerial systems.
Paper Details
Title: Video Streaming Thinking: VideoLLMs Can Watch and Think Simultaneously Authors: Yiran Guan, Liang Yin, Dingkang Liang, Jianzhong Ju, Zhenbo Luo, Jian Luan, Yuliang Liu, Xiang Bai Published: March 2026 arXiv: 2603.12262 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.