Drones Understand 'Past the Truck,' Even When It's Hidden
BEACON enables drones to follow complex, open-vocabulary language instructions for navigation by predicting traversable paths in occluded areas, fusing vision-language models with depth data in a Bird's-Eye View.

TL;DR: This paper introduces BEACON, a system that lets drones understand complex, language-based navigation commands like "go past the big red truck and turn left at the oak tree," even when parts of the path or target are hidden by obstacles. It achieves this by predicting traversable areas in a
Bird's-Eye View, extending currentvision-language models(VLMs) beyond visible pixels to infer paths in occluded regions.
Giving Drones a Voice: Beyond Basic Commands
We've all dreamt of simply telling our drone where to go. "Follow that car," "Inspect the roof," or even "Go past the big red truck and turn left at the oak tree." This kind of intuitive, natural language interaction often feels like science fiction, especially when the environment is complex and full of obstacles. New research brings us a significant step closer, allowing drones to act on such instructions, inferring paths and targets that aren't immediately visible.
The Hidden Challenge: Navigating What You Can't See
Current methods for language-conditioned navigation often fall short in real-world scenarios. Most vision-language models (VLMs) are trained to ground language instructions to visible pixels in an image. This works fine when everything is in plain sight. But what happens when the "big red truck" is around a corner, or the "oak tree" is behind a building? Drones need to navigate through environments where parts of the path, or even the ultimate target, are occluded by furniture, walls, or moving people. Relying solely on 2D image-space predictions proves a critical limitation.
Drones operating in dynamic, cluttered spaces need to "see" beyond what's directly in front of their cameras, inferring where they can go, not just where they see. This gap in understanding occluded targets has been a major bottleneck for truly autonomous, language-guided navigation in complex environments.
BEACON's Bird's-Eye View: Seeing Beyond the Visible
BEACON tackles this problem head-on, moving beyond 2D pixel-based predictions. Instead of just identifying visible targets, it generates an ego-centric Bird's-Eye View (BEV) affordance heatmap. This heatmap covers a local region around the drone, critically including areas currently occluded. Think of it as the drone building a mini-map of traversable space based on your command, even if it has to guess what's around the corner.
The system works in two main stages. First, it tunes an Ego-Aligned VLM using instruction-specific 3D position encoding. This stage helps the VLM understand where objects are relative to the drone, not just what they look like.
 Figure 2: Examples of language-conditioned local navigation under occlusion. The blue boxes mark the robot, the red boxes highlight humans and objects that cause occlusions, and the green boxes indicate target regions.
Figure 2: Examples of language-conditioned local navigation under occlusion. The blue boxes mark the robot, the red boxes highlight humans and objects that cause occlusions, and the green boxes indicate target regions.
In the second stage, the pre-trained VLM's output, now conditioned by the instruction, combines with Geometry-Aware BEV features derived from the drone's surround-view RGB-D observations. This fusion is crucial. The VLM provides the high-level semantic understanding of the language instruction ("past the truck," "turn left"), while depth data provides the concrete, real-world 3D geometry of the environment. A Post-Fusion Affordance Decoder then processes this combined information to predict the final BEV navigation affordance heatmap. The highest-scoring point on this heatmap becomes the drone's next target. This clever integration of language understanding with 3D spatial reasoning allows BEACON to infer paths and targets not directly visible.
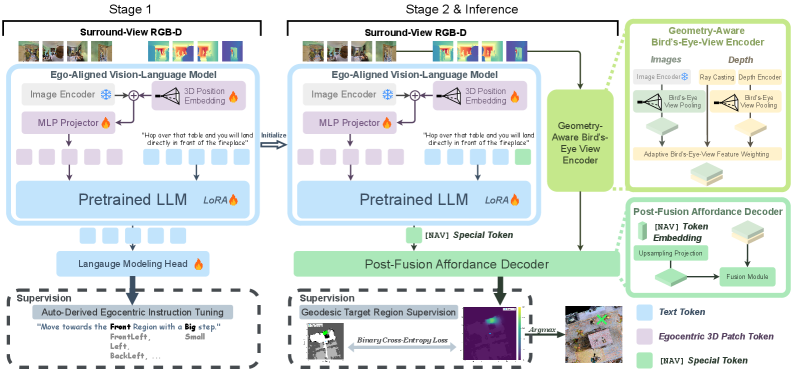 Figure 3: BEACON overview. Stage 1 performs auto-derived ego-centric instruction tuning with ego-centric 3D position encoding to train the Ego-Aligned VLM. Stage 2 initializes the Ego-Aligned VLM weights from Stage 1, combines the resulting instruction-conditioned output with Geometry-Aware BEV features, and predicts an ego-centric BEV navigation affordance heatmap via a Post-Fusion Affordance Decoder. The two stages use different supervision signals, and inference selects the navigation target by taking the argmax.
Figure 3: BEACON overview. Stage 1 performs auto-derived ego-centric instruction tuning with ego-centric 3D position encoding to train the Ego-Aligned VLM. Stage 2 initializes the Ego-Aligned VLM weights from Stage 1, combines the resulting instruction-conditioned output with Geometry-Aware BEV features, and predicts an ego-centric BEV navigation affordance heatmap via a Post-Fusion Affordance Decoder. The two stages use different supervision signals, and inference selects the navigation target by taking the argmax.
Figure 6: [LOGO]
Real-World Impact: How BEACON Performs
Performance gains are significant, particularly in challenging scenarios involving occlusion. BEACON was tested using an occlusion-aware dataset built in the Habitat simulator, which provides a realistic environment for navigation testing.
Key results from their validation subset with occluded target locations include:
- A 22.74 percentage point improvement in accuracy, averaged across geodesic thresholds, over the state-of-the-art image-space baseline.
- This means the system is far more likely to correctly identify the target location when hidden.
- The
BEVspace formulation and the fusion ofVLMoutputs with depth-derived features proved critical design choices for this improvement.
These numbers aren't just incremental; they represent a substantial leap forward in enabling robust navigation in visually complex and obstructed environments.
 Figure 4: Successful examples under heavy occlusion.
Figure 4: Successful examples under heavy occlusion.
Opening New Doors for Drone Applications
For drone hobbyists and builders, this research unlocks a new level of autonomy and intuitive control. Consider a drone that doesn't just follow GPS coordinates or predefined waypoints, but understands natural language instructions in a crowded warehouse, a dense forest, or even your own backyard.
This technology could be applied to:
- Autonomous Inspection: Sending a drone to "inspect the back side of the building, past the parked vehicles" without needing a direct line of sight.
- Search and Rescue: Guiding a drone with instructions like "search behind the collapsed structure" to find hidden targets more efficiently.
- Delivery and Logistics: Drones navigating complex last-mile routes, understanding "drop the package at the side entrance, past the flower pots."
- Advanced FPV and Cinematography: Guiding a drone with commands like "orbit the subject, staying behind the large tree," allowing for more complex, dynamic shots without constant manual input.
The ability to infer hidden paths and destinations dramatically expands the operational envelope for autonomous drones, moving them closer to truly intelligent robotic assistants.
The Road Ahead: Current Limitations and Future Challenges
While BEACON shows impressive results, it's important to be pragmatic about its current state and limitations:
- Simulator Dependence: The primary evaluation was conducted in the
Habitat simulator. While realistic, real-world deployment introduces far more variability in lighting, sensor noise, and object properties than a simulated environment can fully replicate. Generalizing these results to physical drones will be the next big challenge. - Specific Failure Modes: The paper highlights failures due to
landmark confusionorinstruction ambiguity. If there are two "big red trucks" or the instruction "go to the tree" is given when multiple trees are present, the system can struggle. This points to the need for more sophisticated contextual reasoning and disambiguation capabilities within theVLM. - Computational Cost: Running surround-view
RGB-Dsensors and complexVLMmodels in real-time on a mini-drone is computationally intensive. The paper doesn't explicitly detail inference speed or hardware requirements, but typically, these systems demand significant onboard processing power, impacting battery life and payload. - Hardware Integration: The system relies on
surround-view RGB-D observations. This means multiple cameras and depth sensors, which add to the drone's weight, power consumption, and complexity. Mini-drones, in particular, have tight constraints on these factors. - Dynamic Environments: While it handles static occlusions well, its robustness to highly dynamic and unpredictable environments (e.g., rapidly moving crowds, shifting obstacles) might still need further validation and improvement.
 Figure 5: Failures due to landmark confusion or instruction ambiguity.
Figure 5: Failures due to landmark confusion or instruction ambiguity.
For the Ambitious Builder: DIY Feasibility
Replicating BEACON from scratch as a hobbyist would be a significant undertaking. The core technology relies on advanced Vision-Language Models and intricate 3D spatial reasoning. While the paper is publicly available, the codebase and trained models are not yet open-source, though the project page (linked in the abstract) is a good place to watch for updates.
For a DIY builder, the most feasible path would be to:
- Leverage existing open-source VLMs: Tools like
CLIPorLLaVAcould serve as a starting point, but integrating them for ego-centric 3D reasoning would require deep expertise. - Build a multi-camera RGB-D setup: This means integrating multiple
Intel RealSenseorAzure Kinectcameras, or similar compact depth sensors, which adds hardware complexity. - Simulator-first approach: Testing in
HabitatorROS Gazebowould be essential before attempting real-world deployment, given the safety implications.
This isn't a weekend project. It requires strong skills in machine learning, computer vision, robotics, and potentially custom hardware integration. However, as these techniques mature and more open-source frameworks emerge, parts of this capability might become accessible to advanced hobbyists over time.
BEACON in Context: Related Research
BEACON builds upon, and contributes to, several active areas of research. For a drone to effectively navigate using language, it first needs to understand its environment in 3D. Papers like "ReCoSplat: Autoregressive Feed-Forward Gaussian Splatting Using Render-and-Compare" by Cheng et al. highlight how robust 3D scene reconstruction from sequential observations is crucial. If BEACON's underlying Geometry-Aware BEV features can draw from more accurate and real-time 3D scene representations like those offered by Gaussian Splatting, its ability to infer traversable paths would only improve.
Furthermore, the very foundation of BEACON relies on the spatial intelligence of Vision-Language Models. "Stepping VLMs onto the Court: Benchmarking Spatial Intelligence in Sports" by Yang et al. provides a valuable benchmark for how well VLMs grasp complex spatial relationships. This work helps contextualize the capabilities, and current limitations, of the VLM components BEACON uses to interpret instructions such as "past the truck" or "at the tree." The better these foundational VLMs become at spatial reasoning, the more robust BEACON-like systems will be.
Finally, advanced navigation is useless without reliable communication. "Efficient, Adaptive Near-Field Beam Training based on Linear Bandit" by Liu et al. addresses how drones can maintain robust communication links. As drones operate in complex environments, receiving nuanced language commands or reporting intricate status updates requires stable, high-bandwidth connections. Research into adaptive beam training ensures the drone can reliably receive its instructions, making the sophisticated navigation capabilities of BEACON truly actionable.
The Future of Intuitive Drone Control
BEACON represents a significant stride towards natural, intuitive control of autonomous drones. While real-world deployment still faces hurdles, the ability to command a drone with open-vocabulary instructions, even when targets are out of sight, fundamentally changes how we might interact with these machines in the very near future.
Paper Details
Title: BEACON: Language-Conditioned Navigation Affordance Prediction under Occlusion Authors: Xinyu Gao, Gang Chen, Javier Alonso-Mora Published: March 2026 arXiv: 2603.09961 | PDF
Written by
The Flight DeskSharing knowledge about drones and aerial technology.
More from Mini Drone Shop
Stop Wandering: Metacognitive AI Makes Drones Smarter, Not Just Faster

Unmasking the Invisible: Polarization Powers Drone Camouflage Detection

Smarter Drone Comms: AI-Powered Beams Cut Through the Noise
