MLLMs Gain True 3D Vision for Drones by Learning from Video's Implicit Cues
New research shows how Multimodal Large Language Models (MLLMs) can gain robust 3D spatial awareness by extracting 'implicit priors' from video generation models, enhancing drone navigation and interaction without explicit 3D data.
Your Drone's Brain Just Got a Spatial Upgrade
TL;DR: Multimodal Large Language Models (MLLMs), while powerful, often lack true 3D spatial understanding. This paper introduces VEGA-3D, a framework that lets MLLMs extract rich 3D structural and physical priors from pre-trained video generation models, significantly boosting their ability to reason about and interact with the physical world from just an image.
AI models have shown impressive capabilities in recognizing objects, responding to prompts, and even generating images. But for a drone, simply seeing a table isn't enough. It needs to know its height, how far it is from the wall, and if there's enough clearance under it. This new work, VEGA-3D, demonstrates how AI for drones can develop genuine 3D spatial awareness, moving beyond simple object recognition to true physical world understanding.
The Spatial Blind Spot in AI's Vision
Modern MLLMs are fantastic at semantic tasks, understanding language and identifying objects in images. However, when it comes to fine-grained geometric reasoning – like judging distances, object relationships in 3D, or understanding physical dynamics – they often hit a wall. They're spatially blind. Current solutions typically lean on explicit 3D modalities (like LiDAR or structured light sensors) or complex geometric scaffolding, which often means extra hardware, increased weight and power draw, or laborious 3D data collection. These approaches are limited by data scarcity, struggle with generalization, and add significant complexity to drone systems. For a mini drone, every gram and watt counts, making these explicit 3D sensors less ideal for many applications.
Unlocking the World's Geometry from Video
The core insight of VEGA-3D is simple: to generate coherent video, large-scale video generation models must inherently learn robust 3D structural priors and physical laws. A video model cannot just slap objects together; it needs to understand how they move in space, how perspectives shift, and how objects interact. The authors propose repurposing a pre-trained video diffusion model as a Latent World Simulator. Instead of generating video, VEGA-3D extracts spatiotemporal features from the model's intermediate noise levels. These features, rich in implicit 3D cues, are then integrated with the MLLM's existing semantic representations via a token-level adaptive gated fusion mechanism.
The video model acts as a silent teacher, showing the MLLM how the 3D world works without needing explicit 3D labels. Figure 1 illustrates this paradigm shift, moving away from explicit 3D inputs or complex geometric supervision towards extracting implicit priors.
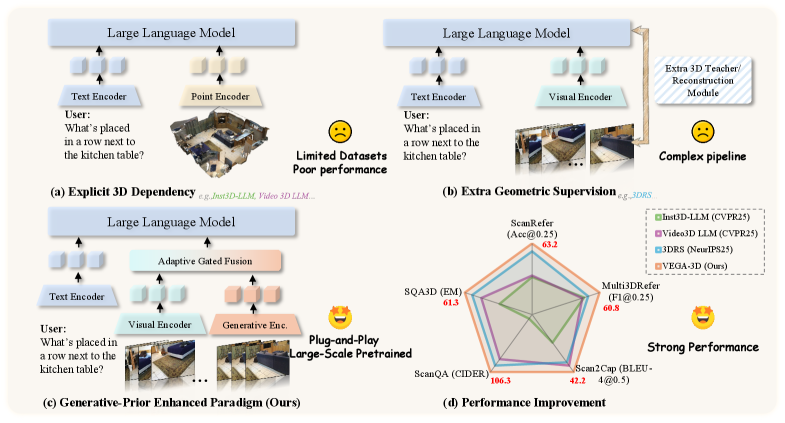 Figure 1: Comparison of existing paradigms. Unlike methods relying on (a) explicit 3D inputs or (b) complex geometric supervision, (c) our VEGA-3D extracts implicit priors from video generation models. By repurposing them as Latent World Simulators, we achieve (d) superior performance without external 3D dependencies.
Figure 1: Comparison of existing paradigms. Unlike methods relying on (a) explicit 3D inputs or (b) complex geometric supervision, (c) our VEGA-3D extracts implicit priors from video generation models. By repurposing them as Latent World Simulators, we achieve (d) superior performance without external 3D dependencies.
This Latent World Simulator concept is key. The video generation model, specifically a DiT-based architecture (Diffusion Transformer), is frozen. VEGA-3D then intelligently extracts features from specific intermediate layers and noise levels. As shown in Figure 6, performance peaks at intermediate noise levels, and particular intermediate layers capture the most robust geometric cues.
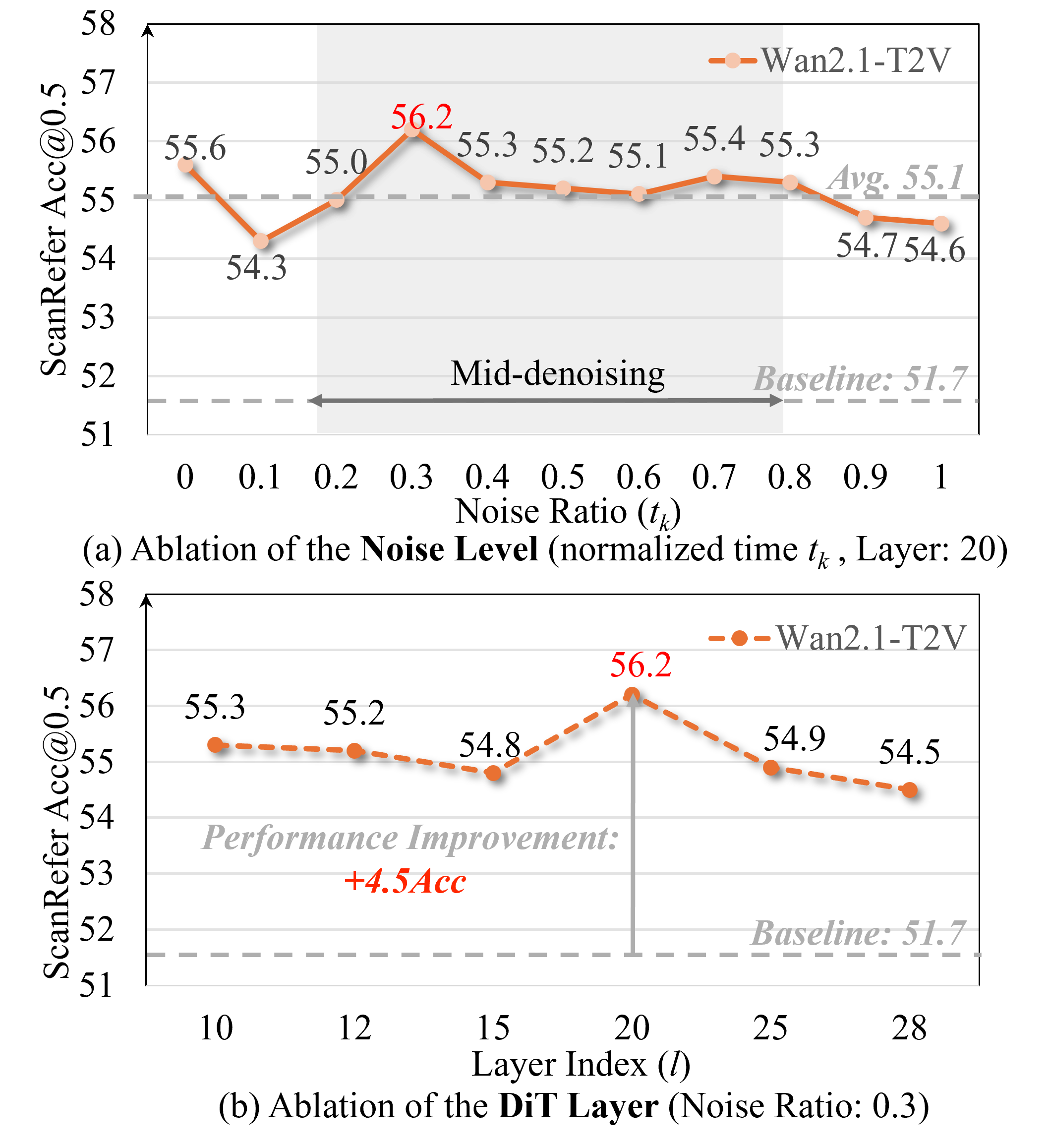 Figure 6: Ablation studies on noise injection and DiT depth. (a) Performance peaks at intermediate noise levels. (b) Specific intermediate layers capture the most robust geometric cues.
Figure 6: Ablation studies on noise injection and DiT depth. (a) Performance peaks at intermediate noise levels. (b) Specific intermediate layers capture the most robust geometric cues.
The extracted features are then dynamically integrated into the MLLM. Figure 4 provides an overview of the entire framework, detailing how the Latent World Simulator feeds into the Adaptive Gated Fusion module.
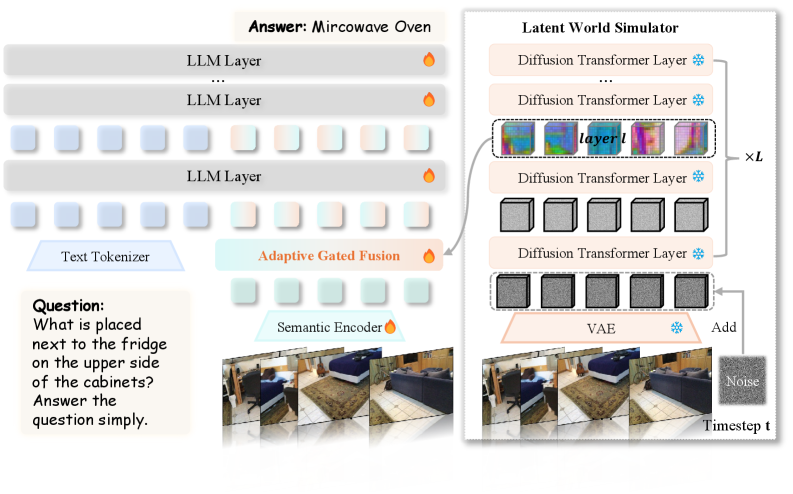 Figure 4: Overview of the VEGA-3D framework. We repurpose a frozen video generation model as a Latent World Simulator to extract implicit 3D priors. These features are dynamically integrated with the semantic stream via Adaptive Gated Fusion, equipping the MLLM with dense 3D structural awareness.
Figure 4: Overview of the VEGA-3D framework. We repurpose a frozen video generation model as a Latent World Simulator to extract implicit 3D priors. These features are dynamically integrated with the semantic stream via Adaptive Gated Fusion, equipping the MLLM with dense 3D structural awareness.
The Adaptive Gated Fusion (Figure 5) is crucial for combining these heterogeneous features effectively, allowing the MLLM to leverage the spatial information without being overwhelmed.
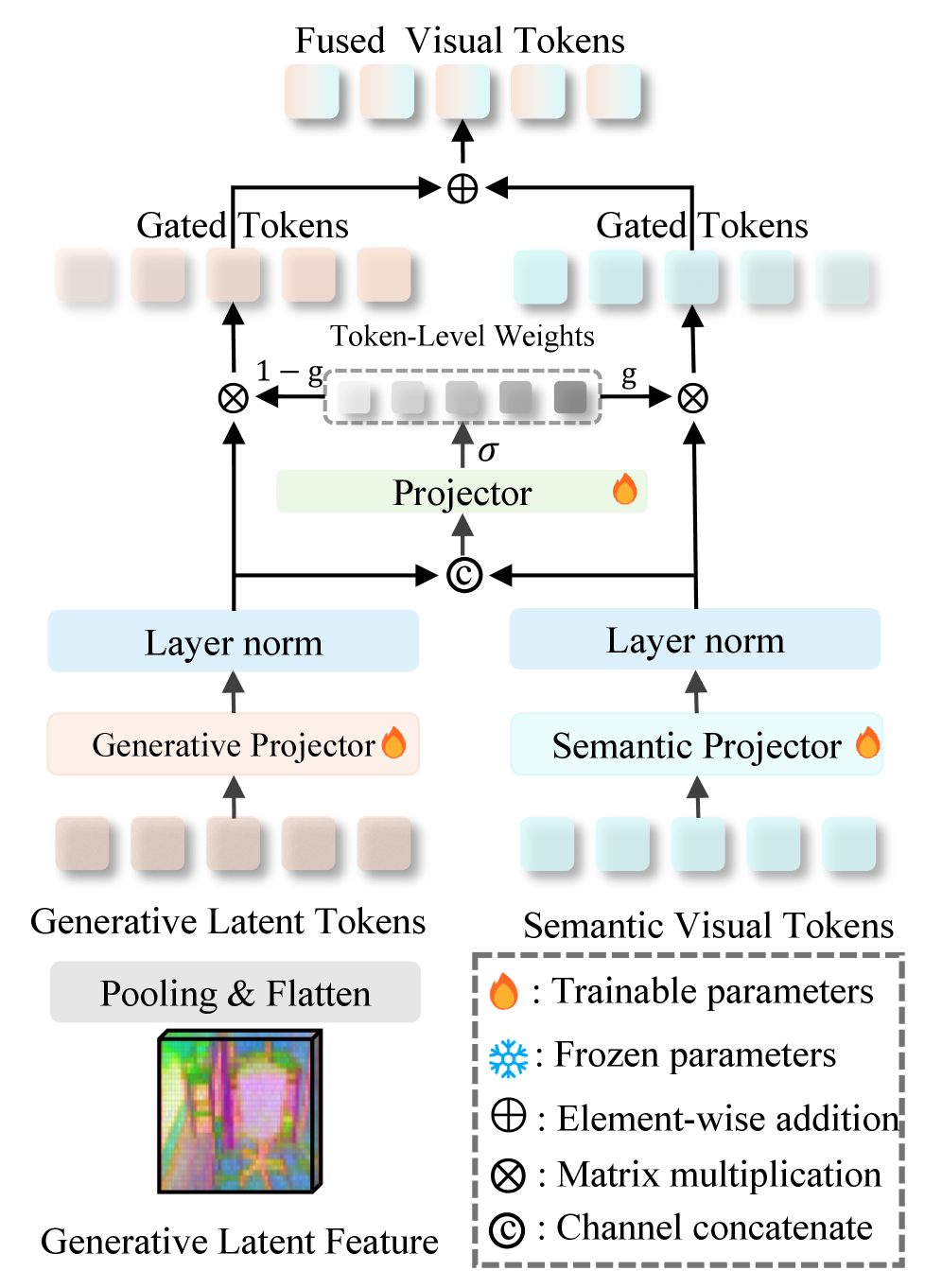 Figure 5: Adaptive Gated Fusion. It dynamically integrates heterogeneous features using a token-level gating mechanism.
Figure 5: Adaptive Gated Fusion. It dynamically integrates heterogeneous features using a token-level gating mechanism.
Tangible Performance Gains
VEGA-3D “outperforms state-of-the-art baselines” across various benchmarks, including 3D scene understanding, spatial reasoning, and embodied manipulation. This represents a significant step forward in making MLLMs spatially aware without adding explicit 3D data or sensors.
- Improved Object Localization: In qualitative comparisons like ScanRefer (Figure 8), VEGA-3D accurately localizes referred objects even amidst clutter, occlusion, and ambiguous descriptions, reflecting robust spatial grounding.
- Better Temporal Reasoning: Figure 10 shows VEGA-3D's ability to better capture the ordering of object appearances in the
VSI-Benchdataset, indicating a stronger grasp of temporal and spatial consistency.
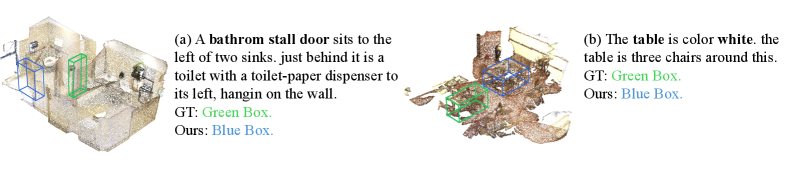 Figure 8: Qualitative comparison on ScanRefer. Compared with the baseline, VEGA-3D localizes the referred object accurately under clutter, occlusion, and ambiguous referring expressions, reflecting stronger spatial grounding from the generative prior.
Figure 8: Qualitative comparison on ScanRefer. Compared with the baseline, VEGA-3D localizes the referred object accurately under clutter, occlusion, and ambiguous referring expressions, reflecting stronger spatial grounding from the generative prior.
 Figure 10: Qualitative comparison on the Appearance Order subset of VSI-Bench. VEGA-3D better captures the ordering of object appearances and is less distracted by locally plausible but temporally inconsistent choices than the baseline.
Figure 10: Qualitative comparison on the Appearance Order subset of VSI-Bench. VEGA-3D better captures the ordering of object appearances and is less distracted by locally plausible but temporally inconsistent choices than the baseline.
Why This Matters for Drones
This research significantly impacts autonomous drones. A drone could not just avoid obstacles, but understand why it's avoiding them – the empty space, the physical constraints. This capability translates directly into:
- Smarter Navigation: Drones could navigate tighter spaces, understand complex environments (e.g., flying through a partially open window), and avoid novel obstacles with a deeper understanding of their 3D form.
- Precise Interaction and Manipulation: For drones equipped with grippers or tools, understanding the exact 3D position, orientation, and relationship of objects allows for far more accurate and robust manipulation tasks, from picking up a specific component to performing delicate inspections.
- Reduced Sensor Load: By extracting 3D priors from existing visual input, drones could potentially reduce reliance on heavy and power-hungry explicit 3D sensors like LiDAR, leading to lighter, longer-flying, and more agile systems.
- Enhanced Situational Awareness: A drone could answer complex spatial questions about its environment – "Is there enough room to fly under that pipe?" or "Where is the wrench relative to the engine block?" – all from its camera feed.
- Robust Autonomous Agents: This makes MLLMs more suitable for real-world robotic applications, where understanding the physical consequences of actions is paramount.
Limitations and What's Next
While promising, VEGA-3D has limitations. The authors acknowledge that while it captures a reasonable spatial anchor, it can still struggle with fine-grained instance disambiguation in cluttered scenes (Figure 9). This means distinguishing between very similar objects tightly packed together might still be a challenge. Furthermore:
- Implicit vs. Explicit: The 3D understanding is implicit. While powerful for reasoning, it might not provide the precise metric depth measurements that a dedicated depth sensor delivers. For tasks requiring exact millimeter precision, additional sensors might still be necessary.
- Computational Cost: Repurposing a
video generation model(even a frozen one) still requires significant computational resources, especially for large models likeImagenorSorathat might be at the core of futureLatent World Simulators. While caching features helps, initial processing or real-time adaptation could still be demanding for edge devices. - Generative Model Dependency: The quality of the implicit 3D prior is directly tied to the capabilities of the underlying video generation model. As these models improve, so too will VEGA-3D's spatial awareness.
- Dynamic Scenes: The paper focuses on static scene understanding or temporal consistency. Handling highly dynamic, unpredictable environments with rapidly moving objects might introduce new challenges.
 Figure 9: Representative failure case on ScanRefer. We show the VEGA-3D prediction and the ground-truth box, indicating that VEGA-3D captures a reasonable spatial anchor but can still struggle with fine-grained instance disambiguation in cluttered scenes.
Figure 9: Representative failure case on ScanRefer. We show the VEGA-3D prediction and the ground-truth box, indicating that VEGA-3D captures a reasonable spatial anchor but can still struggle with fine-grained instance disambiguation in cluttered scenes.
DIY Feasibility for the Determined Builder
The authors have made the code publicly available at https://github.com/H-EmbodVis/VEGA-3D. This is excellent news for researchers and serious hobbyists. However, replicating this at home isn't a weekend project for everyone. Running large video diffusion models and MLLMs typically requires substantial GPU power – think multiple high-end NVIDIA A100 or RTX 4090 cards. While the framework is plug-and-play with existing MLLMs, the Latent World Simulator component itself is resource-intensive. For a smaller-scale drone, adapting this would likely involve significant optimization and potentially smaller, custom-trained foundation models, which is a considerable undertaking.
This work complements other advancements in making AI more grounded. For example, Not All Features Are Created Equal: A Mechanistic Study of Vision-Language-Action Models by Grant et al. dives into how Vision-Language-Action (VLA) models translate multimodal inputs into concrete actions. Understanding the spatial priors from VEGA-3D would directly inform how these VLA models make decisions for drone control, leading to more trustworthy and responsive autonomous agents. Furthermore, once a drone understands the overall 3D scene, DreamPartGen by Yu et al., which focuses on semantically grounded part-level 3D generation, could provide the next layer of detail, allowing drones to reason about objects in terms of their constituent parts. For efficient representation of this newfound 3D understanding, techniques like Matryoshka Gaussian Splatting by Guo et al. offer ways to render and store 3D scenes efficiently at adjustable fidelity, crucial for real-time mapping or AR overlays on a drone. Finally, evaluating the robustness of these capabilities, especially over extended periods, will be critical, as highlighted by LVOmniBench: Pioneering Long Audio-Video Understanding Evaluation for Omnimodal LLMs by Tao et al.
This paper pushes us closer to a future where drones don't just react to pixels, but genuinely comprehend the physical space around them, enabling a new level of autonomous intelligence and interaction.
Paper Details
Title: Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding Authors: Xianjin Wu, Dingkang Liang, Tianrui Feng, Kui Xia, Yumeng Zhang, Xiaofan Li, Xiao Tan, Xiang Bai Published: March 26, 2024 arXiv: 2603.19235 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.