Semantic Superpower: LLMs Give Drones Real-World Common Sense
A new framework, BEVLM, integrates Large Language Models with Bird's-Eye View representations, granting autonomous systems enhanced spatial reasoning and semantic understanding crucial for complex, safety-critical scenarios.

TL;DR: A new framework called BEVLM bridges the gap between the semantic understanding of Large Language Models (LLMs) and the spatial consistency of Bird's-Eye View (BEV) representations. This allows LLMs to reason far more effectively about complex driving scenes, leading to significant improvements in autonomous decision-making and safety.
Beyond Raw Pixels: Understanding the World
Your drone sees the world in incredible detail, capturing terabytes of visual data. But true understanding? That's a different story. Current autonomous systems, whether in drones or cars, excel at geometric tasks like object detection and precise path planning. They can avoid obstacles with impressive accuracy. Yet, they often struggle with the nuanced, contextual "common sense" reasoning that humans take for granted. BEVLM tackles that exact problem head-on, giving drones (and other autonomous agents) a much richer, context-aware understanding of their environment, powered by the semantic prowess of Large Language Models.
The Disconnect: Spatial vs. Semantic
The core challenge lies in how we feed visual information to powerful Large Language Models. Typically, LLMs process visual tokens extracted from multi-view images independently. While this approach can capture semantic richness from individual views, it's computationally redundant and, crucially, breaks the spatial consistency essential for accurate 3D reasoning. It's like trying to comprehend a complex 3D scene by looking at a dozen fragmented snapshots rather than a coherent, unified map. You lose the crucial geometric relationships.
On the other hand, Bird's-Eye View (BEV) representations offer excellent spatial structure, providing a top-down, unified perspective of the environment. However, these BEV encoders are usually trained solely on geometrically annotated tasks, such as object detection or lane segmentation. This means they know where things are, and their basic category, but they lack the deep semantic richness and contextual understanding that foundation vision models or LLMs possess. This leaves us with a difficult choice: a system that's spatially consistent but semantically shallow, or one that's semantically rich but spatially fragmented. This disconnect severely limits an autonomous agent's ability to handle complex, unpredictable, and safety-critical scenarios.
BEVLM's Smart Bridge: Distilling Common Sense
BEVLM offers a compelling and elegant solution by creating a semantic-enhanced and spatially consistent scene representation. The core idea is simple but powerful: first, process raw, multi-view camera inputs into a unified Bird's-Eye View. This BEV representation, inherently strong in spatial coherence, then becomes the target for "semantic distillation" from an LLM. Essentially, the LLM, with its vast general knowledge and reasoning capabilities, teaches the BEV encoder to understand the deeper semantics of objects, their attributes, and their interactions within that precise spatial context. Instead of LLMs trying to piece together a complex scene from disjointed camera feeds, they receive a pre-digested, spatially accurate, and semantically rich BEV input. This unified input dramatically streamlines the LLM's reasoning process, making it far more efficient and effective.
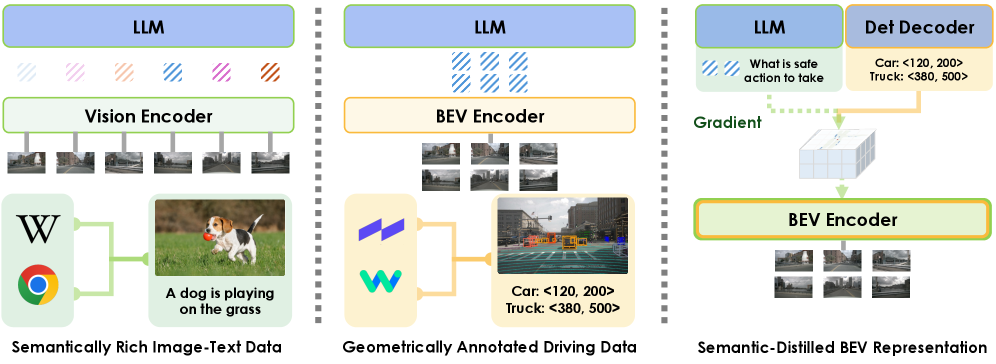
Figure 1: Representation Comparison: Left: Vision encoders can leverage widely available semantically rich image-text data, but process multi-view images independently. Center: Bird’s-Eye View (BEV) encoders provide a spatially consistent scene representation, but are limited to geometrically annotated data. Right (ours): We propose the semantic distillation from LLMs to BEV encoders to build a semantic-enhanced and spatially consistent scene representation.
The technical approach involves using Visual Question Answering (VQA) tasks. During this process, the LLM's high-level semantic insights – for example, understanding that an "excavator" implies a construction zone and potential lane blockage – transfer to the BEV representation. This happens while carefully maintaining the BEV's geometric integrity through standard object detection tasks. This dual training ensures the BEV doesn't just know where things are and their basic category, but also what they are in a broader context and how they relate semantically to the overall scene.
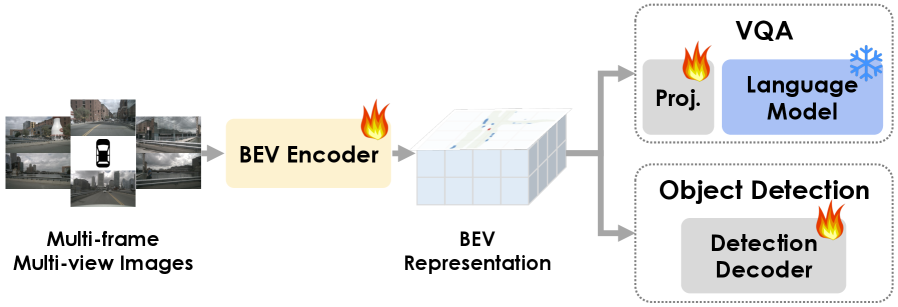
Figure 3: BEV Semantic Distillation: We distill the knowledge from the language model to the BEV representations by using Visual Question Answering (VQA) tasks while regularizing BEV spatial structure using the original object detection tasks.
The Numbers Speak: BEVLM's Impact
The empirical results from the paper are genuinely impressive. By leveraging these unified, semantic-rich BEV features, BEVLM significantly boosts the reasoning capabilities of LLMs in complex autonomous scenarios.
- 46% improvement in reasoning accuracy for cross-view driving scenes. This is a massive jump, indicating a fundamentally better grasp of intricate spatial relationships and scene interpretation compared to prior methods.
- 29% improvement in closed-loop end-to-end driving performance in safety-critical scenarios. This isn't just an academic metric; it directly translates to safer, more reliable autonomous operation where misinterpretation can lead to severe consequences.
The paper further highlights how a BEV token input (BUniAD) vastly outperforms visual tokens extracted from raw vision transformers (IViT) or pre-BEV fusion backbones (IUniAD) when it comes to LLM reasoning. This strongly validates the effectiveness of BEVLM's unified, semantic-rich BEV approach.
Why This Matters for Your Drones
This isn't just about self-driving cars; it's a huge step forward for truly autonomous drones. Consider the implications:
- Urban Delivery Drones: Instead of merely detecting a parked car, a
BEVLM-powered drone could understand that adelivery truckis temporarily blocking a street, or that agroup of peoplesignifies apublic gatheringit should reroute around, rather than just treating them as static obstacles. This moves beyond simple collision avoidance to contextualunderstanding. - Industrial Inspection Drones: An inspection drone could identify not just the presence of a
crackon a bridge, but infer if that crack isstructuralor merelycosmeticbased on its location, surrounding stressors, and historical context gleaned from theLLM'straining. It moves from perception toinference. - Search and Rescue UAVs: A drone in a disaster zone could differentiate a
distressed personwaving for help from afallen logwith far greater accuracy and contextual awareness, prioritizing response based onsemantic cuesrather than just visual shape. This enhancessituational awarenessin critical missions. - Agricultural Drones: These drones could pinpoint
crop stressand understand if it's likely due topests(requiring targeted spraying) versuswater shortage(requiring irrigation adjustments) by correlating visual data with environmental context, leading to more precise and efficient farming. This bringsprecision agricultureto a new level.
This research transforms drones from highly capable flying cameras into genuinely intelligent, context-aware agents, capable of complex, human-like decision-making in unpredictable, real-world scenarios. It promises to unlock applications that were previously out of reach for purely reactive autonomous systems.
DIY Feasibility: Research Today, Products Tomorrow
For the average drone hobbyist or even a small-scale builder, directly replicating BEVLM is a substantial undertaking. This is advanced research relying on large-scale datasets (like DriveLM), significant computational resources for training LLMs and BEV encoders, and deep machine learning expertise. It’s certainly not an off-the-shelf library you can simply drop into your ArduPilot build tomorrow.
However, this doesn't mean it's irrelevant. As these techniques mature, we will inevitably see simplified, optimized versions emerging that could be integrated into more accessible drone platforms. The rapid advancements in edge AI hardware, combined with efforts to distill larger models into smaller, more efficient ones (as seen in related work), suggest that the capabilities demonstrated by BEVLM will trickle down. For now, consider this a crucial glimpse into the near future of high-level drone autonomy, setting the stage for what's possible rather than what's immediately accessible in your workshop.
The Broader AI Landscape
The push for more intelligent, context-aware autonomous systems is undeniably a major frontier in AI. While BEVLM innovates by distilling high-level semantic knowledge into a spatially consistent representation, other researchers are tackling equally critical and complementary challenges. For instance, efficiency is paramount for any drone deployment, and papers like "Penguin-VL: Exploring the Efficiency Limits of VLM with LLM-based Vision Encoders" by Boqiang Zhang et al. are directly addressing how to make Vision Language Models (VLMs) compact and performant enough for resource-constrained edge devices. This work is essential for making BEVLM-like capabilities practical on drones.
Meanwhile, a drone's perspective is inherently egocentric, and understanding dynamic environments from its own "eyes" in real-time is crucial. This is where "EgoReasoner: Learning Egocentric 4D Reasoning via Task-Adaptive Structured Thinking" by Fangrui Zhu et al. comes into play, focusing on spatial-temporal reasoning from the agent's viewpoint, which would complement BEVLM's overarching scene understanding. And underpinning all higher-level semantic understanding is robust foundational perception; the ability to accurately identify and categorize objects in complex 3D scenes. "SCOPE: Scene-Contextualized Incremental Few-Shot 3D Segmentation" by Vishal Thengane et al. is making significant strides in this area, enabling drones to learn new object categories with minimal data. Together, these advancements paint a compelling picture of increasingly capable and truly intelligent autonomous agents.
The Next Horizon for Autonomous Drones
BEVLM represents a significant leap towards truly intelligent drones that don't just react to their environment, but understand it. The ability to infuse precise spatial knowledge with the 'common sense' reasoning of LLMs sets the stage for a new era of autonomous systems capable of navigating and interacting with the world with unprecedented sophistication. This is a fundamental shift from reactive automation to proactive intelligence.
Paper Details
Title: BEVLM: Distilling Semantic Knowledge from LLMs into Bird's-Eye View Representations Authors: Thomas Monninger, Shaoyuan Xie, Qi Alfred Chen, Sihao Ding Published: March 11, 2026 arXiv: 2603.06576 | PDF
Written by
The Flight DeskSharing knowledge about drones and aerial technology.
More from Mini Drone Shop
Stop Wandering: Metacognitive AI Makes Drones Smarter, Not Just Faster

Unmasking the Invisible: Polarization Powers Drone Camouflage Detection

Smarter Drone Comms: AI-Powered Beams Cut Through the Noise
