UniMotion: Unifying Motion, Text, and Vision for Smarter Drones
UniMotion introduces the first unified AI framework capable of simultaneously understanding and generating human motion, natural language, and RGB images from a single architecture. This could enable more intuitive human-drone interaction and advanced autonomous capabilities.
TL;DR: Researchers have developed UniMotion, a unified AI framework that processes and generates human motion, text, and images simultaneously. It treats motion as a continuous modality, enabling a single model to understand complex human actions, describe them, and even predict them, which is a major step for human-drone interaction.
Beyond Just Seeing: Drones That Truly Understand
Drones are getting smarter, but true collaboration with humans often hits a wall when it comes to intuitive communication. Most AI models excel at one thing: vision, or text, or perhaps motion. UniMotion changes that, offering a single framework that truly unifies human motion, natural language, and visual understanding and generation. This isn't just a technical feat; it's a leap toward drones that can genuinely interpret and respond to the dynamic, human-centric world.
The Disconnected AI Problem
Existing AI models for drones often feel like a collection of specialized tools, each excellent at its niche but struggling to connect. You might have a vision model for obstacle avoidance, a natural language processing (NLP) model for voice commands, and a separate system trying to interpret human gestures. The problem? These models typically operate in isolation or with clumsy interfaces between them. More critically, many motion-focused models rely on discrete tokenization, which chops up fluid movements into static chunks. This introduces quantization errors and breaks the natural flow of motion, making accurate, temporally consistent interpretation a serious challenge for a drone needing to react in real-time.
A Unified Language for Motion, Text, and Vision
UniMotion tackles these issues head-on by treating motion as a continuous, primary data type – on equal footing with RGB images. At its core is a novel Cross-Modal Aligned Motion VAE (CMA-VAE). This isn't just another VAE; it’s designed to learn a continuous motion latent space. Crucially, it uses a motion-only encoder for inference, but during training, it leverages a vision-fused encoder for visual supervision. This means the model learns rich visual context for motion without needing images when it's deployed.
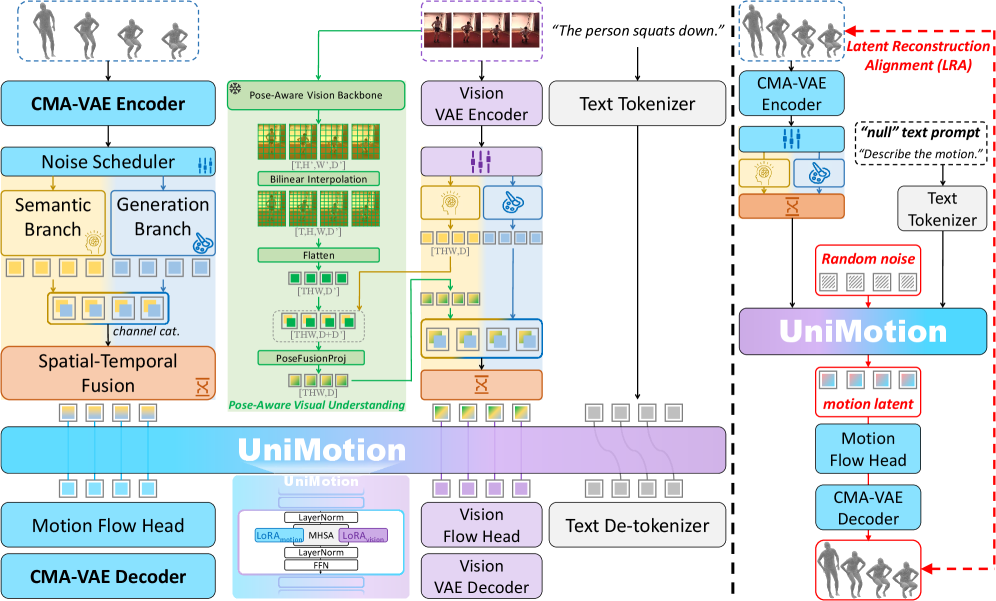 Figure 2: UniMotion unifies motion, text, and RGB through symmetric continuous pathways, processed by a shared LLM backbone for both understanding and generation.
Figure 2: UniMotion unifies motion, text, and RGB through symmetric continuous pathways, processed by a shared LLM backbone for both understanding and generation.
The framework employs symmetric dual-path embedders that create parallel continuous pathways for both motion and RGB data, all within a shared LLM backbone. This architecture separates semantic abstraction (understanding what's happening) from detail-preserving generation (recreating the motion or image). To ensure motion representations are visually informed even without constant camera input, UniMotion introduces Dual-Posterior KL Alignment (DPA). DPA distills the richer posterior from a vision-fused encoder into the motion-only encoder. This smart trick bakes in visual-semantic priors, allowing the system to understand motion with visual context, even if the drone's cameras are temporarily obscured or not actively capturing.
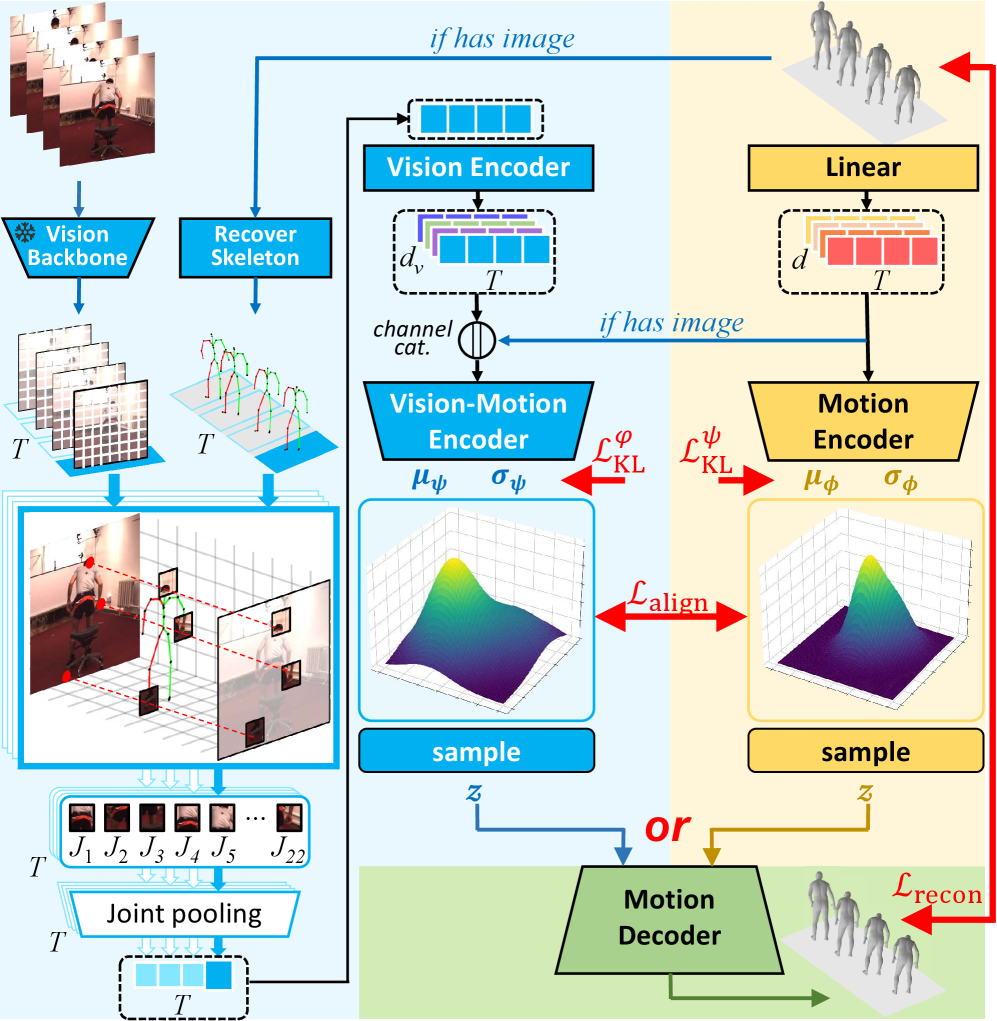 Figure 3: CMA-VAE with DPA learns a continuous motion latent space, injecting visual priors into the motion encoder during training without needing images at inference time.
Figure 3: CMA-VAE with DPA learns a continuous motion latent space, injecting visual priors into the motion encoder during training without needing images at inference time.
A significant challenge with new multimodal models is the 'cold-start problem' – where sparse text supervision isn't enough to properly calibrate a newly introduced modality like motion. UniMotion solves this with Latent Reconstruction Alignment (LRA), a self-supervised pre-training strategy. LRA uses dense motion latents as unambiguous conditions to co-calibrate the embedder, backbone, and flow head. This pre-training step ensures a stable, motion-aware foundation before tri-modal learning even begins, setting the stage for robust performance across all downstream tasks.
Performance That Speaks Volumes
The results from UniMotion are genuinely impressive, setting new state-of-the-art benchmarks across seven distinct tasks that involve understanding, generation, and editing across motion, text, and vision modalities. For a broader qualitative overview of its capabilities in both generation and captioning, see Figure 4.
- Motion Generation (Text-to-Motion): Figure 5 shows UniMotion produces motions with significantly closer prompt correspondence and more coherent temporal transitions compared to baselines like
MotionGPTandMoMask. It avoids common baseline errors such as missing body-part constraints or incorrect trajectories.
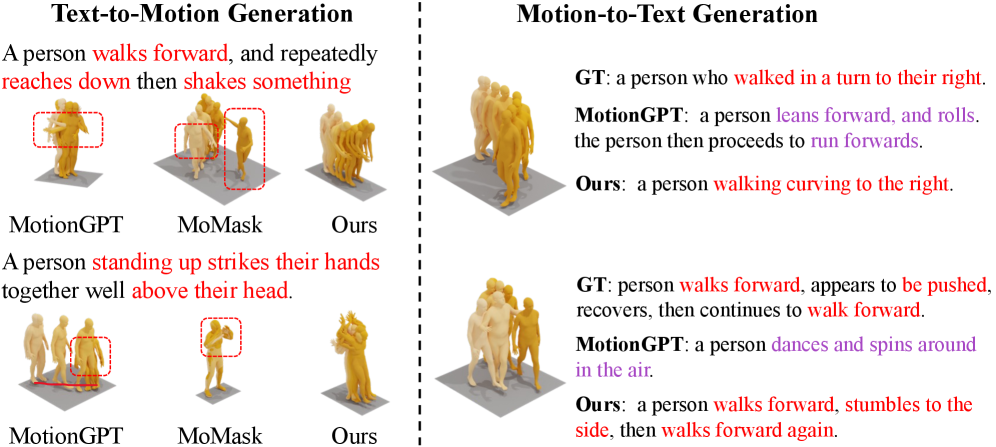 Figure 4: Qualitative comparison showing UniMotion's superior performance in both Text-to-Motion (T2M) generation and Motion-to-Text (M2T) captioning.
Figure 4: Qualitative comparison showing UniMotion's superior performance in both Text-to-Motion (T2M) generation and Motion-to-Text (M2T) captioning.
- Motion Captioning (Motion-to-Text): For tasks like
Motion-to-Text, UniMotion’s captions are more precise, translating fine-grained joint articulations and temporal sequences into accurate, fluent natural language. Figure 6 highlights how it avoids misaligned descriptions or hallucinated actions seen in other models.
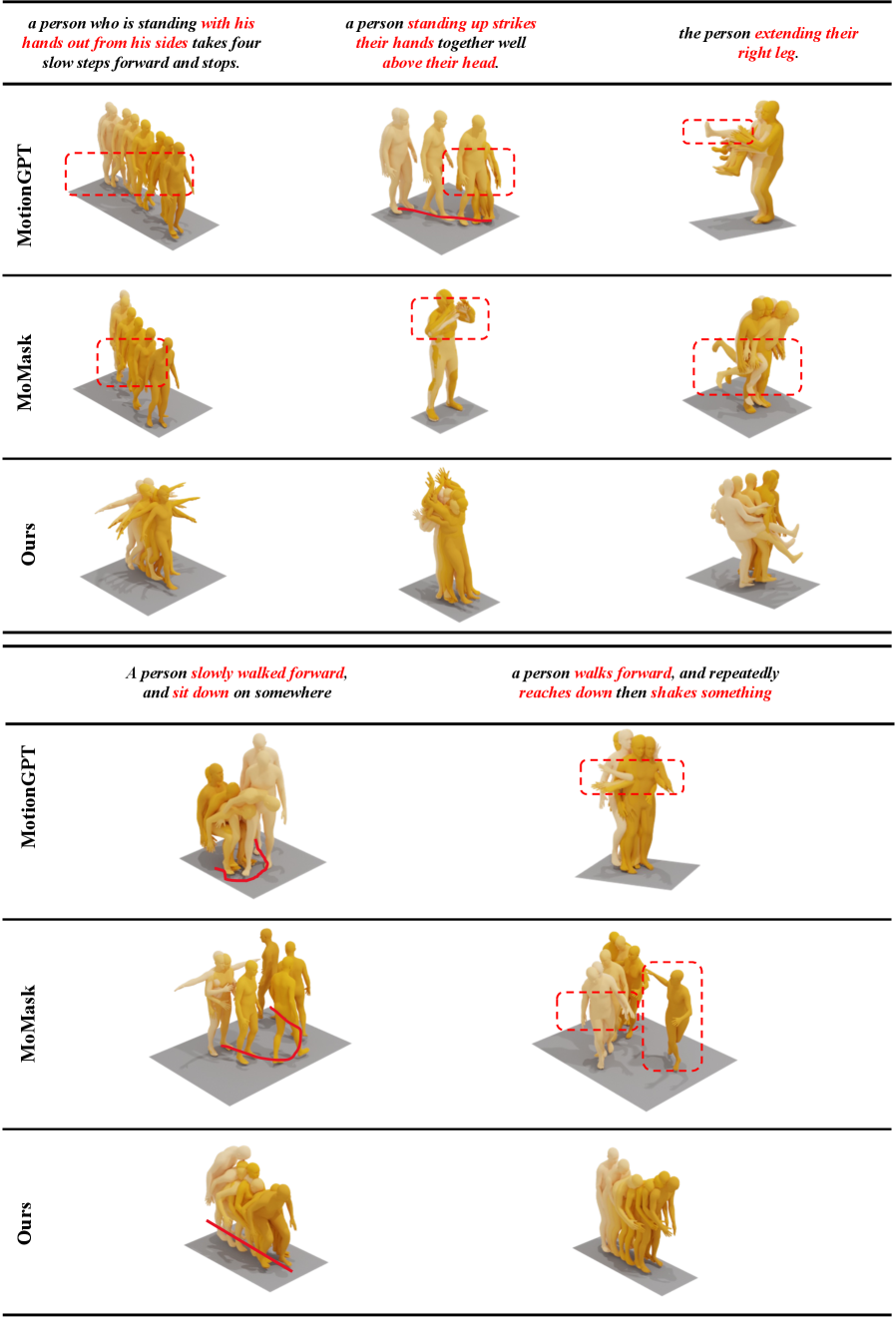 Figure 5: UniMotion generates motions that closely match text prompts, avoiding common errors in baseline models like MotionGPT and MoMask.
Figure 5: UniMotion generates motions that closely match text prompts, avoiding common errors in baseline models like MotionGPT and MoMask.
- Motion Prediction: UniMotion extrapolates future motion with superior consistency in global trajectory, body balance, and smooth joint evolution over longer horizons (Figure 7).
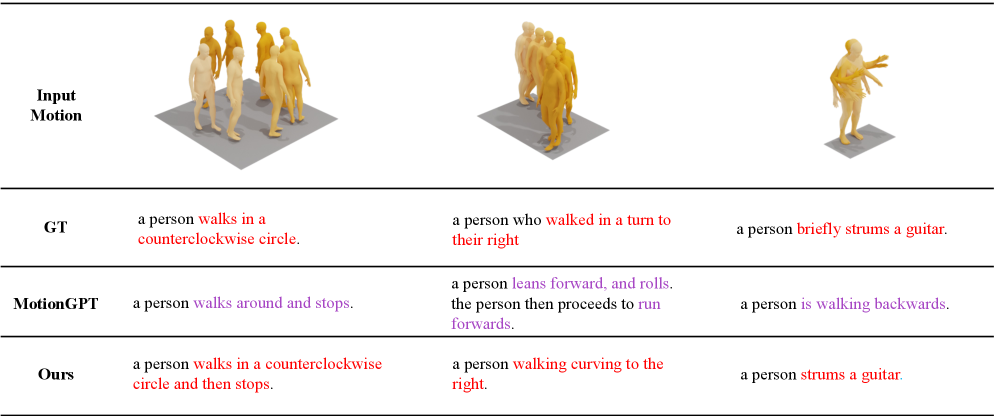 Figure 6: UniMotion provides more precise and accurate natural language descriptions of complex human motions compared to MotionGPT.
Figure 6: UniMotion provides more precise and accurate natural language descriptions of complex human motions compared to MotionGPT.
- Vision-to-Motion & Vision-to-Text: The framework demonstrates robust recovery of consistent body structure and accurate limb orientation from visual inputs (Figure 9), and generates concise, accurate descriptions of body configuration and actions from both static images and video sequences.
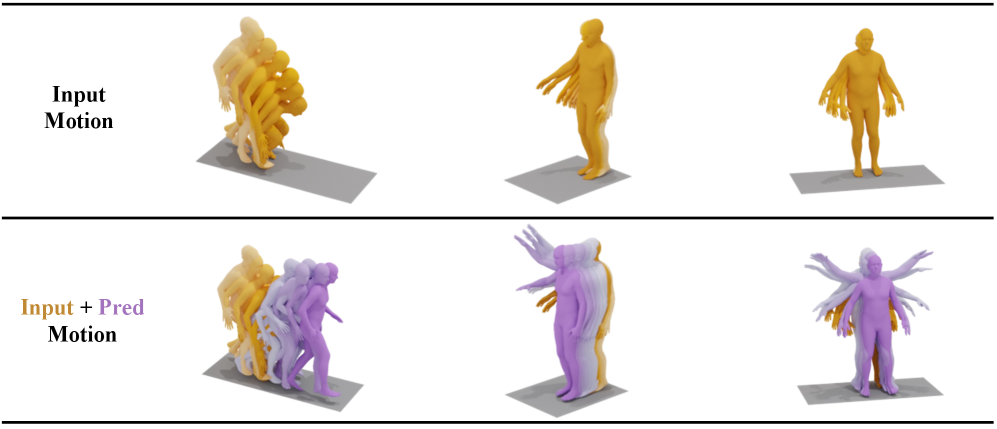 Figure 7: UniMotion demonstrates superior long-term motion prediction, maintaining consistent global trajectory and smooth joint evolution.
Figure 7: UniMotion demonstrates superior long-term motion prediction, maintaining consistent global trajectory and smooth joint evolution.
 Figure 9: UniMotion accurately recovers consistent body structure and limb orientation from sampled visual inputs.
Figure 9: UniMotion accurately recovers consistent body structure and limb orientation from sampled visual inputs.
These improvements aren't just incremental; they demonstrate a fundamental leap in how an AI can truly integrate and reason across these complex data streams.
How This Changes the Drone Game
For Mini Drone Shop readers, UniMotion isn't just academic; it’s a blueprint for the next generation of intelligent drones.
- Seamless Human-Drone Interaction: A drone that understands your hand gestures for 'follow me' or 'land here,' combined with verbal commands like 'scan that area.' UniMotion’s ability to interpret motion, text, and vision simultaneously means more natural, intuitive control without clunky interfaces. This could transform how drones assist in fieldwork, filmmaking, or even personal use.
- Predictive Surveillance and Security: Current surveillance drones can detect objects or people. UniMotion elevates this significantly. A drone could not only identify a person but interpret their body language (
Vision-to-Text,Vision-to-Motion), predict their next movements (Motion Prediction), and even understand verbal cues. This means moving beyond simple 'person detected' alerts to 'person scaling fence' or 'individual exhibiting distress signals,' offering genuinely actionable intelligence. - Highly Autonomous Navigation in Complex Environments: Navigating crowded urban areas or dynamic industrial sites is a nightmare for autonomous systems. UniMotion provides a framework for drones to understand human intent and movement patterns, predicting pedestrian paths (
Motion Prediction) and reacting intelligently. This leads to safer, more efficient navigation in environments shared with humans, minimizing collision risks and improving operational reliability. - Enhanced Inspection and Scene Understanding: Drones used for infrastructure inspection could not only capture images but also interpret the actions of ground crew, respond to verbal instructions, and even generate descriptive reports of observed human activities alongside visual data.
The Road Ahead: Current Limitations
While UniMotion represents a significant leap, it's essential to consider its current limitations for practical drone applications.
- Computational Overhead: Running an
LLMbackbone with multiple continuous pathways for high-resolution vision and complex motion processing will likely demand substantial computational resources. For small, power-constrained mini-drones, this could mean offloading processing to a ground station or using specialized, power-efficientedge AIhardware, which isn't explicitly addressed. - Focus on Human Motion: The paper primarily focuses on human motion. While crucial for many applications, drones interact with a broader world of objects, animals, and other vehicles. Extending UniMotion to understand and generate motions for diverse entities would be a necessary next step for broader utility.
- Real-world Robustness: The training datasets, while extensive, might not fully capture the chaotic, unpredictable nature of real-world drone environments. Factors like adverse weather, low light, occlusions, or extreme angles could still challenge the system's perception and interpretation capabilities.
- Deployment Complexity: Integrating such a complex, unified framework into existing drone operating systems (e.g.,
PX4,ArduPilot) and hardware platforms would require significant engineering effort, beyond the scope of this research paper.
Can You Build This at Home?
For the ambitious drone builder or hobbyist, replicating UniMotion in its entirety is currently a monumental task. This isn't a simple off-the-shelf library. The framework relies on a large language model backbone and extensive pre-training, demanding significant computational resources – think multiple high-end NVIDIA A100 or H100 GPUs for training. The paper doesn't explicitly mention public code releases, which is common for cutting-edge research. However, the modular nature, particularly the CMA-VAE and the continuous latent spaces, provides conceptual avenues for future, smaller-scale implementations or specialized components that could be adapted for specific drone tasks once more open-source tools emerge from similar research.
Building on the Shoulders of Giants
UniMotion doesn't exist in a vacuum; it builds upon and complements other crucial advancements in AI. For instance, while UniMotion provides a robust framework for understanding and generating motion, VideoDetective (Yang et al., 2026) offers solutions for sifting through long video footage – a common drone output – to find specific, query-relevant 'clues.' This pairing could mean a drone not only understands what's happening but can efficiently extract key events from hours of recorded flight. Similarly, UniMotion's understanding capabilities are further enhanced by models like ThinkJEPA (Zhang et al., 2026), which focuses on empowering latent world models with vision-language reasoning for forecasting future states. A drone equipped with UniMotion could understand human actions and then use ThinkJEPA-like capabilities to predict their next moves, leading to more proactive and intelligent autonomy. The foundational understanding of how Vision-Language Models (VLMs) perform spatial reasoning, as explored in 'The Dual Mechanisms of Spatial Reasoning in Vision-Language Models' (Cui et al., 2026), is also critical for UniMotion's ability to interpret human actions and navigate complex environments. And at a more fundamental level, the ability of UniMotion to interpret motion relies on accurate motion perception, where unsupervised methods like GenOpticalFlow (Luo et al., 2026) provide essential, data-efficient ways for a drone to perceive optical flow in dynamic scenes, feeding into UniMotion's higher-level interpretations.
UniMotion pushes the boundaries of how AI can interpret the world, moving us closer to drones that don't just see and hear, but truly understand the intricate dance of human interaction. The future of human-drone collaboration just got a lot more articulate.
Paper Details
Title: UniMotion: A Unified Framework for Motion-Text-Vision Understanding and Generation Authors: Ziyi Wang, Xinshun Wang, Shuang Chen, Yang Cong, Mengyuan Liu Published: March 2026 arXiv: 2603.22282 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.