Unmasking AI's Lies: Diagnosing VLM Hallucinations for Trustworthy Drones
New research introduces a multi-stage diagnostic framework to pinpoint the root causes of Vision-Language Model hallucinations. It moves beyond simple error detection, explaining *why* AI misinterprets reality—a crucial step for trustworthy autonomous drone operations.
TL;DR: This research introduces a framework that dissects Vision-Language Model (
VLM) hallucinations. It doesn't just identify them, but diagnoses the underlying 'cognitive failures'—things like perceptual confusion or logical inconsistencies. For autonomous drones, this means we can finally understand why an AI misinterprets its environment, paving the way for more reliable and auditable systems.
Autonomous drones promise incredible capabilities, from complex inspections to precision deliveries. But what happens when a drone's onboard AI confidently asserts a clear path, only to fly directly into an obstacle? That's not just a bug; it's a hallucination—a plausible but factually incorrect statement generated by a Vision-Language Model (VLM) that misinterprets its visual input. This new paper tackles that core problem head-on, moving beyond simply spotting errors to actively dissecting why these errors occur.
The Black Box Problem: Why Current Hallucination Checks Fall Short
Today, catching VLM hallucinations often relies on post-hoc accuracy checks or confidence scores. The problem? A VLM can be highly confident in a completely false statement. It's a classic black box issue: we see the wrong output, but we don't know if the AI misinterpreted the initial image, made a logical leap, or was simply indecisive. For drone developers, this is a nightmare. Debugging becomes guesswork, and ensuring safety in critical applications is nearly impossible. Current methods don't offer the granular detail needed to understand the failure, let alone fix it. We need more than just a PASS/FAIL indicator; we need a diagnostic report.
Tracing the 'Lie': How Cognitive Probes Uncover Failure
This research proposes a new way to understand VLM hallucinations, treating them not as static output errors, but as dynamic 'pathologies.' The core idea is to model a VLM's generation process as a "cognitive trajectory" moving through an interpretable, low-dimensional Cognitive State Space. The researchers designed a suite of information-theoretic probes to map this trajectory, essentially giving us a peek inside the VLM's 'mind.'
Specifically, they identify three key pathological states:
- Perceptual Instability (measured by
Perceptual Entropy): This asks, "Did the model accurately 'see' the initial evidence?" High entropy here indicates perceptual confusion or hallucination right at the visual interpretation stage. - Inferential Conflict: Did the model contradict itself or its initial interpretations during its reasoning process? This flags logical-causal failures.
- Decisional Ambiguity (measured by
Decision Entropy): Was the model uncertain or indecisive about its final output? This points to a lack of clear commitment.
These probes project the VLM's internal states, revealing a "geometric-information duality": a geometrically abnormal trajectory in this cognitive space is equivalent to high information-theoretic surprisal, which strongly indicates a hallucination. Essentially, hallucination detection becomes an anomaly detection problem using a Gaussian Mixture Model (GMM) to identify these abnormal trajectories.
Consider Figure 1, for instance. Here, a VLM hallucinates a 'motorcycle' from a 'cyclist' (a clear perceptual failure), then contradicts this false evidence with a 'No' answer (a logical failure), yet still coincidentally gets the answer correct. Traditional accuracy metrics would completely miss this cascade of errors. This new framework, however, catches both the high Perceptual Instability (c) and the Inferential Conflict (d), providing a precise diagnosis.
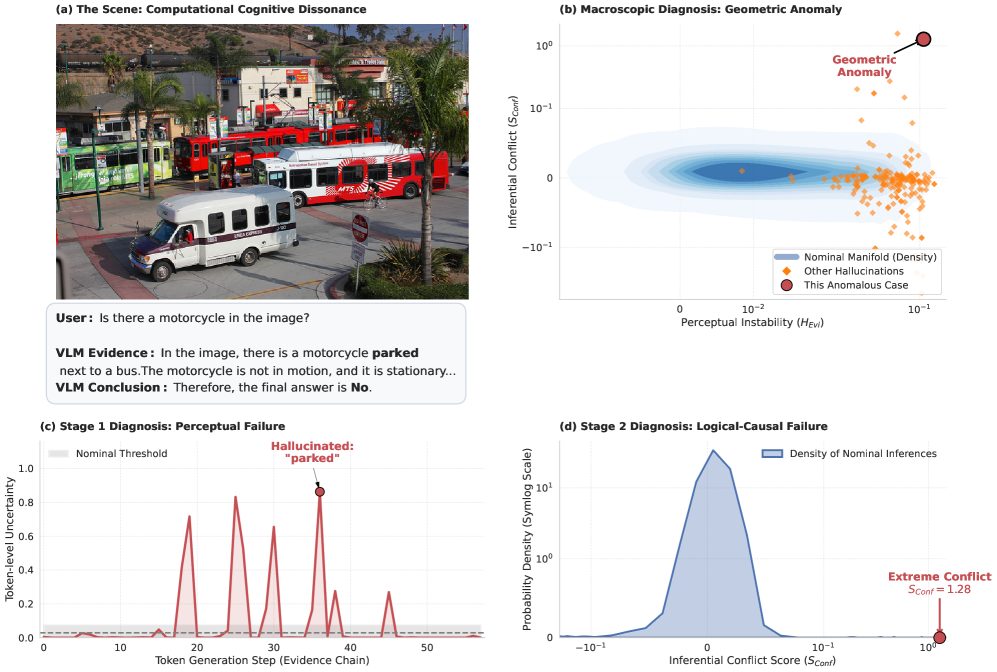 Figure 1: An example of computational cognitive dissonance in Idefics2, where a cascade of failures leads to a coincidentally correct answer. (1) Perceptual Failure: The model hallucinates a ‘motorcycle’ in the evidence chain, an object not present in the image (a cyclist is visible). Our framework captures this as high Perceptual Instability (see panel (c)). (2) Logical Failure: The model then contradicts its own faulty evidence, concluding the final answer is ‘No’. This breakdown of self-consistency is diagnosed as extremely high Inferential Conflict (see panel (d)). This case study demonstrates the limitation of accuracy-only evaluations and highlights our framework’s ability to perform a stage-by-stage differential diagnosis of a VLM’s cognitive process, identifying complex, multi-stage failure trajectories.
Figure 1: An example of computational cognitive dissonance in Idefics2, where a cascade of failures leads to a coincidentally correct answer. (1) Perceptual Failure: The model hallucinates a ‘motorcycle’ in the evidence chain, an object not present in the image (a cyclist is visible). Our framework captures this as high Perceptual Instability (see panel (c)). (2) Logical Failure: The model then contradicts its own faulty evidence, concluding the final answer is ‘No’. This breakdown of self-consistency is diagnosed as extremely high Inferential Conflict (see panel (d)). This case study demonstrates the limitation of accuracy-only evaluations and highlights our framework’s ability to perform a stage-by-stage differential diagnosis of a VLM’s cognitive process, identifying complex, multi-stage failure trajectories.
This methodology essentially gives us a real-time 'brain scan' of the VLM, revealing its internal state and pinpointing exactly where its reasoning went off the rails. Figure 3 further illustrates these unique "Cognitive Fingerprints"—distinct failure signatures for different models, showing how their internal states diverge when hallucinating versus generating factual outputs.
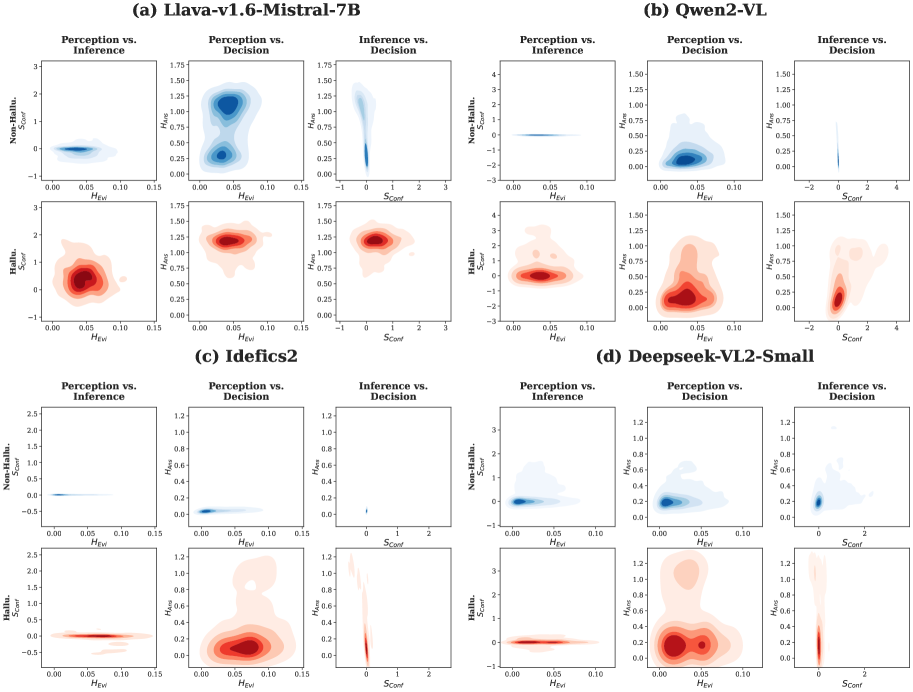 Figure 3: Visualizing the ‘Cognitive Fingerprints’ of Hallucination. Density projections of the 3D Cognitive State Space, separated into non-hallucinatory (blue, top row of each pair) and hallucinatory (red, bottom row of each pair) processes. These manifolds reveal unique failure signatures for each model.
Figure 3: Visualizing the ‘Cognitive Fingerprints’ of Hallucination. Density projections of the 3D Cognitive State Space, separated into non-hallucinatory (blue, top row of each pair) and hallucinatory (red, bottom row of each pair) processes. These manifolds reveal unique failure signatures for each model.
Performance That Matters: Robust and Efficient Diagnosis
The framework isn't just conceptually sound; it delivers strong practical results across various benchmarks:
- State-of-the-art detection: It achieves superior performance in hallucination detection across diverse settings, including binary QA (
POPE), comprehensive reasoning (MME), and open-ended captioning (MS-COCO). - High efficiency: The system operates effectively even with weak supervision, requiring minimal calibrated data.
- Robustness: It maintains high performance, even when calibration data is significantly contaminated (up to 30% hallucinatory samples).
- Low
FPR: As Figure 2 highlights, the framework dominates in the critical low-False Positive Rate regime (FPR < 10^-2). This is essential for real-world reliability, where false alarms can be incredibly costly.
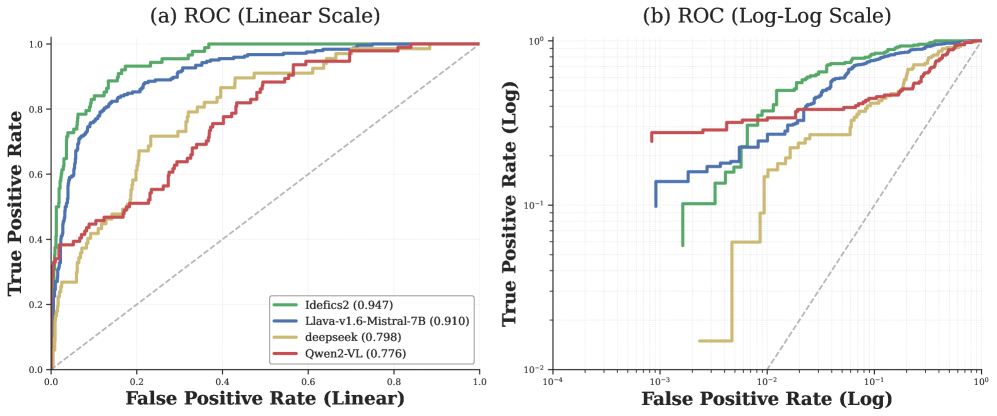 Figure 2: ROC curves of our Cognitive Anomaly Detection (CAD) framework. (a) Linear-scale ROC curves show superior overall performance across all architectures. (b) log-log curves highlight CAD’s dominance in the critical low-FPR regime (FPR<10−2), which is essential for reliable real-world deployment.
Figure 2: ROC curves of our Cognitive Anomaly Detection (CAD) framework. (a) Linear-scale ROC curves show superior overall performance across all architectures. (b) log-log curves highlight CAD’s dominance in the critical low-FPR regime (FPR<10−2), which is essential for reliable real-world deployment.
Figure 4 further demonstrates the synergistic gain of combining these different diagnostic probes. Using them together dramatically outperforms any single metric, underscoring the importance of a multi-faceted approach to uncovering VLM failures.
 Figure 4: Ablation Study. (a) Standalone metrics vs. synergistic gain. The gray hatched area represents the Synergy Gain. (b) Impact of component removal (ΔAUC), revealing model-specific ‘diagnostic fingerprints’.
Figure 4: Ablation Study. (a) Standalone metrics vs. synergistic gain. The gray hatched area represents the Synergy Gain. (b) Impact of component removal (ΔAUC), revealing model-specific ‘diagnostic fingerprints’.
Even for open-ended captioning, where detecting hallucinations is notoriously difficult, the Perceptual Instability probe (HEvi) consistently assigned significantly higher entropy to hallucinatory captions compared to factual ones (as shown in Figure 5 of the paper). This suggests the probes capture fundamental cognitive signatures of hallucination, regardless of the VLM task format.
Why This Matters for Autonomous Drones
For drone builders and engineers, this research is a significant step forward. It's not just about knowing that your drone's AI made a mistake, but why. This level of diagnostic capability is crucial for:
- Enhanced Safety: Pinpointing perceptual or logical failures before a drone acts on incorrect information could prevent collisions or misidentifications in critical missions.
- Transparent AI: Developers can now audit the reasoning process of their drone's
VLM. If a drone identifies a target incorrectly, we can trace whether it initially misidentified the object (a perceptual failure) or reasoned poorly from correct observations (an inferential failure). - Faster Debugging and Development: With precise error attribution, developers can more efficiently identify and fix issues in their
VLMarchitectures or training data, leading to more robust drone autonomy. - Trustworthy Deployment: For regulatory bodies and end-users, knowing that a drone's AI can be diagnosed for its internal reasoning failures builds critical trust in its autonomous capabilities.
This framework moves us closer to AI systems whose reasoning is not just accurate, but also transparent, auditable, and diagnosable by design—a fundamental requirement for truly reliable autonomous flight.
Limitations & What's Missing
While this framework marks a significant step forward, it's important to acknowledge its current scope and limitations:
- Diagnosis, Not Cure: The paper focuses on diagnosing hallucinations, not automatically correcting them. It tells you what went wrong and where, but the actual fix still requires human intervention or further research into self-correction mechanisms.
- Computational Overhead: Running these diagnostic probes in real-time on resource-constrained edge hardware (like a mini-drone) could introduce latency or require dedicated processing. While the efficiency for detection is high, integrating the full diagnostic suite for real-time, low-power applications will need further optimization.
- Model Internal Access: The framework relies on accessing internal activations and states of the
VLM. This isn't always straightforward with proprietary models or highly optimized deployment models where these intermediate states might be less accessible or harder to interpret. - Calibration Data Dependency: Although robust to contamination, initial calibration data is still needed to train the
GMMand define the 'normal' cognitive space. Acquiring this clean, representative data can be a challenge in diverse real-world drone environments.
DIY Feasibility for Advanced Builders
For hobbyists keen on pushing the boundaries, replicating this research isn't a weekend project, but it's certainly within reach for advanced builders with a strong programming background. The core components—information-theoretic probes and GMM-based anomaly detection—are implementable using standard Python libraries (scikit-learn, SciPy).
However, the real challenge lies in integrating these probes into existing VLM architectures. You'd need a VLM where you can access internal layer activations (e.g., Llama.cpp with Llava, or HuggingFace models). Understanding the VLM's architecture and how to extract meaningful intermediate representations is key. This isn't a plug-and-play solution, but it offers a solid foundation for those looking to build more robust and debuggable drone AI systems.
This work directly addresses issues highlighted in related research. For instance, it provides a lens to understand the struggles of Vision-Language-Action (VLA) models in dynamic environments, as discussed in "Towards Generalizable Robotic Manipulation in Dynamic Environments." Understanding why a VLA model fails in a dynamic scenario, rather than just that it fails, is paramount. Similarly, improvements to foundational visual understanding, like those explored in "Look Before Acting: Enhancing Vision Foundation Representations for Vision-Language-Action Models," can directly reduce the perceptual failures diagnosed by this framework. By making VLMs more 'active critics' of their own outputs, as suggested by "From Passive Observer to Active Critic: Reinforcement Learning Elicits Process Reasoning for Robotic Manipulation," we can build models inherently less prone to generating incorrect information. Finally, robust testing in environments like the "Grounding World Simulation Models in a Real-World Metropolis" would be invaluable for uncovering and validating these diagnostic capabilities under realistic, complex conditions.
Ultimately, building autonomous drones you can truly trust means moving beyond simple performance metrics. It means demanding transparency, understanding their mistakes, and building systems that can tell us when they're about to 'lie.' This research provides crucial tools to start that conversation, making our drone AI not just smarter, but inherently more honest.
Paper Details
Title: Anatomy of a Lie: A Multi-Stage Diagnostic Framework for Tracing Hallucinations in Vision-Language Models Authors: Lexiang Xiong, Qi Li, Jingwen Ye, Xinchao Wang Published: March 2026 arXiv: 2603.15557 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.