Unsupervised Optical Flow: Smarter Drone Vision Without the Data Grind
GenOpticalFlow synthesizes motion data, allowing drones to learn complex optical flow without expensive human annotations. This accelerates autonomous capabilities for builders and engineers.
TL;DR: GenOpticalFlow introduces a novel way to train optical flow models without relying on costly human-labeled datasets. It generates synthetic, perfectly aligned frame-flow pairs, leading to more robust motion understanding for drones and other autonomous systems. This method promises faster, more affordable development of sophisticated drone autonomy.
Unlocking Smarter Drone Vision
Understanding how objects move in a scene is fundamental for any autonomous system, especially drones navigating dynamic environments. For years, training drones to "see" motion accurately has been a bottleneck, demanding vast, meticulously labeled datasets that are both expensive and time-consuming to produce. This new work, GenOpticalFlow, tackles that head-on by flipping the script: instead of labeling real-world motion, it generates it.
The Data Bottleneck in Drone Motion Sensing
Optical flow, the apparent motion of objects, surfaces, and edges in a visual scene, is critical for drone tasks like obstacle avoidance, precise landing, and even following a target. The gold standard for training these systems relies on supervised learning, which means every pixel's movement between frames needs to be manually annotated – a truly monumental task for real-world scenarios. Unsupervised and semi-supervised methods have tried to circumvent this by using brightness constancy and smoothness assumptions, but these often fall apart in complex, real-world drone footage with varying lighting, occlusions, and fast motion. The result? Less reliable motion estimates, which translate directly to less trustworthy autonomy and more development costs for builders.
GenOpticalFlow's Clever Twist: Generating Its Own Ground Truth
GenOpticalFlow takes a clever, generative approach to sidestep the annotation problem. It doesn't try to infer flow from real images directly; instead, it synthesizes its own perfectly aligned training data. The core idea is to leverage a pre-trained depth estimation network to create pseudo optical flows from a single input image. Think of it as predicting how an image would change if the camera moved in a certain way, based on its depth.
This pseudo optical flow then becomes a conditioning input for a next-frame generation model. This model is trained to take an initial frame and the generated pseudo optical flow, and then accurately predict what the subsequent frame should look like. The magic here is that because the model generates the next frame based on a known flow, it inherently creates perfectly aligned frame-flow data pairs without any human intervention. This is a crucial distinction: it's not trying to guess the flow; it's using a generated flow to synthesize a consistent next frame, thus creating its own ground truth.
Building the Synthetic World: How GenOpticalFlow Works
 Figure 1: Visualization of the synthesized data triplet on KITTI2012, including the reference frame $I_{t}$, the artificially generated optical flow $\tilde{F}{t \to t+1}$, and the conditioned next-frame generation prediction result $\tilde{I}{t+1}$.
Figure 1: Visualization of the synthesized data triplet on KITTI2012, including the reference frame $I_{t}$, the artificially generated optical flow $\tilde{F}{t \to t+1}$, and the conditioned next-frame generation prediction result $\tilde{I}{t+1}$.
The architecture involves a semantic preserver network to extract high-level features and a diffusion model conditioned on 2D coordinate embeddings and warped coordinate embeddings. This setup helps the model learn the geometric warping needed for accurate pixel-level motion and novel view generation. To refine this further, they employ an inconsistent pixel filtering strategy. This step identifies and discards pixels in the generated frames that don't quite match up or seem unreliable, which helps clean up the synthetic dataset and improves fine-tuning on actual real-world data.
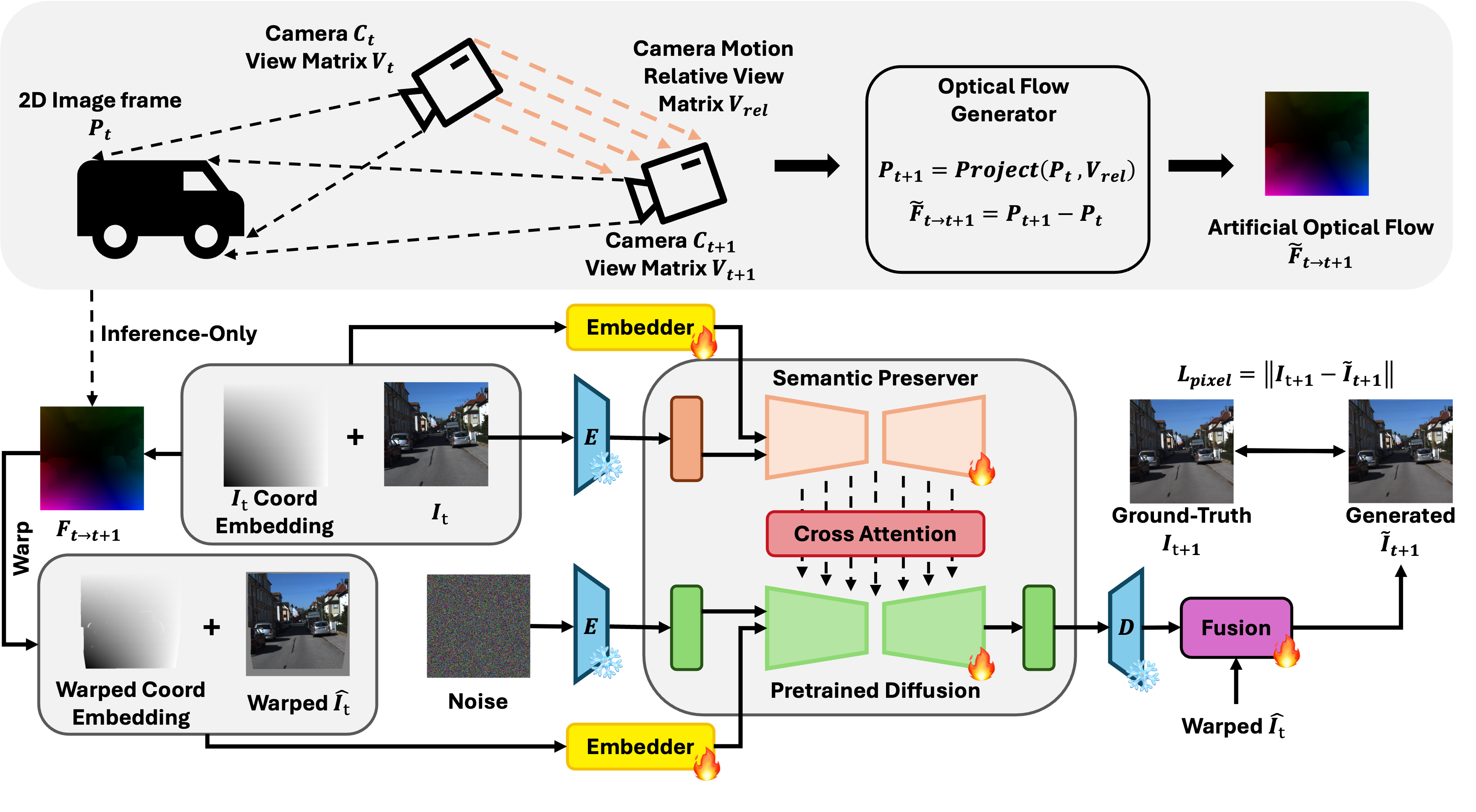 Figure 2: Overview of the conditioned next-frame framework and artificial optical flow generation. Given an input view and its corresponding optical flow, our framework constructs two types of embeddings: a 2D coordinate embedding of the input view and a warped coordinate embedding of the target view derived from the optical flow. A semantic preserver network extracts high-level semantic features from the input view, while a diffusion model conditioned on these embeddings learns the geometric warping necessary to generate the novel view and accurately align pixel-level motion. To further enhance spatial correspondence, we augment the self-attention mechanism with cross-view attention and jointly aggregate features across views. Notably, ground-truth optical flow is used only during pre-training, while synthetic datasets are constructed using artificial optical flow produced via a geometry-based camera-motion model.
Figure 2: Overview of the conditioned next-frame framework and artificial optical flow generation. Given an input view and its corresponding optical flow, our framework constructs two types of embeddings: a 2D coordinate embedding of the input view and a warped coordinate embedding of the target view derived from the optical flow. A semantic preserver network extracts high-level semantic features from the input view, while a diffusion model conditioned on these embeddings learns the geometric warping necessary to generate the novel view and accurately align pixel-level motion. To further enhance spatial correspondence, we augment the self-attention mechanism with cross-view attention and jointly aggregate features across views. Notably, ground-truth optical flow is used only during pre-training, while synthetic datasets are constructed using artificial optical flow produced via a geometry-based camera-motion model.
The result is a vast, high-quality synthetic dataset that directly addresses the data scarcity problem for optical flow.
 Figure 3: Qualitative results of optical flow generation on the KITTI (top) and Sintel (bottom) datasets. In each panel, the first row displays the conditioning input frame, while the second row visualizes a corresponding optical flow map randomly sampled from our model. The results highlight the model’s ability to generate dense, structurally aligned flow predictions across varying scene complexities.
Figure 3: Qualitative results of optical flow generation on the KITTI (top) and Sintel (bottom) datasets. In each panel, the first row displays the conditioning input frame, while the second row visualizes a corresponding optical flow map randomly sampled from our model. The results highlight the model’s ability to generate dense, structurally aligned flow predictions across varying scene complexities.
 Figure 4: Visualization of next-frame generation results. The figure demonstrates the temporal consistency of our method on the KITTI and Sintel benchmarks. The top rows show the reference input frames, while the bottom rows display the synthesized next frames. Our framework effectively preserves texture details and object geometry during the generation process.
Figure 4: Visualization of next-frame generation results. The figure demonstrates the temporal consistency of our method on the KITTI and Sintel benchmarks. The top rows show the reference input frames, while the bottom rows display the synthesized next frames. Our framework effectively preserves texture details and object geometry during the generation process.
Real-World Impact: Performance Benchmarks
The paper reports solid performance on standard benchmarks like KITTI2012, KITTI2015, and Sintel.
- On KITTI2012, GenOpticalFlow achieves an End-Point Error (EPE) of 2.97, outperforming several unsupervised methods and even some semi-supervised ones. For context, popular unsupervised methods often sit around 3.5-4.0 EPE.
- On KITTI2015, it hits an EPE of 5.81, which is competitive with or better than state-of-the-art unsupervised approaches.
- For the more challenging Sintel dataset (clean pass), GenOpticalFlow scores an EPE of 4.68, again showing its robustness compared to its peers.
These numbers indicate that generating data, rather than relying on imperfect real-world labels or assumptions, leads to more accurate and reliable optical flow predictions. The method demonstrates it can learn dense, structurally aligned flow predictions across varying scene complexities, as seen in their qualitative results.
Beyond the Lab: What This Means for Drone Autonomy
This research is a significant step towards truly autonomous drones.
- Cost Reduction: Eliminating the need for human-labeled datasets drastically cuts development costs. Drone startups and hobbyists can iterate faster without breaking the bank on data annotation.
- Faster Development Cycles: Builders can train robust optical flow models on demand, adapting to new sensor types or environments more quickly. This means quicker prototyping and deployment of advanced features.
- Enhanced Autonomy: More accurate optical flow directly translates to:
- Better Obstacle Avoidance: Drones can precisely detect and react to moving objects in cluttered environments.
- Precise Navigation and Landing: Improved motion sensing for stable flight, especially in GPS-denied or indoor scenarios.
- Robust Object Tracking: For surveillance, inspection, or cinematography drones, the ability to track targets with high precision is critical.
- Swarm Coordination: Groups of drones could understand each other's and external objects' movements more coherently, leading to safer and more efficient swarm behaviors.
Essentially, GenOpticalFlow makes the underlying "vision" smarter and more accessible, paving the way for more agile, reliable, and intelligent drones that can operate in complex, dynamic real-world settings.
Navigating the Hurdles: Limitations of GenOpticalFlow
While promising, GenOpticalFlow isn't a silver bullet.
- Dependency on Depth Networks: The initial
pseudo optical flowrelies on a pre-trained depth estimation network. The quality and generalization of this depth network directly impact the quality of the synthetic data. If the depth network struggles in certain environments (e.g., highly reflective surfaces, transparent objects, or very textureless areas), the generated flow might inherit these inaccuracies. - Computational Cost of Generation: While it avoids annotation costs, the generative process itself, especially using diffusion models, can be computationally intensive during training. This might require significant GPU resources to synthesize large datasets, potentially shifting the cost from human labor to computational power.
- Real-world vs. Synthetic Gap: Despite the "inconsistent pixel filtering" strategy, a gap between synthetic and real-world data will always exist. Fine-tuning on real data is still necessary for optimal performance, meaning some amount of real-world data (even unlabeled) is still beneficial for deployment. The paper's results show superior unsupervised performance, but supervised methods with perfect ground truth still often achieve lower EPEs.
- Dynamic Scene Complexity: While it performs well on benchmarks, highly dynamic and unpredictable drone environments (e.g., fast-moving foliage, sudden occlusions, extreme lighting changes during flight) might still pose challenges for the generative model to perfectly replicate and learn from. The current model might not capture all real-world edge cases in its synthetic data.
From Research to Reality: Accessibility for Builders
Replicating GenOpticalFlow from scratch for a hobbyist would be a significant undertaking, primarily due to the computational demands and the complexity of the model architecture (diffusion models, semantic preserver networks, etc.). Training such a system would require multiple high-end NVIDIA GPUs, likely an RTX 3090 or RTX 4090, and substantial expertise in deep learning frameworks like PyTorch.
However, the authors state they "will release our code upon acceptance," which is great news. If the code is well-documented and the pre-trained models are provided, hobbyists and small teams could potentially leverage the generated datasets or fine-tune the pre-trained optical flow model on their specific drone footage. This would democratize access to high-quality unsupervised optical flow. Building the generative component from the ground up, however, is a research-level project.
A Broader Horizon: Connections to Other AI Innovations
This work sits at an interesting intersection of generative AI and computer vision, with implications for several other drone-related research areas. For instance, the ability to generate high-fidelity frame-flow data directly supports advancements in multi-view diffusion models, like those explored in "Repurposing Geometric Foundation Models for Multi-view Diffusion." Understanding motion is a prerequisite for consistent 3D reconstructions and novel view synthesis, which are critical for advanced drone mapping and immersive FPV experiences.
Furthermore, improved optical flow can feed into higher-level video understanding tasks. As drones capture increasingly long and complex video streams for surveillance or inspection, tools like VideoDetective (from "VideoDetective: Clue Hunting via both Extrinsic Query and Intrinsic Relevance for Long Video Understanding") become essential. Optical flow provides the low-level motion clues that such MLLMs (multimodal large language models) could leverage to efficiently "hunt for clues" in vast amounts of footage, making drone data analysis far more productive.
Finally, the computational intensity of models like GenOpticalFlow highlights the need for efficiency. "WorldCache: Content-Aware Caching for Accelerated Video World Models" directly addresses this by optimizing Diffusion Transformers (DiTs) for video world models. The techniques in WorldCache could be crucial for deploying complex optical flow and video understanding models on resource-constrained drone edge devices, turning research breakthroughs into practical, real-time capabilities.
The Future is Flying Smarter
GenOpticalFlow offers a compelling path forward for building smarter drone vision systems without the traditional data bottleneck, pushing us closer to truly autonomous, adaptable airborne platforms.
Paper Details
Title: GenOpticalFlow: A Generative Approach to Unsupervised Optical Flow Learning Authors: Yixuan Luo, Feng Qiao, Zhexiao Xiong, Yanjing Li, Nathan Jacobs Published: March 2026 arXiv: 2603.22270 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.