AI's New Playbook for Robot Teams: Smarter Drone & Ground Coordination
New research unveils a collaborative AI planning strategy using Multi-Agent Proximal Policy Optimization (MAPPO) to coordinate diverse robot teams, including drones, for complex tasks. It efficiently allocates tasks and paths, significantly outperforming classical methods in speed.
TL;DR: New research shows how AI, specifically Multi-Agent Proximal Policy Optimization (MAPPO), can efficiently coordinate diverse robot teams—think drones and ground robots—to tackle complex missions. This approach significantly speeds up task and path planning compared to traditional methods, enabling real-time replanning for dynamic environments.
Orchestrating the Robotic Dream Team
For drone operators, builders, and engineers, the future isn't just about what a single drone can do. It's about what a fleet of specialized robots, including drones, can achieve when working together seamlessly. We're talking about missions far too complex or dangerous for one machine, from surveying vast construction sites to exploring remote, hazardous terrains. This paper from Rubio, Richter, Kolvenbach, and Hutter dives into exactly that: how AI is learning to orchestrate these multi-robot "dream teams."
The Coordination Conundrum
Coordinating a team of heterogeneous robots, each with distinct capabilities like flight, walking, or driving, is a monumental challenge. Current planning algorithms struggle with scale; as you add more robots or more tasks, the number of possible allocations and paths explodes combinatorially. This leads to prohibitively long planning cycles and high computational costs, making real-time adaptation in dynamic environments practically impossible. For critical applications like planetary exploration or industrial inspection, this delay means wasted time, resources, or even mission failure. Traditional methods simply can't keep up with the demands of dynamic, complex multi-robot operations.
Learning the Ropes: How AI Takes Charge
The core of this research is a collaborative planning strategy built on Multi-Agent Proximal Policy Optimization (MAPPO). Instead of brute-forcing every possible solution, which is what classical methods often attempt, this AI learns optimal task allocation and path planning through repeated trials. Each robot in the team, whether a drone, a legged robot, or a rover, acts as an agent within the MAPPO framework, learning to make decisions that benefit the entire team and minimize mission time.
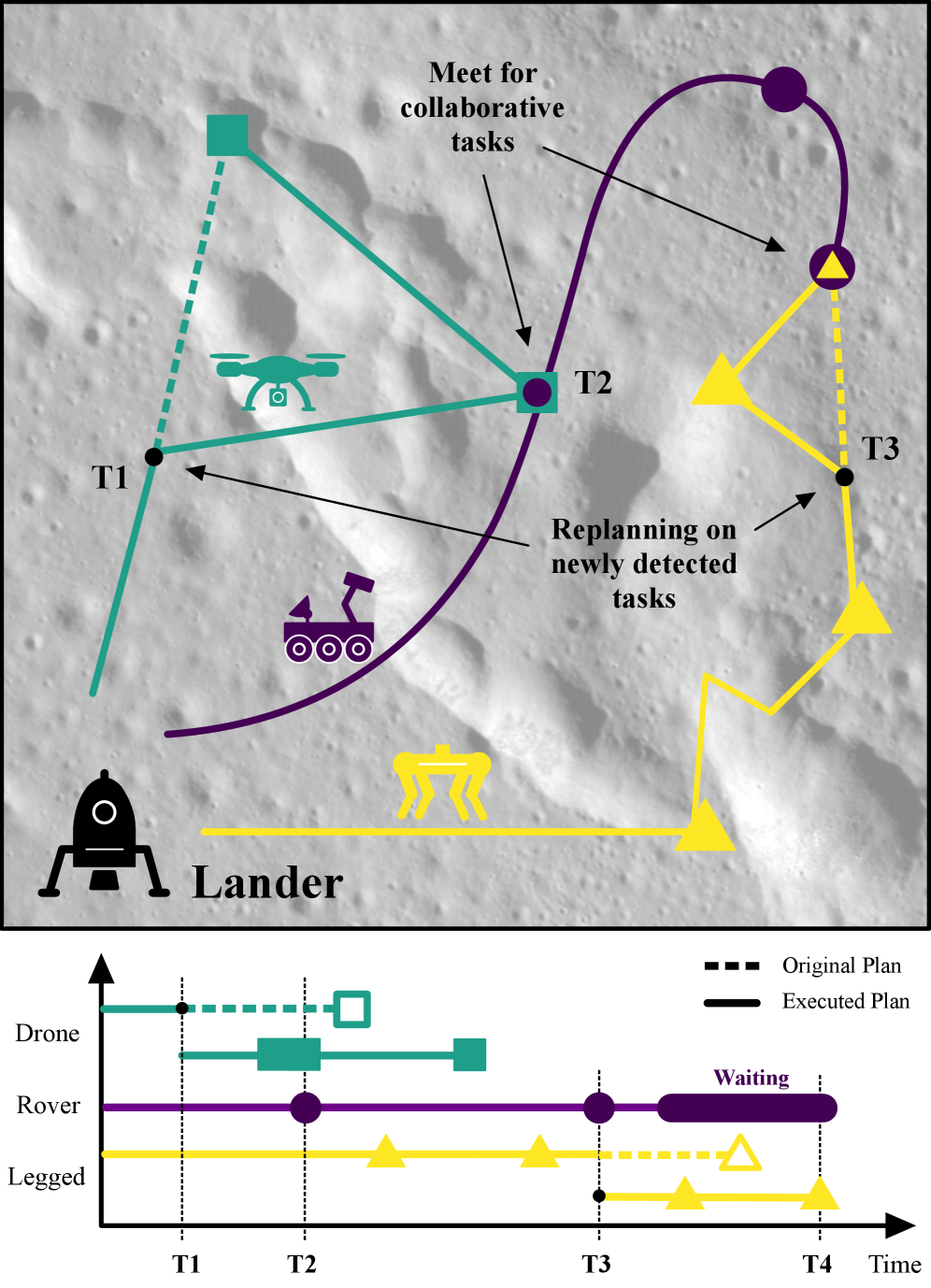 Figure 1: An illustrative plan for a collaborative robot fleet with different specializations, such as flying, walking, or driving. During the mission the drone and the legged robot find new tasks and replan to minimize mission time.
Figure 1: An illustrative plan for a collaborative robot fleet with different specializations, such as flying, walking, or driving. During the mission the drone and the legged robot find new tasks and replan to minimize mission time.
The system uses a centralized training, decentralized execution paradigm. During training, a central coordinator provides a global reward signal, guiding all agents to learn policies that maximize the team's efficiency. In execution, each robot uses its learned policy independently, making decisions based on its local observations and the shared understanding of the mission goals. This allows for fast, on-the-fly replanning when new tasks emerge or conditions change, a critical feature for real-world deployment.
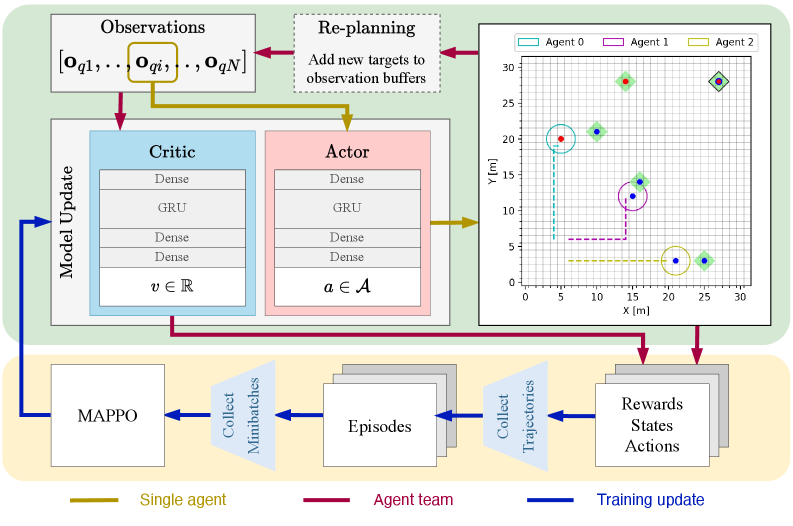 Figure 2: This figure illustrates the complete workflow, highlighting both the execution (green) and training (yellow) phases. The execution block details the network architectures and the placement of the replanning step. The training block shows the MAPPO update sequence. The colored arrows differentiate data flow, specifying whether it applies to all agents, a single agent, or represents aggregated data for training. Furthermore, the environment is visualized as a grid, including the agents and targets with their provided or required skills (colored dots). The targets are marked with a green square, which can have a black border indicating a collaborative target (AND type).
Figure 2: This figure illustrates the complete workflow, highlighting both the execution (green) and training (yellow) phases. The execution block details the network architectures and the placement of the replanning step. The training block shows the MAPPO update sequence. The colored arrows differentiate data flow, specifying whether it applies to all agents, a single agent, or represents aggregated data for training. Furthermore, the environment is visualized as a grid, including the agents and targets with their provided or required skills (colored dots). The targets are marked with a green square, which can have a black border indicating a collaborative target (AND type).
The environment is modeled as a grid, with targets representing tasks that require specific skills. Robots possess different skills (e.g., a drone might have aerial observation and payload delivery, while a ground robot has sample collection and heavy lifting). The system learns to assign targets to the most appropriate robot or combinations of robots (for collaborative targets) and determine the optimal paths to complete them. The replanning step is crucial here; it allows the team to adapt to new information, like newly discovered targets, without restarting the entire planning process from scratch.
The Numbers Speak: Speed and Scale
The performance metrics are compelling, especially when comparing the learning-based MAPPO approach to Exhaustive Search (ES), which represents an optimal but computationally expensive baseline.
- Planning Speed: For solving 10 targets,
MAPPOinference time was around 0.1 seconds, whileEStook approximately 100 seconds. This is a 1000x speedup for inference. - Scalability: As the number of targets increased,
ESplanning time grew combinatorially, quickly becoming impractical.MAPPOshowed only a marginal increase in inference time, demonstrating superior scalability. - Replanning Efficiency: The system could perform online replanning for newly discovered targets without significant overhead, crucial for dynamic missions.
- Solution Quality: While
MAPPOdoesn't guarantee global optimality likeES, it consistently found near-optimal solutions, achieving comparable mission completion times in practice, especially for larger problem sizes whereESwas infeasible. - Training Time vs. Inference Time: The trade-off is clear. Training
MAPPOpolicies requires significant time (hours to days depending on complexity), but this investment yields extremely fast inference times during actual mission execution.
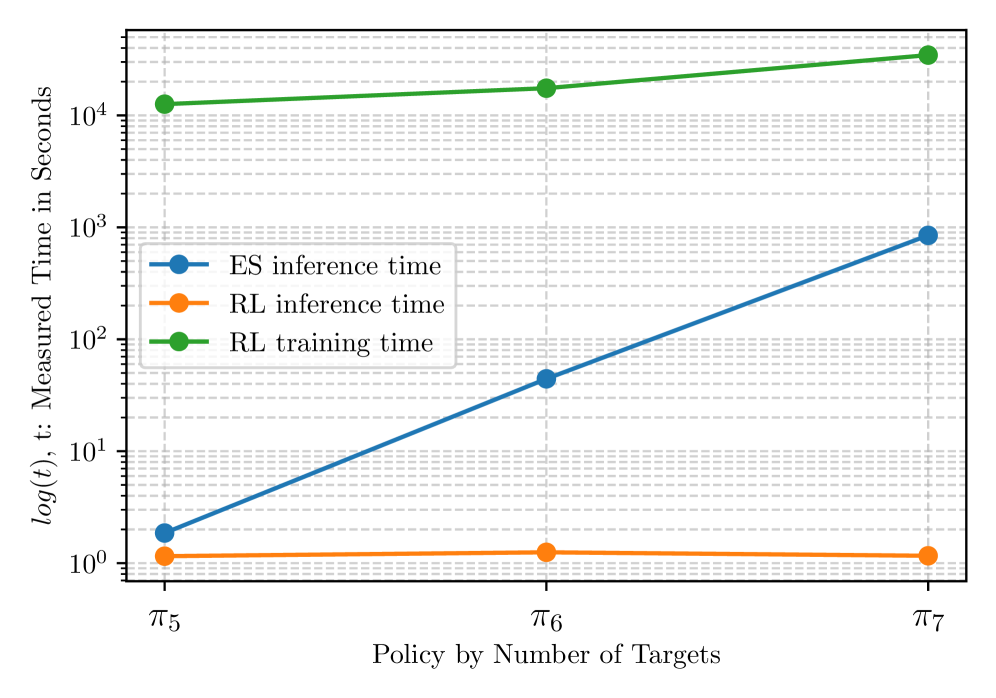 Figure 3: RL inference and training time measurements compared to the inference time of the ES approach with respect to the trained policies by number of solved targets.
Figure 3: RL inference and training time measurements compared to the inference time of the ES approach with respect to the trained policies by number of solved targets.
Impact on Your Drone Missions
This research directly addresses a major bottleneck in advanced drone operations: complex multi-agent coordination. For drone hobbyists looking to push boundaries, or engineers developing commercial solutions, this means:
- Autonomous Inspection: Drones could team up with ground robots (e.g., wheeled or tracked robots) to inspect large industrial facilities, pipelines, or infrastructure. The drone handles aerial views and hard-to-reach spots, while the ground robot conducts close-up inspections or carries heavier sensors, creating a comprehensive, multi-perspective view that's impossible for a single platform.
- Search and Rescue: A fleet of small drones could rapidly map a disaster zone, identifying points of interest, while a robust ground robot navigates debris to deliver supplies or aid, all coordinated by this AI. This integrated approach drastically cuts down response times and improves the chances of successful outcomes in critical situations.
- Environmental Monitoring: Drones could collect atmospheric data over a wide area, while ground robots sample soil or water, with the AI dynamically allocating tasks based on real-time data and environmental changes. Such coordinated efforts allow for more precise and adaptive data collection, crucial for understanding complex ecosystems or tracking pollution.
- Logistics and Delivery: Specialized drones for different payload sizes or ranges could coordinate with ground vehicles for last-mile delivery in complex urban or rural environments. This intelligent orchestration promises to optimize delivery routes, reduce congestion, and enhance efficiency across diverse logistical challenges.
- Enhanced Autonomy: This capability moves beyond simple waypoint navigation or obstacle avoidance for individual drones. It allows for truly intelligent, adaptive team behavior, unlocking missions previously deemed too complex or resource-intensive. It's a leap from individual robotic tools to a cohesive, problem-solving unit.
Reality Check: Where We Stand
While promising, the approach isn't without its caveats:
- Simulated Environment: The current work is primarily validated in a simulated grid-world environment. Translating these results to the messy, unpredictable real world with complex physics, sensor noise, and communication delays is a significant undertaking. Real-world deployment demands robust handling of environmental uncertainties and hardware imperfections that simulations often abstract away.
- Training Data Dependence: Like all learning-based methods,
MAPPO's performance heavily depends on the quality and diversity of its training data. Real-world training data for complex multi-robot interactions is scarce and expensive to generate. Developing diverse, representative datasets for real-world scenarios remains a substantial hurdle for widespread adoption. - Generalization: The policies trained are specific to the environment and task types encountered during training. Generalizing to entirely new environments, unforeseen task requirements, or significantly different robot teams might require retraining or fine-tuning. This means a system trained for planetary exploration might not seamlessly adapt to urban search and rescue without significant re-learning.
- Hardware and Communication: The paper assumes reliable communication between agents and a centralized entity during training. In reality, intermittent communication, bandwidth limitations, and onboard processing power constraints on individual robots (especially smaller drones) would need to be addressed. Maintaining robust communication links and managing computational load on resource-constrained platforms are practical challenges for real-world teams.
- Safety and Robustness: For real-world deployment, especially in critical applications, robust failure handling, collision avoidance in dynamic environments, and verifiable safety guarantees are paramount. These aspects are not the primary focus of this planning paper. Ensuring that an AI-orchestrated team can operate safely and predictably, even when things go wrong, is a non-negotiable requirement for public trust and regulatory approval.
DIY Potential for the Ambitious Builder
Replicating this exact system from scratch would be a significant undertaking for most hobbyists, requiring a strong background in reinforcement learning, Python, and robotics simulation. However, the underlying MAPPO algorithm is well-documented, and open-source implementations exist (e.g., in RLlib or various PyTorch/TensorFlow libraries).
A hobbyist could certainly experiment with simpler multi-agent planning scenarios using ROS (Robot Operating System) for inter-robot communication and a Gazebo simulation environment. The core challenge lies in defining the reward function and designing the observation space and action space for their specific robot team. While building a full heterogeneous drone-ground robot team is a large project, applying the principles of MAPPO to optimize simpler tasks for a few drones (e.g., collaborative mapping) is within reach for advanced builders. The heavy lifting of the RL training would still require substantial computational resources.
The Bigger Picture: Beyond Just Planning
Building robust multi-robot systems requires more than just smart planning; it needs sophisticated perception and dynamic environment understanding. For instance, VRUD: A Drone Dataset for Complex Vehicle-VRU Interactions within Mixed Traffic by Wang et al. addresses the critical need for real-world data. This dataset provides crucial insights into how drones interact with vehicles and vulnerable road users, which is vital for training safe navigation and interaction policies in complex, real-world scenarios.
Accurate perception, particularly in complex urban environments, is foundational for any collaborative team to safely navigate and execute its plans. Without robust perception, even the best planning algorithm is useless. Similarly, Lightweight Prompt-Guided CLIP Adaptation for Monocular Depth Estimation by Manghotay and Liang offers a practical solution for drones to gain vital depth information from a single camera. This allows drones to perceive their 3D surroundings efficiently, enabling obstacle avoidance and precise maneuvers, which are essential for executing the complex plans generated by MAPPO.
This kind of efficient, AI-powered perception is essential for drones to understand their 3D environment, avoid obstacles, and perform precise maneuvers when executing the plans generated by systems like MAPPO. For truly dynamic environments where observations might be sparse, LAtent Phase Inference from Short time sequences using SHallow REcurrent Decoders (LAPIS-SHRED) by Bao et al. presents a more theoretical, but equally relevant, method. By reconstructing complete spatio-temporal dynamics from limited observations, LAPIS-SHRED could equip a multi-agent drone team with a far more comprehensive and predictive understanding of its surroundings, allowing for more informed and adaptive collaborative planning, especially in situations with occlusions or rapidly changing conditions.
The Road Ahead
This research marks a clear step towards truly intelligent, adaptive drone and robot teams. The challenge now lies in bridging the gap from simulated efficiency to real-world robustness, enabling these AI-orchestrated fleets to operate autonomously in environments far beyond our reach.
Paper Details
Title: Collaborative Task and Path Planning for Heterogeneous Robotic Teams using Multi-Agent PPO Authors: Matthias Rubio, Julia Richter, Hendrik Kolvenbach, Marco Hutter Published: April 3, 2024 (arXiv v1) arXiv: 2604.01213 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.