Fail2Drive: Stress-Testing Drone AI for Real-World Robustness
A new benchmark, Fail2Drive, exposes critical generalization gaps in autonomous driving models within the CARLA simulator, highlighting why our drones still struggle with the unexpected.
TL;DR: Researchers have introduced
Fail2Drive, a newCARLAbenchmark specifically engineered to push autonomous driving systems past their limits. It uses unique 'paired routes' to isolate performance drops under 17 types of distribution shifts, revealing that even state-of-the-art models suffer significant degradation and fundamental reasoning failures, offering a vital tool for building more robust drone autonomy.
Beyond the Training Track: Why Simulators Lie
When we talk about autonomous drones, the conversation often circles back to robustness. Can a drone handle the unexpected? Can it perform reliably when the environment changes, when the lighting shifts, or when it encounters something it's never explicitly seen in training? This isn't just an academic question; it’s the ultimate test for real-world deployment. While simulators are invaluable for safe, scalable testing, they often fall short in truly challenging a system's ability to generalize. Most benchmarks inadvertently test memorization rather than genuine adaptability.
The Hidden Problem: Memorization, Not Mastery
Traditional benchmarks for autonomous systems often reuse scenarios seen during training or present only minor variations. This approach, while convenient, creates a critical blind spot. A model might achieve high scores, not because it understands the underlying physics or intent, but because it has effectively memorized the correct responses for those specific situations. This isn't just inefficient; it's dangerous. For autonomous drones, where every flight involves unique variables – wind gusts, unpredictable obstacles, varying lighting conditions, or even novel objects – relying on memorization is a recipe for failure. The gap between a controlled training environment and the chaos of the real world is where most systems falter.
Introducing Fail2Drive: Designed to Break, Built to Learn
Fail2Drive steps in to address this fundamental flaw. It’s not just another CARLA benchmark; it’s a meticulously engineered gauntlet designed to expose the true generalization capabilities of closed-loop autonomous driving systems. The core innovation lies in its 'paired-route' design. For every 'shifted' route, there's an 'in-distribution' counterpart. This crucial pairing allows researchers to isolate the exact impact of a specific distribution shift, transforming qualitative failures into measurable quantitative diagnostics.
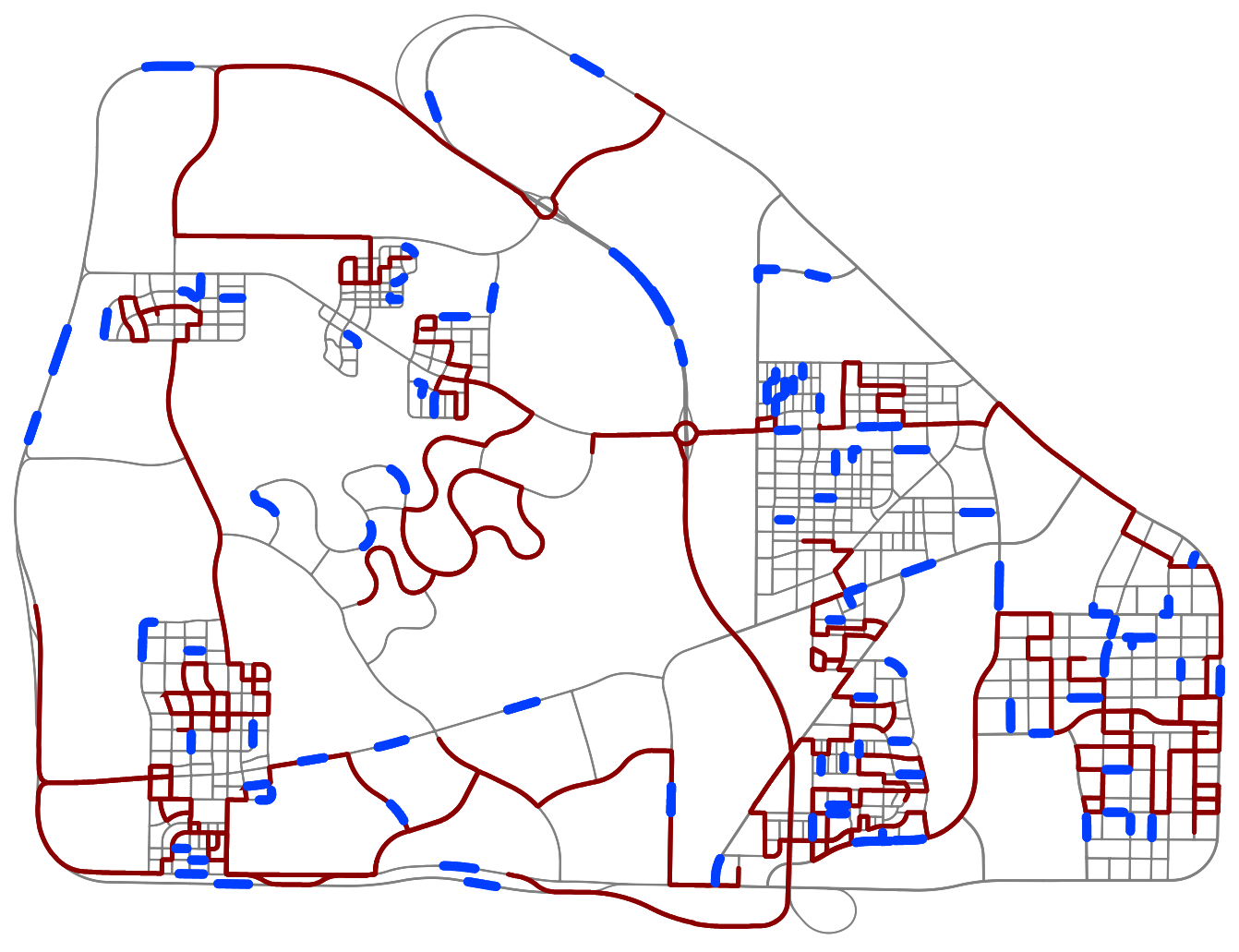
Figure 2: Fail2Drive routes (blue) are diversely spread across Town13, covering a wide range of environments, and have little overlap with the official CARLA validation routes (red).
The benchmark features 200 distinct routes, significantly expanding the test landscape beyond standard CARLA validation sets. These routes are designed to impose 17 novel scenario classes, meticulously categorized into appearance shifts (e.g., fog, rain, time of day), layout shifts (e.g., blocked roads, altered lane markings), behavioral shifts (e.g., aggressive drivers, sudden braking), and robustness shifts (e.g., sensor noise, adversarial attacks). This comprehensive approach ensures that models are tested against a broad spectrum of real-world challenges.
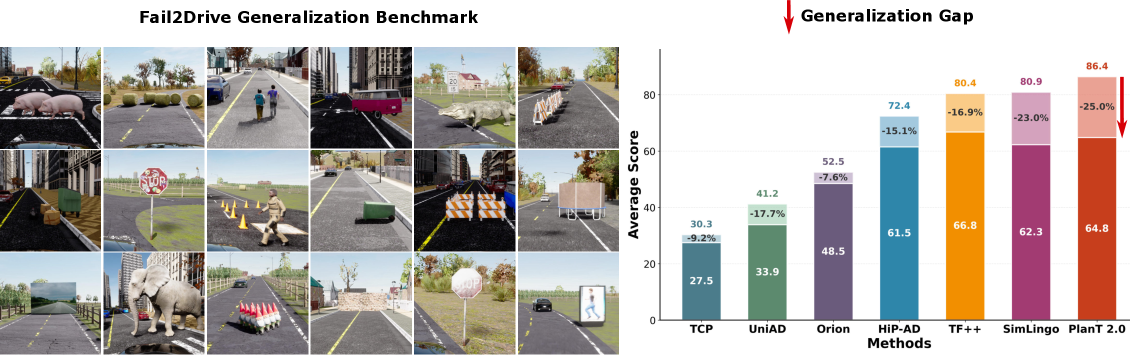
Figure 6: An overview of various scenario types encountered in the Fail2Drive benchmark, showcasing diverse environmental and situational challenges.
Figure 8: A complex urban scenario within the CARLA simulator, demonstrating the varied environments used for testing generalization in Fail2Drive.
Consider the paired-route concept: one route is standard, the other introduces a specific challenge. For example, a standard street might become partially blocked by construction, or a clear road might suddenly be obscured by dense fog. By comparing performance on these matched pairs, Fail2Drive precisely quantifies how well a system adapts to the new condition versus its baseline performance. This isn't about passing a test; it's about understanding why a system fails when faced with novelty.

Figure 9: An example of an in-distribution route from the Fail2Drive benchmark, representing a standard driving scenario.

Figure 10: The shifted counterpart to the previous route, illustrating a specific distribution change or challenge introduced in the scenario.
The benchmark also provides an open-source toolbox. This isn't just for running tests; it allows researchers and hobbyists to create their own new scenarios, validate their solvability with a privileged expert policy, and contribute to an ever-growing library of failure cases. This reproducibility and extensibility are critical for accelerating progress in robust autonomy.
The Harsh Reality: State-of-the-Art Still Stumbles
The results from evaluating multiple state-of-the-art autonomous driving models on Fail2Drive are sobering. The paper reports a consistent degradation across the board, with an average success-rate drop of 22.8%. This isn't minor; it's a significant indicator that even leading models struggle profoundly when pushed beyond their training distribution.
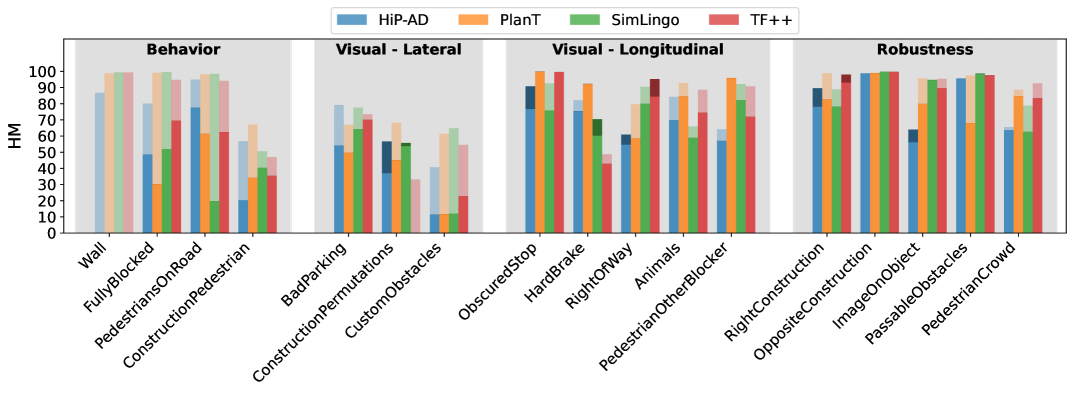
Figure 3: Harmonic mean between Driving Score and Success Rate on the four scenario categories of Fail2Drive. The transparent part displays the drop in performance, and the darker ones indicate an increase in score.
Beyond the raw numbers, the analysis uncovers unexpected and concerning failure modes. Some models, despite clear LiDAR readings, completely ignored objects in their path, predicting full-speed driving directly into collisions. This points to a failure in fundamental concepts of free and occupied space. Others exhibited bizarre behaviors, like reacting to a wall depicting a road by trying to adjust for the road in the picture rather than the actual physical wall, leading to collisions. These aren't edge cases; they reveal deep conceptual gaps in how these AI systems perceive and reason about their environment.

Figure 4: TransFuser++ correctly perceives a vehicle, but predicts full-speed driving, causing a collision.

Figure 5: SimLingo tries to avoid an obstacle by changing lanes, causing a collision (Top). SimLingo fails to recognize a picture wall and adjusts its predictions for the road depicted on the wall (Bottom).
Another telling failure mode involved unnecessary avoidance maneuvers for non-obstacles, like mailboxes or distant construction, risking collisions with other vehicles when no threat existed. This isn't just about avoiding hazards; it's about discerning relevant hazards from benign environmental clutter, a crucial skill for efficient and safe autonomous operation.
Figure 10: PlanT performs an unnecessary avoidance maneuver for a construction (left) and a mailbox that both do not block its path, risking vehicle collisions.
Figure 7: A visualization of speed prediction performance over time, showing how models react (or fail to react) to dynamic scenarios.
Flying Smarter: What This Means for Autonomous Drones
While Fail2Drive focuses on autonomous driving, its implications for mini drones are direct and profound. The challenges of generalization under distribution shifts are arguably even more acute for aerial platforms. Drones operate in highly dynamic 3D environments, often with limited onboard processing power, tighter weight constraints, and diverse camera angles. A drone navigating an industrial inspection, delivering a package in a residential area, or performing search and rescue needs to react robustly to unexpected obstacles, changing weather, varying lighting, and novel visual cues. A failure to generalize, as exposed by Fail2Drive, could mean a crashed drone, lost payload, or worse. This benchmark provides the blueprint for creating similar rigorous testing environments for drone autonomy. By systematically breaking current drone AI, we can identify weaknesses and build genuinely resilient perception and navigation systems that don't just work in the lab but thrive in the unpredictable real world.
The Uncharted Territory: Where Fail2Drive Stops Short
Fail2Drive is an excellent diagnostic tool, but it's important to acknowledge its boundaries. First, it operates entirely within the CARLA simulator. While CARLA is sophisticated, closing the "sim-to-real" gap remains a significant hurdle. Real-world sensor noise, atmospheric effects, and unpredictable dynamics are still difficult to perfectly replicate. The benchmark identifies what breaks, but doesn't prescribe how to fix it. This is the next frontier for researchers. Furthermore, Fail2Drive's scenarios are tailored for ground vehicles. Adapting these rigorous tests for aerial dynamics – managing altitude, complex wind patterns, and 360-degree obstacle avoidance – would require substantial modifications. The current framework also doesn't explicitly address hardware limitations common in mini drones, such as limited battery life impacting complex perception algorithms, or the need for ultra-low latency processing on edge devices.
Build Your Own Gauntlet: Open-Source for the Innovator
One of the most valuable contributions of Fail2Drive is its commitment to open science. All code, data, and tools are publicly available on GitHub. This means hobbyists, academic researchers, and commercial developers alike can leverage this benchmark. If you're building drone navigation systems, you can take inspiration from Fail2Drive's methodology to create your own stress tests. The open-source toolbox for scenario creation is particularly powerful, allowing you to design specific challenges relevant to your drone's intended operational environment. You'll need access to CARLA and a capable machine, but the framework itself is ready for experimentation. This democratizes the process of rigorous benchmarking, moving beyond proprietary systems and fostering collaborative development of more robust AI.
The Broader Quest: Perception, Cognition, and Robustness
Addressing the generalization failures uncovered by Fail2Drive requires a multi-pronged approach, and related research is already pushing these boundaries. For instance, the paper "Self-Improving 4D Perception via Self-Distillation" by Huang et al. offers a pathway to more capable drones by proposing a self-improving method for 4D perception. This is crucial for dynamic scenes, allowing drones to learn advanced perception without expensive manual annotations, thus making robust systems more scalable and accessible. The ability of an autonomous drone to truly 'act wisely' in novel situations, as highlighted by Fail2Drive, often depends on meta-cognitive abilities. Yan et al.'s work, "Act Wisely: Cultivating Meta-Cognitive Tool Use in Agentic Multimodal Models," explores how AI can intelligently decide between internal processing and external tools like cloud AI or specialized sensors. This intelligent resource management is key for drones operating autonomously with limited onboard resources. Finally, Fail2Drive reveals instances where models 'see' objects but fail to act correctly. This 'seeing but not thinking' problem is precisely what Xu et al. address in "Seeing but Not Thinking: Routing Distraction in Multimodal Mixture-of-Experts." Their work pinpoints critical flaws where models perceive everything but fail to reason effectively, a fundamental issue that must be resolved for truly intelligent and robust drone decision-making.
Forging Resilient Autonomy
Fail2Drive isn't just a benchmark; it's a statement: true autonomy isn't built on memorization, but on the ability to handle the unknown. By systematically exposing the weaknesses of today's AI, we gain the insights needed to engineer a new generation of autonomous drones that can truly navigate our complex world with confidence and safety.
Paper Details
Title: Fail2Drive: Benchmarking Closed-Loop Driving Generalization Authors: Simon Gerstenecker, Andreas Geiger, Katrin Renz Published: 2024-04-16 (arXiv submission date) arXiv: 2604.08535 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.