FSUNav: Brain-Inspired AI for Zero-Shot Drone Navigation
A new 'Cerebrum-Cerebellum' architecture, FSUNav, enables drones to understand high-level goals and navigate complex, unknown environments safely and efficiently without prior training.
TL;DR: This paper introduces
FSUNav, a navigation system inspired by the brain's cerebrum and cerebellum. It enables drones and other robots to understand high-level goals from various inputs and navigate complex, unknown environments safely and efficiently without prior training for specific locations.
Intelligent Autonomy Without Blueprints
Autonomous drones are everywhere, from delivery to inspection. But truly smart navigation – the kind that lets a drone understand "find the red toolbox in the garage" and then actually do it, safely, in a space it's never seen – remains a tough nut to crack. This new research, FSUNav, tackles precisely that challenge by borrowing a page from biology.
The Bottleneck of Current Navigation
Current vision-language navigation (VLN) systems for robots, including drones, often hit major walls. They typically struggle with:
- Heterogeneous robot compatibility: Most solutions are tied to specific robot types, making cross-platform deployment a headache.
- Real-time performance: Processing complex visual and linguistic data quickly enough for dynamic environments often proves difficult, leading to latency issues.
- Navigation safety: Collisions pose a constant risk, especially in unstructured spaces where unexpected obstacles appear.
- Open-vocabulary semantic generalization: They can't easily understand new, unspecified objects or goals without explicit pre-training. You want a drone to "find the widget," not "find object ID 42," right?
- Multimodal inputs: Accepting both text commands and visual cues simultaneously often remains limited.
These limitations mean deploying a drone for a novel mission in an unknown area is either impossible or requires extensive, costly pre-configuration and training. That's a significant barrier to truly versatile drone applications.
Dual-Brain Approach to Navigation
The core innovation behind FSUNav is its "Cerebrum-Cerebellum architecture," which cleverly mirrors how our own brains handle high-level planning and low-level motor control. It's a compelling design choice for complex autonomous tasks.
The Cerebrum module handles the "thinking." Think of it as a three-layer reasoning system built around a Vision-Language Model (VLM) for open-vocabulary understanding.
- The Semantic Layer takes multimodal goals (like text commands or image descriptions) and translates them into structured target profiles, effectively grounding those open-vocabulary requests. So, if you tell it "find the umbrella," it actually knows what an umbrella looks like.
- The Spatial Layer then uses these
VLM-driven semantic waypoints alongside geometric frontier exploration to figure out the best path forward. - The Rule Layer orchestrates the entire behavior, performing two-stage verification (is this really the target?) and adaptive cooldowns to prevent erratic movements. It also builds a semantic scene graph, mapping out the environment's objects and their relationships. This entire
Cerebrumstack enables true zero-shot adaptation, meaning it doesn't need prior training for specific goals or environments.
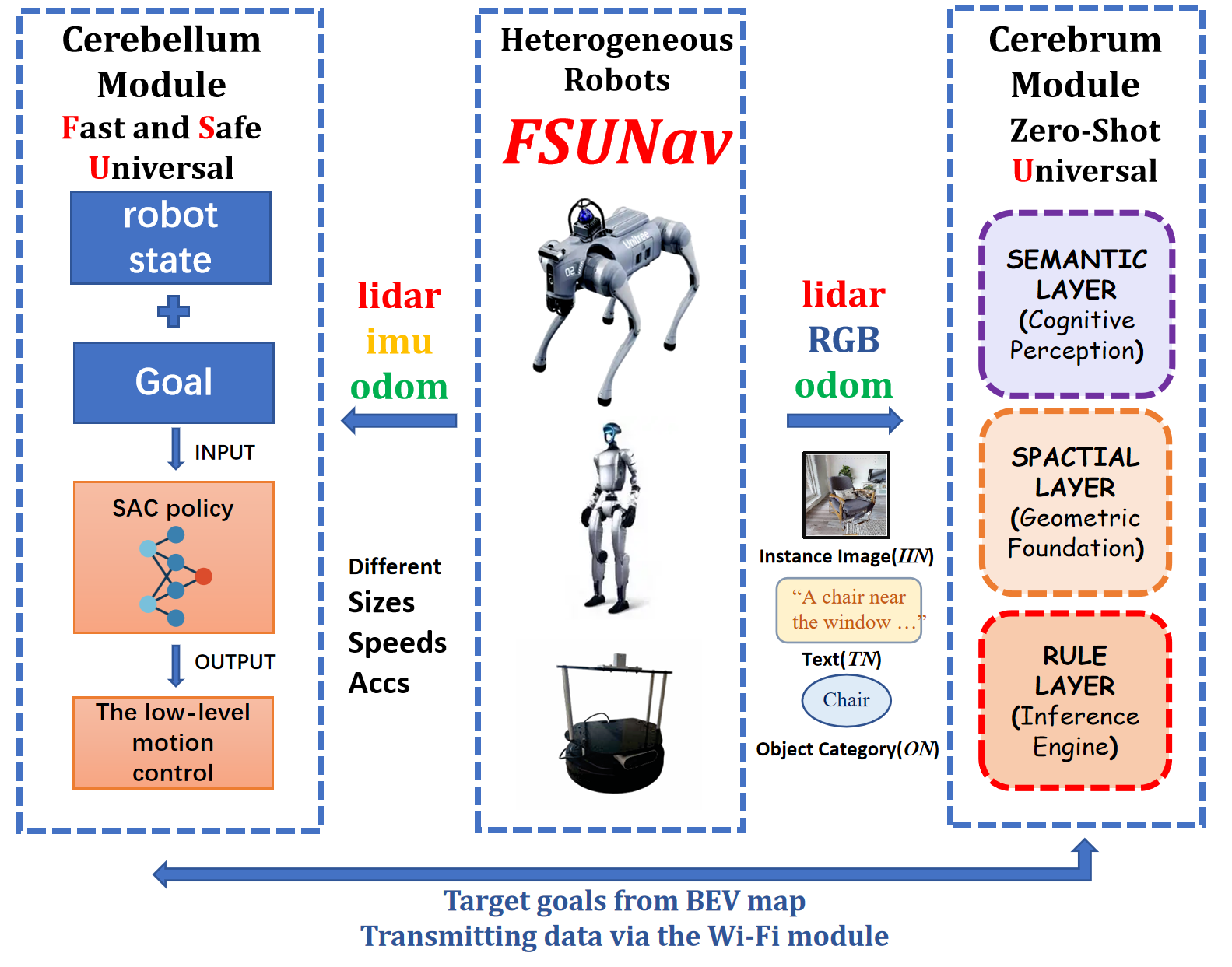 Figure 1: The overall framework of FSUNav, showing the dual-brain collaborative architecture for fast, safe, and generalizable zero-shot goal-oriented navigation.
Figure 1: The overall framework of FSUNav, showing the dual-brain collaborative architecture for fast, safe, and generalizable zero-shot goal-oriented navigation.
The Cerebellum module is the "doing" part. This high-frequency, end-to-end deep reinforcement learning (DRL) module acts as a universal local planner. It's designed to ensure unified, efficient, and safe navigation across diverse robot types—think humanoids, quadrupeds, wheeled robots, and, critically, drones. It focuses on local obstacle avoidance and precise movement, significantly reducing collision risk while maintaining speed.
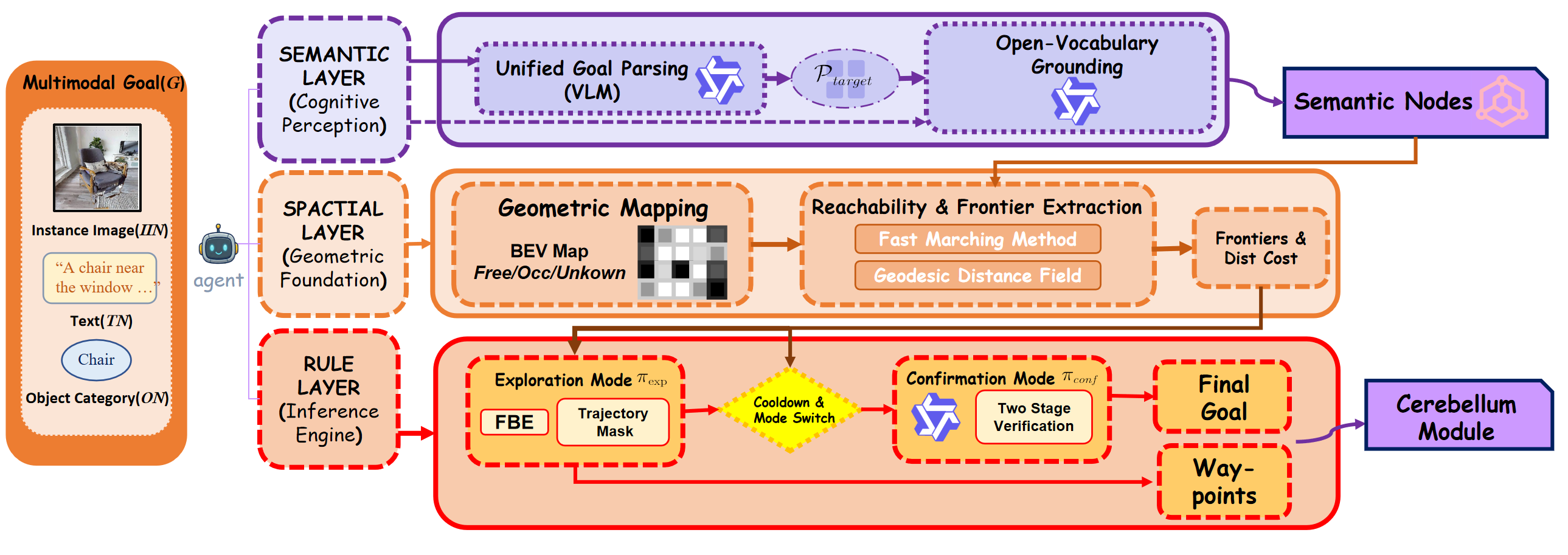 Figure 2: The overall framework of FSUNav_Cerebrum, illustrating how a unified VLM powers semantic, spatial, and rule-based reasoning layers for training-free, zero-shot goal-oriented navigation.
Figure 2: The overall framework of FSUNav_Cerebrum, illustrating how a unified VLM powers semantic, spatial, and rule-based reasoning layers for training-free, zero-shot goal-oriented navigation.
This dual architecture allows high-level semantic reasoning to guide low-level, real-time safe execution. It's a pragmatic approach to bridging the gap between abstract commands and physical robot movement.
Performance Where It Counts
FSUNav isn't just a theoretical concept; it truly performs. Tested on MP3D, HM3D, and OVON benchmarks, it achieves state-of-the-art results across object, instance image, and task navigation challenges. This isn't some marginal improvement; the paper explicitly states it "significantly outperform[s] existing methods."
Key metrics highlighted:
- State-of-the-art performance: Outperforms existing methods on multiple benchmarks for object, instance, and task navigation.
- Real-world validation: Successfully deployed and tested on a
Unitree Go2 EDUquadruped robot, a humanoidG1, and wheeled mobile robots in real-world scenarios. - Efficient mobility: The
Unitree Go2 EDUdemonstrated navigation at up to0.6 m/s. - Real-time dynamic obstacle avoidance: Proven capability in unstructured environments, crucial for safety.
- Accurate target identification: Successfully located an "umbrella" target, among others, in zero-shot scenarios.
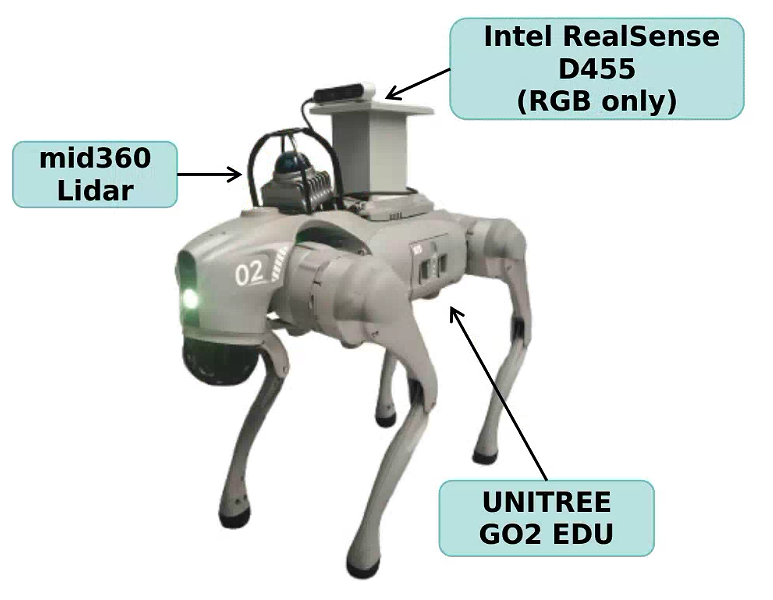 Figure 3: Our real-world experimental setup, featuring a Unitree Go2 EDU quadruped robot equipped with an Intel RealSense D455 camera for real-time RGB observations.
Figure 3: Our real-world experimental setup, featuring a Unitree Go2 EDU quadruped robot equipped with an Intel RealSense D455 camera for real-time RGB observations.
 Figure 4: The quadruped robot successfully completing an open-vocabulary object goal navigation task targeting “umbrella” at 0.6 m/s, demonstrating efficient mobility and real-time dynamic obstacle avoidance.
Figure 4: The quadruped robot successfully completing an open-vocabulary object goal navigation task targeting “umbrella” at 0.6 m/s, demonstrating efficient mobility and real-time dynamic obstacle avoidance.
Unlocking New Drone Missions
This is a big deal for autonomous drones. This architecture pushes drones closer to true, general-purpose autonomy, making them far more valuable tools for complex, unpredictable missions. Consider the implications:
- Dynamic Command Interpretation: Imagine a drone, fresh out of the box, taking commands like "Inspect the solar panels for damage," "Find the missing dog in the park," or "Locate the nearest fire extinguisher." It understands these high-level goals without needing a specific map or pre-trained model for "solar panels" or "fire extinguisher"—that's the power of zero-shot.
- Universal Environmental Adaptability: From indoor warehouses to dense forests or urban search and rescue, the "zero-shot" capability means it doesn't care if it's been there before. The system dynamically interprets its surroundings on the fly, adapting as it goes.
- Enhanced Safety and Efficiency: The
Cerebellummodule's universal local planner is key here. It ensures the drone avoids obstacles and follows an optimal path, even at speed, which is critical for maintaining flight stability and preventing costly crashes. - Multimodal Tasking: You could show it a picture of a specific component and tell it "find this," or combine voice commands with visual cues for even more intuitive control.
The Road Ahead: Limitations and Next Steps
While impressive, FSUNav isn't a magic bullet, and no research is without its boundaries. Here are a few areas where future work will likely focus:
- Computational Overhead: Vision-Language Models (
VLMs) are powerful but computationally intensive. While the paper highlights real-time performance, deploying this on smaller, power-constrained mini-drones might still require significant optimization or reliance on specialized edge AI accelerators to truly scale. - Robustness to Adversarial Conditions: The paper doesn't deeply explore performance under extreme lighting, heavy occlusion, or adverse weather. Drones often operate in these challenging conditions, and
VLM-based perception can become brittle when visual input degrades significantly. - Complex Interaction: While
FSUNavexcels at navigating to goals, its current scope focuses on reaching targets. Performing complex manipulation or interaction once at the target (e.g., picking up an object, operating a switch) would require integration with additional robotic manipulation policies, such as those explored in "Multi-View Video Diffusion Policy." - Action Representation: The "The Compression Gap" paper points out that discrete action tokenization can limit the scalability of Vision-Language-Action (
VLA) models. WhileFSUNavusesDRLfor itsCerebellum, the underlying action representation could become a bottleneck for even finer, more nuanced control as tasks become more intricate.
DIY Feasibility: A High Bar
Replicating FSUNav as a hobbyist is, frankly, a tall order. The Cerebrum module relies on state-of-the-art Vision-Language Models (VLMs), which are complex, resource-intensive, and often proprietary or require significant compute to fine-tune. The Cerebellum involves deep reinforcement learning (DRL), which is also demanding in terms of training data and computational power.
The authors did use an Intel RealSense D455 camera, which is accessible to hobbyists, but the core VLM and DRL models aren't typically open-source in a plug-and-play format. While the architectural concept is clear, implementing it from scratch would require expert-level machine learning and robotics knowledge, along with substantial hardware. However, if the authors release parts of their code or trained models, it could certainly open doors for advanced builders to experiment.
Building on Foundational Research
The advances in FSUNav are built on strong foundations, and its future relies heavily on continued progress in related fields. For example, its open-vocabulary semantic generalization directly benefits from improvements in core Vision-Language Models (VLMs). Papers like "CoME-VL: Scaling Complementary Multi-Encoder Vision-Language Learning" are pushing the boundaries of VLM architectures, and any advancements there could directly enhance FSUNav's ability to interpret nuanced commands and complex visual cues.
On the practical side, a system like FSUNav absolutely needs robust perception. "SFFNet: Synergistic Feature Fusion Network With Dual-Domain Edge Enhancement for UAV Image Object Detection" addresses the challenges of object detection in drone imagery, which is crucial for FSUNav's real-time obstacle avoidance and target identification, especially given the complexities of aerial views. Finally, as FSUNav gets drones to their destination, the next logical step is often interaction. "Multi-View Video Diffusion Policy: A 3D Spatio-Temporal-Aware Video Action Model" explores how robots can perform complex actions by understanding 3D spatial and temporal dynamics. Integrating such policies could extend a drone's utility beyond just navigation to sophisticated environmental interaction.
The Next Leap for Drone Autonomy
FSUNav pushes us closer to drones that don't just follow a flight plan but truly understand their mission and adapt to the unpredictable real world, making them indispensable for a new generation of autonomous tasks.
Paper Details
Title: FSUNav: A Cerebrum-Cerebellum Architecture for Fast, Safe, and Universal Zero-Shot Goal-Oriented Navigation Authors: Mingao Tan, Yiyang Li, Shanze Wang, Xinming Zhang, Wei Zhang Published: April 3, 2026 (on arXiv) arXiv: 2604.03139 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.