MV-VDP: Empowering Drones with 3D Vision and Action Intelligence
A new 'multi-view video diffusion policy' (MV-VDP) allows robots to understand 3D environments and predict future actions with unprecedented data efficiency, opening doors for advanced drone manipulation tasks.
Seeing Beyond 2D: The Next Leap for Drone Autonomy
TL;DR: A new AI model, MV-VDP, leverages multi-view video and diffusion techniques to give robots a deep 3D spatio-temporal understanding of their environment. This allows them to predict and execute complex actions with high accuracy, even with minimal training data, making advanced manipulation for drones a much closer reality.
For years, our mini drones have excelled at flying, capturing data, and basic navigation. But what about interacting with the world? Picking up a package, manipulating a switch, or performing delicate inspections requires more than just knowing where you are; it demands a nuanced understanding of 3D space and how actions change it. That's where a recent paper from Peiyan Li and colleagues, introducing the Multi-View Video Diffusion Policy (MV-VDP), comes in. It's a significant move towards equipping drones with the kind of sophisticated 'sight' and 'action intelligence' currently reserved for advanced robotic arms.
Why Our Drones Are Still Learning to 'Grasp' the World
Today's drone autonomy often hits a wall when it comes to complex manipulation. The core problem? Most AI policies rely on 2D visual observations from a single camera or simple stereo setups. They frequently use backbones pre-trained on static image-text pairs, which are great for identifying objects but struggle with the dynamic, three-dimensional nature of real-world interaction. This leads to several pain points:
- High Data Requirements: Training these systems to understand complex actions often demands immense datasets, which are costly and time-consuming to acquire.
- Limited 3D Understanding: Inferring precise 3D positions and orientations from 2D images is inherently challenging and prone to error, limiting precision for delicate tasks.
- Poor Environment Dynamics: Current models often lack a robust understanding of how their actions will actually change the environment over time, making them less predictable and less reliable.
These limitations mean our drones are fantastic at aerial reconnaissance but largely inept at tasks that require physical interaction, like precisely aligning a component or delicately retrieving an object. The 'compression gap' highlighted in Takuya Shiba's related work on Vision-Language-Action (VLA) models, where upgrading vision encoders doesn't always translate to better manipulation, underscores these fundamental challenges.
How Multi-View AI Unlocks 3D Awareness
MV-VDP tackles these issues head-on by building a policy that inherently understands the 3D spatio-temporal state of the environment. Instead of piecing together 3D from single 2D views, it processes multi-view images simultaneously. Here's the breakdown:
-
3D-Aware Input: The system takes point clouds and the robot's current pose, projecting them into multiple, spatially-aware RGB images and
heatmaprepresentations. These heatmaps essentially highlight where the robot's end-effector (or a drone's manipulator) is and where it's predicted to go. -
Video Diffusion for Prediction: At its core, MV-VDP uses a
video diffusion model. Unlike traditional vision-language backbones, this model is designed to predict future multi-view RGB videos and heatmap videos. This is a crucial distinction: it's not just saying what to do, but how the environment will evolve in response to those actions.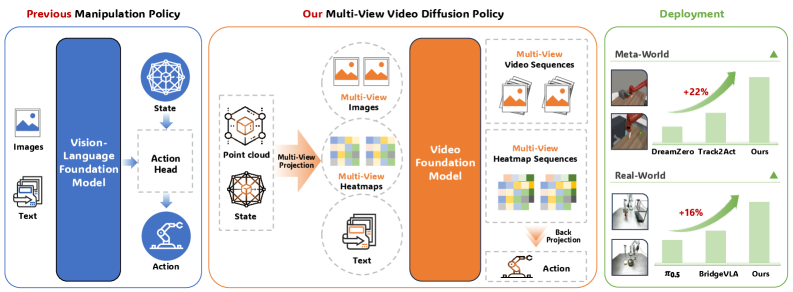 Figure 1: MV-VDP processes 3D-aware multi-view images, represents actions as multi-view heatmaps, and leverages a video foundation model to jointly predict future RGB and heatmap sequences, leading to state-of-the-art manipulation performance.
Figure 1: MV-VDP processes 3D-aware multi-view images, represents actions as multi-view heatmaps, and leverages a video foundation model to jointly predict future RGB and heatmap sequences, leading to state-of-the-art manipulation performance. -
Aligned Representation: By predicting heatmaps, the action space of the robot is directly aligned with the visual representation used in video pretraining. This significantly reduces the
data requirementsfor fine-tuning, as the model's core understanding is already geared towards dynamic, interactive scenes. -
Action Decoding: The predicted heatmaps are then back-projected to recover precise 3D end-effector positions. A lightweight decoder handles rotation and gripper states, forming full action chunks. The system essentially 'imagines' the future in 3D and then executes the steps to get there.
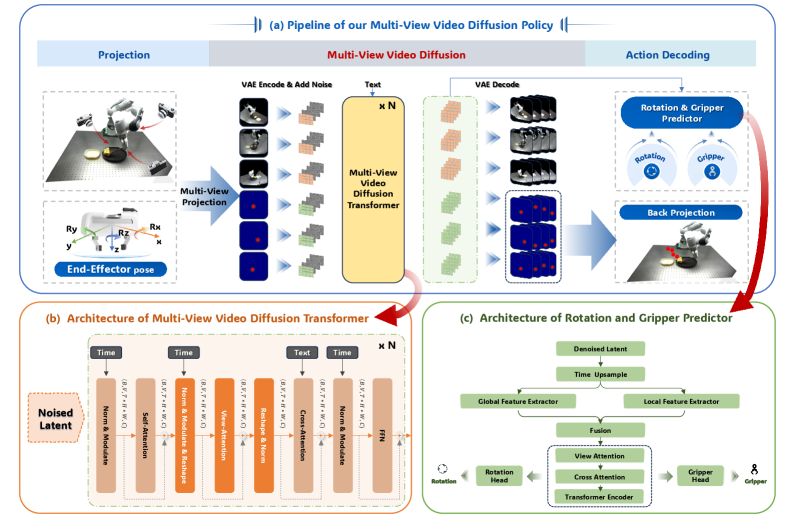 Figure 2: MV-VDP's pipeline involves projecting point clouds and robot pose into multi-view RGB and heatmaps, which are then used by a video diffusion model to predict future videos. Predicted heatmaps are back-projected for 3D end-effector positions, and an action decoder handles rotation and gripper states.
Figure 2: MV-VDP's pipeline involves projecting point clouds and robot pose into multi-view RGB and heatmaps, which are then used by a video diffusion model to predict future videos. Predicted heatmaps are back-projected for 3D end-effector positions, and an action decoder handles rotation and gripper states.
This approach means the AI policy is not just reacting; it's proactively modeling the environment's response to its intended actions, a powerful capability for complex tasks.
Demonstrating Real-World Dexterity
The findings are compelling. MV-VDP was tested on both the Meta-World benchmark and real-world robotic manipulation tasks using a Franka Research 3 robot equipped with three ZED2i cameras (Figure 3).
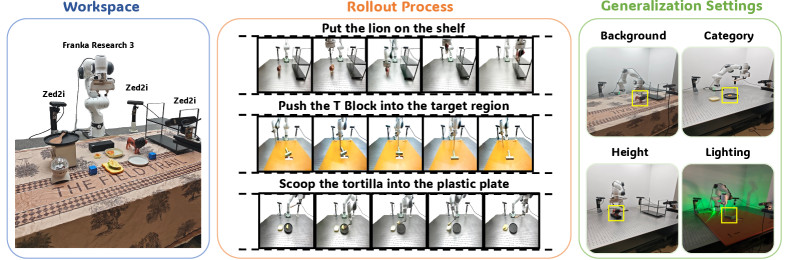 Figure 3: Real-world experimental setup and tasks. MV-VDP was evaluated on three manipulation tasks using a Franka Research 3 robot with three ZED2i cameras, including generalization assessments under various environmental conditions.
Figure 3: Real-world experimental setup and tasks. MV-VDP was evaluated on three manipulation tasks using a Franka Research 3 robot with three ZED2i cameras, including generalization assessments under various environmental conditions.
Key performance metrics include:
-
Data Efficiency: Achieved
state-of-the-artresults with only ten demonstration trajectories for complex real-world tasks. This is a massive reduction in training data compared to many prior approaches. -
Robustness: Showed
strong robustnessto varyingdiffusion stepsduring inference, maintaining high success rates even with minimal denoising (Figure 4 in the paper). -
Generalization: Demonstrated
strong robustnessacross out-of-distribution settings, including variations in background, object height, lighting, and object category. -
Superior Performance: Consistently
outperformed video-prediction-based, 3D-based, and vision-language-action modelson both Meta-World and real-world benchmarks. -
Realistic Predictions: Predicted
visually realistic RGB sequencesandheatmap sequencesthat closely matched ground truth, indicating strong internal consistency (as visually demonstrated in Figures 5 and 6). Figure 5: Visualization of predicted RGB and heatmap sequences for the Button-Press-Top task, showing visually realistic predictions and strong consistency between heatmap peaks and end-effector positions.
Figure 5: Visualization of predicted RGB and heatmap sequences for the Button-Press-Top task, showing visually realistic predictions and strong consistency between heatmap peaks and end-effector positions. Figure 6: Visualization of predicted RGB and heatmap sequences for the Door-Open task, demonstrating accurate future state prediction and end-effector tracking.
Figure 6: Visualization of predicted RGB and heatmap sequences for the Door-Open task, demonstrating accurate future state prediction and end-effector tracking.
Why This Matters for Drones Beyond Simple Flight
This research marks a significant turning point for advanced drone applications. If a drone can jointly model the 3D spatio-temporal state and predict how the environment will respond to its actions, it unlocks a new realm of capabilities:
- Precision Agriculture: Imagine a drone not just spraying, but delicately pruning individual branches or harvesting ripe fruit by predicting the required force and movement.
- Industrial Inspection & Maintenance: Drones could manipulate controls, flip switches, or perform minor repairs on infrastructure, rather than just visually inspecting it. This moves them from passive sensors to active agents.
- Search and Rescue: A drone could open a jammed door or clear debris in a dangerous environment, understanding the physics of interaction.
- Construction & Logistics: Precision placement of small components or handling packages in dynamic environments becomes feasible.
The ability to learn complex tasks from ten demonstration trajectories is especially critical for drones, where collecting vast amounts of specific interaction data in the air is often impractical or dangerous. This data efficiency makes real-world deployment much more viable.
The Hurdles Still Standing
While promising, MV-VDP isn't a magic bullet for every drone challenge:
- Robotic Arm vs. Drone: The experiments were conducted on a stationary
Franka Research 3 robot. Transferring this technology to a flying drone introduces significant challenges related to maintaining stable flight while manipulating, managing power draw for computation, and dealing with dynamic air currents. - Hardware Overhead: The setup used
three ZED2i camerasfor multi-view input, plus potentially aLiDARfor point clouds. This adds considerable weight, power consumption, and processing requirements, which are critical constraints for drones. - Computational Intensity: Diffusion models, while powerful, are generally more computationally intensive at inference than simpler policy networks. Deploying this on a drone's onboard edge AI processor would require significant optimization or specialized hardware.
- Authors' Acknowledged Limitations: The paper primarily focuses on manipulation tasks with a fixed base, not on mobile manipulation where the entire platform is moving and interacting. Integrating navigation and high-level mission planning with this precise manipulation policy is the next complex step.
DIY Feasibility: Not Yet for the Garage
For the average drone hobbyist or even a small builder, replicating MV-VDP from scratch is currently a tall order. The core of the system relies on a sophisticated video diffusion model, likely built upon large pre-trained video foundation models. Training or even fine-tuning such a model requires substantial computational resources (GPUs, specialized software libraries). The multi-view camera setup and the need for accurate point cloud data also add complexity.
While the concept is exciting, this is very much still in the realm of academic and industrial research labs. If the authors release open-source code, that could lower the barrier to experimentation, but the hardware and computational demands would remain significant. Papers like "CoME-VL: Scaling Complementary Multi-Encoder Vision-Language Learning" highlight the complexity of the foundational vision models that MV-VDP leverages, indicating that these are not trivial to implement.
Looking Ahead: Smarter Drones, Smarter Interactions
MV-VDP represents a substantial step forward in teaching robots to truly 'see' and 'act' in 3D. By enabling more data-efficient learning and robust performance in complex manipulation tasks, it sets the stage for a new generation of drones that are not just aerial observers, but active participants in our physical world. The precision object detection capabilities discussed in papers like "SFFNet: Synergistic Feature Fusion Network With Dual-Domain Edge Enhancement for UAV Image Object Detection" would be a perfect complement, providing the high-quality visual inputs needed for MV-VDP to shine in real-world drone scenarios. The question now isn't if drones will perform complex tasks, but when they'll seamlessly integrate this level of intelligence into every flight.
Paper Details
Title: Multi-View Video Diffusion Policy: A 3D Spatio-Temporal-Aware Video Action Model Authors: Peiyan Li, Yixiang Chen, Yuan Xu, Jiabing Yang, Xiangnan Wu, Jun Guo, Nan Sun, Long Qian, Xinghang Li, Xin Xiao, Jing Liu, Nianfeng Liu, Tao Kong, Yan Huang, Liang Wang, Tieniu Tan Published: 2024-04-03 (arXiv v1) arXiv: 2604.03181 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.