Omni123: Building 3D Worlds from Text—What It Means for Drones
A new '3D-native foundation model' called Omni123 unifies text-to-2D and text-to-3D generation. It leverages abundant 2D data as a geometric prior, creating high-fidelity 3D models directly from text, with significant implications for autonomous drone operations.
TL;DR: Omni123 is a new AI model that generates 3D objects and scenes directly from text, learning from a mix of 2D and limited 3D data. This native 3D approach promises to give drones the ability to not just see, but actively create and deeply comprehend their complex environments, moving beyond simple image-to-3D reconstruction.
The Drone's New Eye: From Perception to Creation
This isn't just another incremental step in AI; it's a foundational shift in how machines could perceive and interact with the physical world, especially for autonomous systems like drones. Researchers at Tongji University and MIT have unveiled Omni123, a model that generates complex 3D scenes and objects from simple text prompts, unifying 2D and 3D generation within a single autoregressive framework. For drone operators, builders, and engineers, this isn't abstract research—it's a direct line to more intelligent, capable, and autonomous aerial vehicles.
Escaping the 2D-to-3D Trap
Current methods for creating 3D models from text often involve a cumbersome two-stage process: first generating a 2D image from text, then lifting that image into 3D. This "2D-then-3D" pipeline sacrifices geometric consistency and introduces artifacts. It's like trying to sculpt a statue by painting a picture and then guessing its depth. This indirect approach is computationally intensive, slow, and produces less accurate 3D representations, which is a critical problem for drones needing precise environmental understanding. Acquiring high-quality 3D data is expensive and time-consuming, leading to a scarcity that bottlenecks the development of truly 3D-native AI models. We're stuck with models that see the world through 2D lenses, then try to infer the third dimension, leading to costly errors and inefficient operation for drones that rely on accurate 3D perception for navigation, inspection, and interaction.
 Figure 1: Traditional text-to-3D pipelines (left) often involve an intermediate 2D image, leading to a loss of geometric consistency compared to Omni123's native 3D generation (right).
Figure 1: Traditional text-to-3D pipelines (left) often involve an intermediate 2D image, leading to a loss of geometric consistency compared to Omni123's native 3D generation (right).
Building Worlds, One Token at a Time
Omni123 tackles the 3D data scarcity by learning from both abundant 2D images and limited 3D data. The core insight is that cross-modal consistency—how well images and 3D shapes align—can implicitly constrain the 3D generation process. Instead of treating 2D and 3D as separate problems, Omni123 represents text, images, and 3D shapes as discrete tokens in a shared sequence space. This allows the model to leverage the vast geometric priors available in 2D data to improve its 3D representations.
The architecture employs an "interleaved X-to-X training paradigm." This means it's not just trained on text-to-3D, but also text-to-image, image-to-3D, and even 3D-to-image. By traversing "semantic-visual-geometric cycles" (e.g., text to image to 3D to image), the model enforces semantic alignment, appearance fidelity, and multi-view geometric consistency simultaneously. This clever strategy allows it to coordinate diverse cross-modal tasks without needing perfectly aligned text-image-3D datasets, which are rare.
![Figure 3: Overview of the Omni123 architecture. Text is encoded by dual text encoders (CLIP [60] and Qwen3-0.6B [87]) and fed into a conditioning stream, while images and 3D shapes are tokenized into 1D discrete tokens and concatenated into a unified generation stream. The unified autoregressive transformer backbone uses 24 dual-stream blocks to jointly process the conditioning and generation tokens under causal attention, followed by 6 single-stream layers operating only on generation tokens, and finally with modality-specific linear heads decoding token logits over the 2D and 3D codebooks.](https://qawnehlcoileybzacnvr.supabase.co/storage/v1/object/public/article-covers/figures/omni123-building-3d-worlds-from-text-what-it-means-for-drones-mniusqgt/fig-2.png) Figure 3: The Omni123 architecture unifies text, 2D images, and 3D shapes into a single token stream, processed by a transformer backbone for joint generation.
Figure 3: The Omni123 architecture unifies text, 2D images, and 3D shapes into a single token stream, processed by a transformer backbone for joint generation.
A key component is its two-stage image tokenizer. First, a continuous VAE (Variational Autoencoder) called DINO-Tok learns high-fidelity visual representations. Then, a 1D Q-Former is trained to reconstruct these continuous features, converting them into compact 1D discrete tokens. This approach yields superior image reconstruction quality, even for complex scenes and human details, which is critical for learning accurate geometric priors.
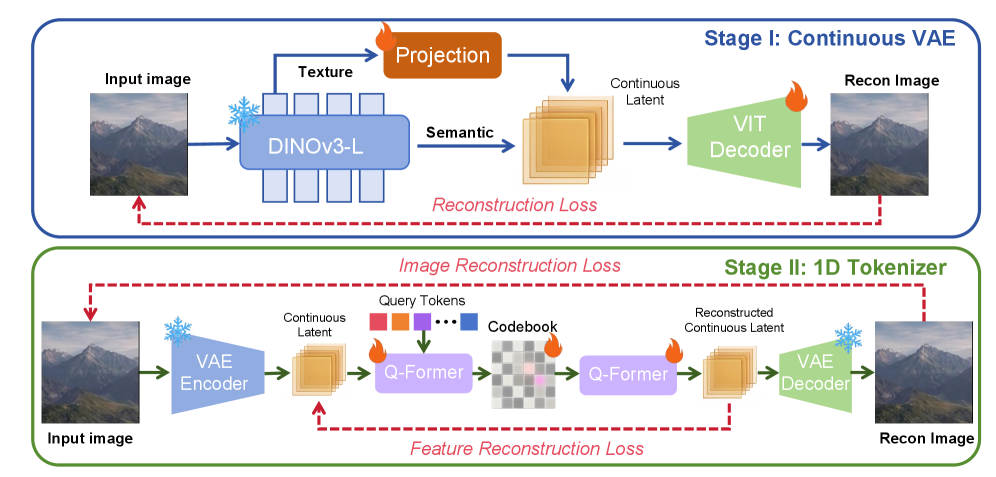 Figure 4: Omni123's two-stage image tokenizer efficiently converts high-fidelity visual data into compact, discrete tokens for the main transformer model.
Figure 4: Omni123's two-stage image tokenizer efficiently converts high-fidelity visual data into compact, discrete tokens for the main transformer model.
The model also incorporates view-conditioned generation using learnable view tokens. These tokens, corresponding to canonical viewpoints (front, back, left, right, top, bottom), are prepended to image tokens. This enables viewpoint-controllable generation and helps the model understand explicit source-target viewpoint correspondence for novel view synthesis, a key capability for robust 3D understanding.
Tangible Performance Gains
Omni123 marks a significant leap in text-guided 3D generation and editing. Its key achievements include:
- Native Joint 2D and 3D Generation: Unlike most methods, Omni123 generates both a high-fidelity 2D image and a corresponding 3D mesh simultaneously from a single text prompt. This ensures strong semantic alignment and geometric fidelity between the generated image and its 3D counterpart.
- Improved 3D Quality: Qualitative comparisons in the paper show Omni123 outperforming existing two-stage (Text→Image→3D) methods and native text-to-3D baselines in generating coherent and detailed 3D shapes from compositional prompts. For instance, generating "a teddy bear wearing a kimono" or "a deer riding a skateboard" yields more accurate and geometrically consistent results.
- Native 3D Editing: The model can directly edit existing 3D models using sequential text instructions, such as adding accessories or changing poses, without requiring re-optimization or separate 2D manipulations.
- Superior Image Tokenization: The custom two-stage image tokenizer shows better reconstruction quality on various web images, capturing object-centric details, scene-level information, human features, and even text rendering more accurately than other discrete image tokenizers. This foundational improvement directly contributes to the model's ability to learn robust 3D priors from 2D data.
- Scalable Path: The unified autoregressive framework and interleaved training paradigm suggest a scalable path toward building more comprehensive multimodal 3D world models, potentially handling increasingly complex environments and interaction types.
 Figure 2: Omni123's capabilities include generating both 2D images and precise 3D normal maps from text, and performing iterative 3D model editing directly from text prompts.
Figure 2: Omni123's capabilities include generating both 2D images and precise 3D normal maps from text, and performing iterative 3D model editing directly from text prompts.
Drones as Digital Architects
Here's where Omni123 gets interesting for drone applications. This model empowers drones to move beyond mere perception to active creation and deep environmental understanding.
- Autonomous Mission Planning and Simulation: Drones could generate detailed 3D digital twins of complex environments on the fly, or pre-mission, directly from text descriptions or even partial 2D scans. Generating a high-fidelity 3D model of a disaster site or an industrial facility before deployment allows for precise path planning and risk assessment in a dynamic virtual space. This could transform search and rescue, infrastructure inspection, and precision agriculture.
- Real-time Environment Reconstruction and Augmentation: Drones equipped with Omni123-like capabilities could reconstruct complex 3D environments in real-time, filling in gaps from sensor data or even generating hypothetical structures based on mission parameters. For instance, a drone inspecting a building could generate a complete 3D model, then use text prompts to "add a missing pipe" or "simulate a collapsed section," aiding human operators in decision-making.
- Enhanced Human-Drone Interaction: Natural language commands could directly influence 3D environment generation or modification. A human operator could simply say, "build a temporary landing pad here," and the drone's AI could generate a feasible 3D model of the pad within the current environment, understanding its spatial constraints. This moves beyond simple waypoint navigation to semantic understanding and interaction with the 3D world.
- Digital Twin Creation and Maintenance: For industrial applications, drones could rapidly create and update highly accurate digital twins of assets and facilities. Instead of laboriously scanning and processing, a drone could identify a component, then generate its 3D model from a textual description, ensuring consistency and detail. This also connects to anomaly detection, where
Modulate-and-Mapcould then be used to find discrepancies in these generated or updated digital twins. - Adaptive Autonomy: If a drone encounters an unexpected obstacle or needs to create a temporary structure for a task (e.g., a small ramp for a ground robot), it could potentially generate a feasible 3D solution based on current environmental data and mission objectives.
The Road Ahead: Challenges for Real-World Deployment
While Omni123 is a major step forward, it faces some current limitations and areas for future development:
- Computational Overhead: Running a foundation model of this complexity in real-time on a resource-constrained drone presents a substantial challenge. The model, with its 24 dual-stream blocks and 6 single-stream layers, likely demands significant computational power, memory, and energy, making direct on-board deployment difficult without considerable optimization or specialized edge AI hardware.
- Real-world Dynamic Scenes: The research focuses on generating and editing individual objects or relatively static scenes. Dynamic, highly interactive, and unpredictable real-world drone environments (e.g., dense foliage, fast-moving objects, adverse weather) present a far greater challenge for real-time 3D generation and understanding.
- Scaling to 'World' Models: While the paper mentions a path to multimodal 3D world models, the current scope is still primarily object and scene generation/editing. Building truly comprehensive, dynamic 3D world models that can be continuously updated and interacted with by an agent remains a significant challenge.
- Data Bias: Although it leverages abundant 2D data, biases inherent in these datasets could propagate into the generated 3D models, potentially leading to inaccuracies or misrepresentations in certain scenarios or for less common objects.
- Precision and Fidelity Trade-offs: The generated 3D models, while geometrically consistent, might not always meet the stringent precision requirements for highly sensitive industrial inspections or manufacturing applications without further refinement.
- Ethical Considerations: The ability to generate realistic 3D environments from text also opens up questions about misinformation and the creation of synthetic realities, requiring careful consideration as the technology matures.
 Figure 6: Omni123 (bottom row) demonstrates superior qualitative results in generating both 2D images and coherent 3D meshes from complex text prompts, compared to traditional two-stage and native 3D baselines.
Figure 6: Omni123 (bottom row) demonstrates superior qualitative results in generating both 2D images and coherent 3D meshes from complex text prompts, compared to traditional two-stage and native 3D baselines.
DIY Feasibility: High-End Research vs. Practical Application
Replicating Omni123 from scratch, including training the foundation model, is currently beyond the scope of most hobbyists or even small research groups due to the sheer computational resources required. Training involves substantial GPU clusters and vast datasets. The authors used dual text encoders (CLIP and Qwen3-0.6B) and a sophisticated transformer backbone, indicating a significant architecture.
However, if pre-trained models or APIs based on Omni123 are released, hobbyists and drone developers could leverage them. A drone running a lighter version of this model on an NVIDIA Jetson or Qualcomm Snapdragon platform could generate simple 3D assets or understand complex instructions in a localized environment. The open-source nature of the underlying components (like parts of the transformer architecture or tokenization techniques) means that ideas and approaches can be adopted and adapted, even if the full system isn't directly reproducible. The ability to fine-tune such a model with custom datasets could eventually open doors for specialized drone applications, but that depends on access to the base model.
Expanding the 3D Ecosystem
The challenge of 3D data scarcity and the push towards more intuitive human-AI interaction is a broad field. Omni123’s advancement in generating and understanding 3D environments sets the stage for how autonomous agents, including drones, can operate.
This enhanced capability in 3D generation means drones generate or perceive more intricate 3D worlds. Detecting anomalies within these complex, generated, or real 3D spaces becomes paramount. This is where papers like "Modulate-and-Map: Crossmodal Feature Mapping with Cross-View Modulation for 3D Anomaly Detection" by Costanzino et al. become highly relevant. If a drone can generate a digital twin of an inspection target, Modulate-and-Map could then be used to identify subtle defects or deviations in that generated (or real-time perceived) 3D structure, offering a powerful combination for automated inspection missions.
Furthermore, as drones gain the ability to process and generate rich 3D information, their next challenge is to move beyond simple object identification to understanding complex situations. The work by He et al., "Beyond Referring Expressions: Scenario Comprehension Visual Grounding," provides a crucial framework for drones to comprehend intricate 'scenarios' from visual input. Omni123 helps the drone 'see' and 'create' the 3D world; this related work helps it 'understand' the unfolding events within that world, vital for truly autonomous and intelligent decision-making in dynamic environments.
Finally, operating in and interacting with such complex 3D environments over long missions demands sophisticated memory management for autonomous drones. Generating and processing vast amounts of 3D data can quickly lead to memory overload. "Novel Memory Forgetting Techniques for Autonomous AI Agents: Balancing Relevance and Efficiency" by Fofadiya and Tiwari directly addresses this. As drones navigate and interact with these rich 3D worlds, preventing 'false memories' and efficiently managing accumulated data will be critical for maintaining coherent reasoning and efficient operation, ensuring they stay effective during extended autonomous tasks.
The Future of Drone Intelligence
Omni123 isn't just about pretty pictures or novel 3D models; it's about fundamentally changing how autonomous systems like drones perceive, interact with, and even proactively shape their operational environments. This native 3D understanding moves us closer to drones that don't just follow commands but truly comprehend and create their world.
Paper Details
Title: Omni123: Exploring 3D Native Foundation Models with Limited 3D Data by Unifying Text to 2D and 3D Generation Authors: Chongjie Ye, Cheng Cao, Chuanyu Pan, Yiming Hao, Yihao Zhi, Yuanming Hu, Xiaoguang Han Published: April 4, 2026 (arXiv) arXiv: 2604.02289 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.