Orchestrating Diverse Drone Teams for Complex Missions with AI
Researchers are leveraging Multi-Agent Proximal Policy Optimization (MAPPO) to coordinate diverse robotic teams, drastically accelerating planning for complex exploration tasks. This brings real-time mission planning for specialized drone fleets closer to reality.
TL;DR: Researchers show how Multi-Agent Reinforcement Learning (specifically MAPPO) can efficiently coordinate diverse teams of robots—drones, rovers, and legged bots—for complex tasks like planetary exploration. This approach offers online replanning and scales far better than classical planning, cutting inference time from minutes to milliseconds.
The Symphony of Silicon and Steel
For anyone building or operating drones, a single drone performing a complex mission is already a challenge. Consider a fleet: not just identical drones, but a mix of aerial, ground, and even legged robots, each with specialized sensors and capabilities, working together seamlessly. This isn't just sci-fi; it's the tangible future of autonomous systems, and this research tackles a major hurdle: enabling these diverse teams to collaborate intelligently in real-time. Whether inspecting a vast industrial complex or charting unknown extraterrestrial terrain, coordinating these specialized robotic teams is paramount.
Why Current Approaches Struggle
Traditional approaches to multi-robot coordination, often relying on classical planning algorithms, struggle when problem complexity grows. The issue is combinatorial explosions: the number of possible ways to assign tasks to robots and plot their paths grows astronomically with more robots and more objectives. This isn't merely an inconvenience; it results in impractically long planning cycles and high computational costs. For dynamic, real-world missions where conditions change rapidly—like a drone discovering a new point of interest or a rover encountering an unexpected obstacle—these delays are unacceptable. Existing methods simply can't keep pace with the demand for online replanning, forcing operators to accept either simplified missions or lengthy downtime.
How AI Teaches Robots to Team Up
Researchers propose a collaborative planning strategy built on Multi-Agent Proximal Policy Optimization (MAPPO), a reinforcement learning (RL) technique. The core idea shifts the computational burden from runtime to training time. Instead of calculating every possible permutation during a mission, the robots learn optimal collaboration strategies beforehand through simulated experience.
Here’s how it breaks down:
- Heterogeneous Teams: The system handles robots with different skills (e.g., a drone for aerial reconnaissance, a rover for ground sampling). Tasks require specific skills, and some tasks even demand collaboration (AND-type targets requiring multiple robots). This is crucial for maximizing efficiency and scientific return.
- Centralized Training, Decentralized Execution: During training, a central learner observes the entire environment and the actions of all agents, learning a global optimal policy. However, during mission execution, each robot acts autonomously based on its own local observations and the policy it learned. This is key for robustness and scalability in real-world scenarios where constant central communication might be unreliable.
- State Representation: Each agent receives a local observation (its own position, velocity, nearby targets) and a global state (positions of all agents and targets, mission progress). This hybrid approach balances detailed local awareness with a broader understanding of the mission.
- Online Replanning: Crucially, the system isn't rigid. When new tasks appear or conditions change (simulated as new targets popping up during a planetary exploration scenario), the team can replan on the fly. This adaptive capability is where RL truly shines over static classical methods.
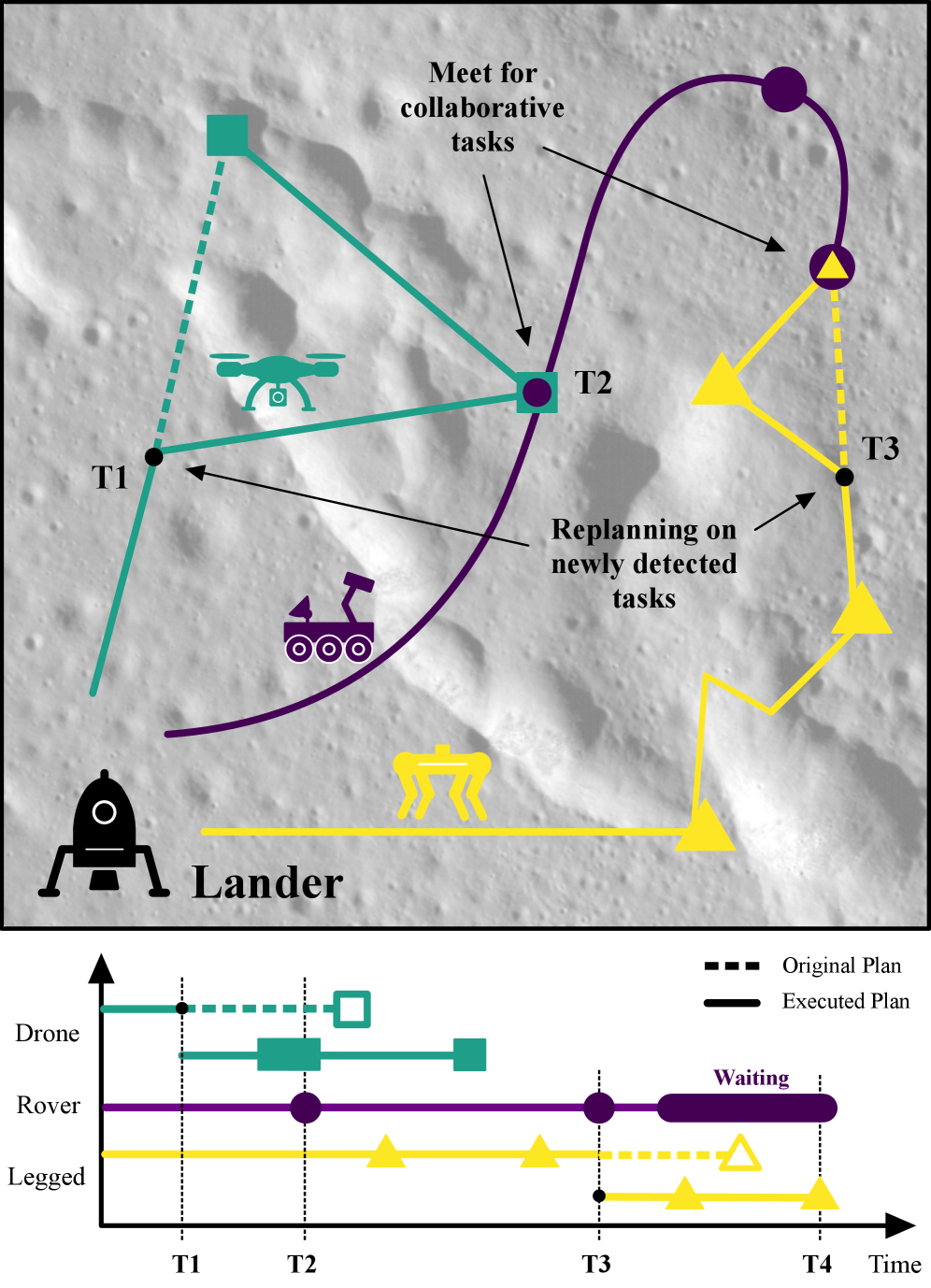 Figure 1: An illustrative plan for a collaborative robot fleet with different specializations, such as flying, walking, or driving. During the mission the drone and the legged robot find new tasks and replan to minimize mission time.
Figure 1: An illustrative plan for a collaborative robot fleet with different specializations, such as flying, walking, or driving. During the mission the drone and the legged robot find new tasks and replan to minimize mission time.
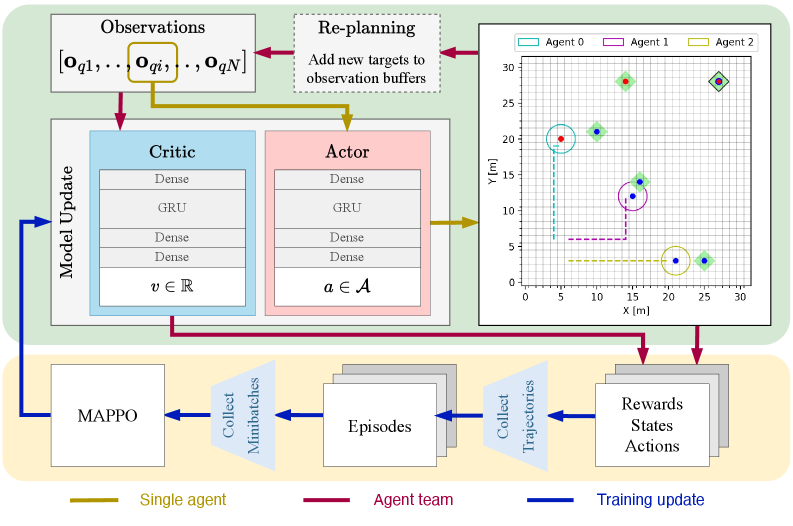 Figure 2: This figure illustrates the complete workflow, highlighting both the execution (green) and training (yellow) phases. The execution block details the network architectures and the placement of the replanning step. The training block shows the MAPPO update sequence. The colored arrows differentiate data flow, specifying whether it applies to all agents, a single agent, or represents aggregated data for training. Furthermore, the environment is visualized as a grid, including the agents and targets with their provided or required skills (colored dots). The targets are marked with a green square, which can have a black border indicating a collaborative target (AND type).
Figure 2: This figure illustrates the complete workflow, highlighting both the execution (green) and training (yellow) phases. The execution block details the network architectures and the placement of the replanning step. The training block shows the MAPPO update sequence. The colored arrows differentiate data flow, specifying whether it applies to all agents, a single agent, or represents aggregated data for training. Furthermore, the environment is visualized as a grid, including the agents and targets with their provided or required skills (colored dots). The targets are marked with a green square, which can have a black border indicating a collaborative target (AND type).
Hard Numbers: Speed and Scalability
The true advantage here is efficiency. The researchers benchmarked their MAPPO approach against single-objective optimal solutions derived from exhaustive search (ES). The results are striking:
- Orders of Magnitude Faster: For a scenario with 10 targets, the exhaustive search took around 1000 seconds (over 16 minutes) to plan. MAPPO, after training, completed the inference (planning) in less than 10 milliseconds. This is a dramatic difference, making online replanning feasible.
- Scalability: As the number of solved targets increased, the performance gap widened even further. The ES approach's planning time skyrocketed, while the RL inference time remained relatively flat and consistently low.
- Solution Quality: While not always perfectly optimal like ES (which is computationally impractical for complex scenarios), the RL agent found solutions that were consistently close to optimal, typically within 5-10% of the best possible mission time.
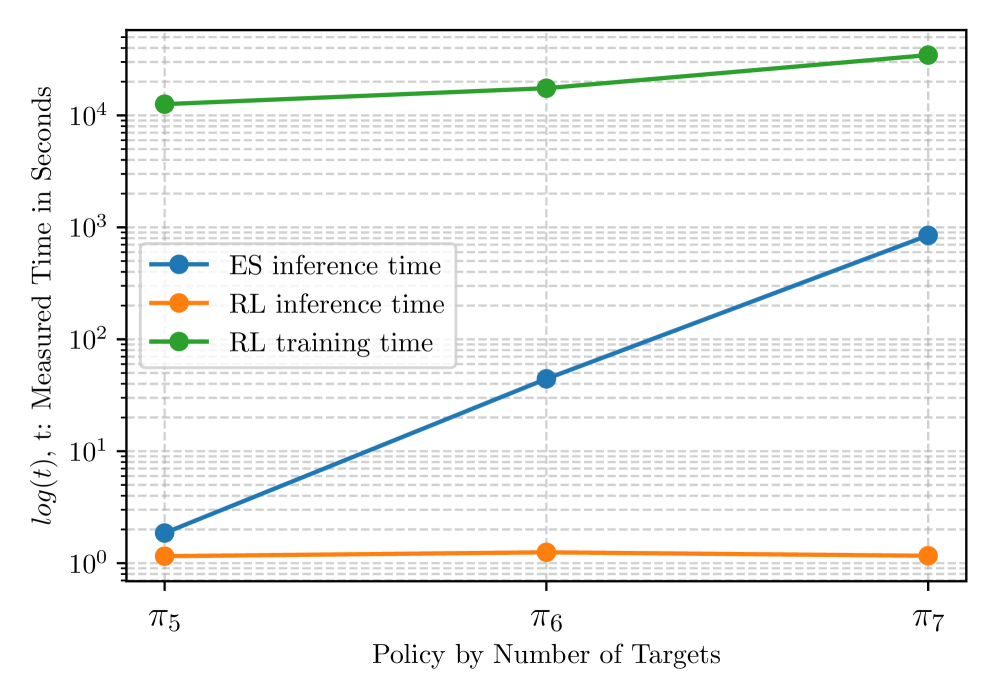 Figure 3: RL inference and training time measurements compared to the inference time of the ES approach with respect to the trained policies by number of solved targets.
Figure 3: RL inference and training time measurements compared to the inference time of the ES approach with respect to the trained policies by number of solved targets.
Why This Matters for Drones
This research is a significant step towards practical, autonomous drone fleets that can tackle complex, dynamic missions. Here's what this means for drone hobbyists, builders, and engineers:
- Advanced Inspection & Monitoring: Consider a fleet of specialized drones inspecting a power plant or a wind farm. A fixed-wing drone maps the area, a quadcopter with a thermal camera identifies hot spots, and a ground rover takes close-up readings. This framework could orchestrate their movements, ensuring optimal coverage and rapid response to anomalies.
- Search and Rescue: In disaster zones, a swarm of small drones could rapidly map collapsed structures, while larger drones deliver supplies, and ground robots search confined spaces. Real-time replanning would be critical as new information emerges.
- Logistics and Delivery: For large warehouses or urban delivery networks, heterogeneous fleets could optimize routes, manage charging stations, and adapt to changing demand or obstacles.
- Extraterrestrial Exploration: The paper's primary motivation – Mars exploration – is a perfect fit. A drone surveys canyons, a rover collects samples, and a legged robot navigates difficult terrain, all coordinated to maximize scientific data collection under communication delays and unknown conditions.
The ability to mix and match drone types, each bringing a specific tool to the job, dramatically expands the utility of autonomous systems. This isn't just about flying faster; it's about flying smarter, together.
Limitations and What's Still Needed
While promising, this work has its limitations. Understanding these is key for anyone considering real-world deployment:
- Simulated Environment: The experiments were conducted in a simplified grid-world environment. Real-world physics, complex aerodynamics, battery life, varying payloads, and unpredictable weather are significant factors not fully modeled here.
- Communication Robustness: The current model assumes reliable communication between agents (for sharing global state during training and for decentralized execution). In harsh environments like Mars or industrial sites, communication dropouts are a real concern and require more robust decentralized coordination mechanisms.
- Generalization to Novel Environments: While RL agents can generalize, training in one type of environment doesn't guarantee optimal performance in a vastly different, unstructured real-world setting. Significant data collection and sim-to-real transfer techniques would be necessary.
- Training Time: Although inference is fast, the training phase for these complex policies can be computationally intensive and time-consuming. This is a common trade-off in RL but still a practical consideration for rapid iteration.
- Real-world Sensor Integration: The paper focuses on planning. Integrating this with real-time perception from diverse sensors (LiDAR, cameras, thermal) on heterogeneous robots, as highlighted by related work, adds another layer of complexity.
DIY Feasibility: Not for a Weekend Project (Yet)
Replicating this research as a hobbyist is a significant undertaking. While the concepts are clear, the implementation demands significant expertise in:
- Reinforcement Learning: Understanding and implementing
MAPPOrequires a solid foundation in deep learning and RL frameworks likePyTorchorTensorFlow. - Multi-Agent System Design: Building a robust simulation environment capable of modeling heterogeneous agents with distinct skills and complex task dependencies.
- Computational Resources: Training these models requires powerful GPUs and substantial processing power, likely beyond typical home setups.
However, the underlying principles are transferable. If you're building a simpler multi-drone system using ROS or a similar framework, the idea of task allocation and basic coordination could be inspired by this. The jump from a grid-world simulation to real drone hardware with full dynamics is a chasm, not a gap.
Powering the Fleet: Related Advancements
This research doesn't stand alone. Other recent work directly supports the vision of sophisticated, collaborative drone teams:
For these heterogeneous robotic teams to operate effectively, each drone needs robust and efficient perception. The paper "Lightweight Prompt-Guided CLIP Adaptation for Monocular Depth Estimation" by Reyhaneh Ahani Manghotay and Jie Liang provides an efficient, 'edge AI' solution for crucial monocular depth estimation. This allows individual drones, often with limited onboard compute, to gain essential spatial awareness, feeding into the collaborative planning and navigation of the entire team. This local perception is a vital input for the global planning system described in our main paper.
Furthermore, testing such advanced planning systems requires robust simulation environments. "ReinDriveGen: Reinforcement Post-Training for Out-of-Distribution Driving Scene Generation" by Hao Zhang, Lue Fan, Weikang Bian et al. offers a method to create and simulate highly controllable, safety-critical scenarios. This is essential for rigorously testing the planning and navigation capabilities of heterogeneous drone teams before deploying them in real-world, high-stakes environments like extraterrestrial exploration or complex urban operations.
And finally, understanding the environments these teams will operate in is critical. "VRUD: A Drone Dataset for Complex Vehicle-VRU Interactions within Mixed Traffic" by Ziyu Wang, Hongrui Kou, Cheng Wang et al. highlights the kind of complex, dynamic environments (like urban traffic, or by extension, unpredictable extraterrestrial terrain) where such advanced autonomous teams would need to operate. It also showcases drones as crucial tools for collecting the vital data needed to train and validate these autonomous systems, closing the loop from data collection to deployment.
These complementary works underscore a broader trend: the pieces are falling into place for truly intelligent, adaptive, and collaborative robotic systems.
This research brings us closer to a future where drone teams aren't just flying in formation, but thinking and acting as a cohesive, specialized unit, ready to tackle the most demanding missions on Earth and beyond.
Paper Details
Title: Collaborative Task and Path Planning for Heterogeneous Robotic Teams using Multi-Agent PPO Authors: Matthias Rubio, Julia Richter, Hendrik Kolvenbach, Marco Hutter Published: 2024-04-03 (arXiv v1) arXiv: 2604.01213 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.