R-C2: Unlocking Consistent AI for Autonomous Drones
A new reinforcement learning framework, R-C2, teaches AI models to resolve conflicting information from different sensor modalities, improving reasoning accuracy by up to 7.6 points and ensuring consistent predictions.
TL;DR: R-C2 introduces a reinforcement learning approach that teaches AI models to achieve 'cycle consistency' across different data types (like visual and text). This allows drones to learn from their own internal disagreements, leading to a more reliable and accurate understanding of their environment, even when sensors provide contradictory signals.
Autonomous drones are amazing, but their intelligence often hits a wall when faced with conflicting information from their own 'senses.' A drone's vision system might interpret a scene one way, while its linguistic processing (for instructions or labels) sees it differently. This paper, "R-C2: Cycle-Consistent Reinforcement Learning Improves Multimodal Reasoning," tackles this fundamental problem head-on, offering a path to truly robust, consistent drone AI. It's about teaching AI to resolve its own internal squabbles, rather than just averaging them out.
When AI Gets Confused: The Modality Gap
Modern AI models, especially those trying to understand the world through multiple data streams (like video, text, radar, LiDAR), often struggle with a critical flaw: inconsistency. They might give one answer when looking at a camera feed and a completely different one when reading a textual description of the same object or event. This isn't just an academic issue; for a drone, such internal contradictions can mean the difference between a safe landing and a crash, or between following a command and misinterpreting it. Current approaches often try to 'vote' between modalities to find a consensus, but this can amplify existing biases or even discard the correct signal if it's in the minority. We've seen this play out in complex scenarios where a model might confidently misidentify an obstacle because its visual and textual understanding aren't truly aligned.
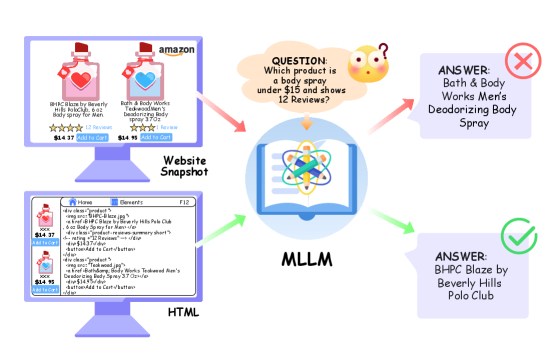 Figure 1: Multimodal Large Language Models (MLLMs) frequently produce conflicting answers for the same webpage when presented as a screenshot versus its raw HTML source. R-C2 targets this modality gap.
Figure 1: Multimodal Large Language Models (MLLMs) frequently produce conflicting answers for the same webpage when presented as a screenshot versus its raw HTML source. R-C2 targets this modality gap.
This 'modality gap' is a serious barrier to deploying fully autonomous systems. As Figure 1 illustrates, giving an AI the same information in two different formats (e.g., a screenshot versus raw HTML) can lead to wildly different, contradictory answers. This isn't just about slight variations; it's about fundamental disagreements on the same core concept. Furthermore, simple voting mechanisms, as shown in Figure 2, can fail. Whether it's a "consistent conflict" where both modalities are self-consistent but disagree, or an "unstable recovery" where a correct answer is lost to a majority of wrong ones, current methods aren't cutting it.
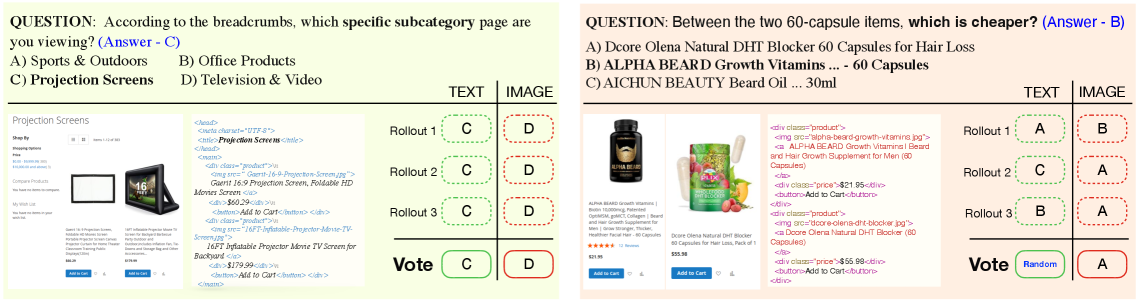 Figure 2: Multimodal voting can amplify biases or lose correct signals, as shown by consistent conflicts between modalities or unstable recoveries within a single modality.
Figure 2: Multimodal voting can amplify biases or lose correct signals, as shown by consistent conflicts between modalities or unstable recoveries within a single modality.
Teaching AI to Check Its Own Work
So, how do you fix an AI that can't agree with itself? R-C2 (Cycle-Consistent Reinforcement Learning) introduces an ingenious solution: it leverages these inconsistencies as a powerful learning signal. Instead of ignoring or masking conflicts, R-C2 actively seeks them out and uses them to refine the AI's internal understanding. The core idea is 'cycle consistency.' Consider an answer. The model is then tasked with working backward from it to reconstruct the original question or query, first through one modality (say, text) and then through another (like an image). Then, it uses these reconstructed queries to predict the answer again, checking if all paths lead back to the original answer. If they don't, that's a signal to learn.
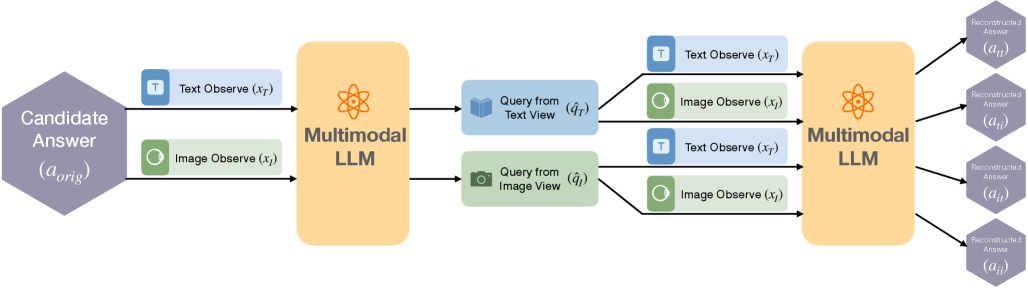 Figure 3: R-C2 enforces a 4-way cross-modal reasoning cycle: from an original answer candidate, the model performs backward inference to reconstruct queries from text and image views, then uses those queries for forward inference across both modalities, ensuring consistency with the original answer.
Figure 3: R-C2 enforces a 4-way cross-modal reasoning cycle: from an original answer candidate, the model performs backward inference to reconstruct queries from text and image views, then uses those queries for forward inference across both modalities, ensuring consistency with the original answer.
This isn't just a forward-pass prediction; it's a deep, self-correcting loop. As Figure 3 details, the model starts with a potential answer, a_orig. It then performs "backward inference" to generate distinct queries (q^T for text, q^I for image) that would lead to that answer. These reconstructed queries are then used for "forward inference" across both modalities, generating four new answers (a_tt, a_ti, a_it, a_ii). The closer these reconstructed answers are to a_orig, the higher the reward. This label-free reward signal forces the model to align its internal representations, making its understanding robust across different sensory inputs. Figure 4 provides a concrete example of this crucial backward-inference step, demonstrating that the model can indeed generate semantically grounded queries from an answer, a critical enabler for the cycle consistency reward.
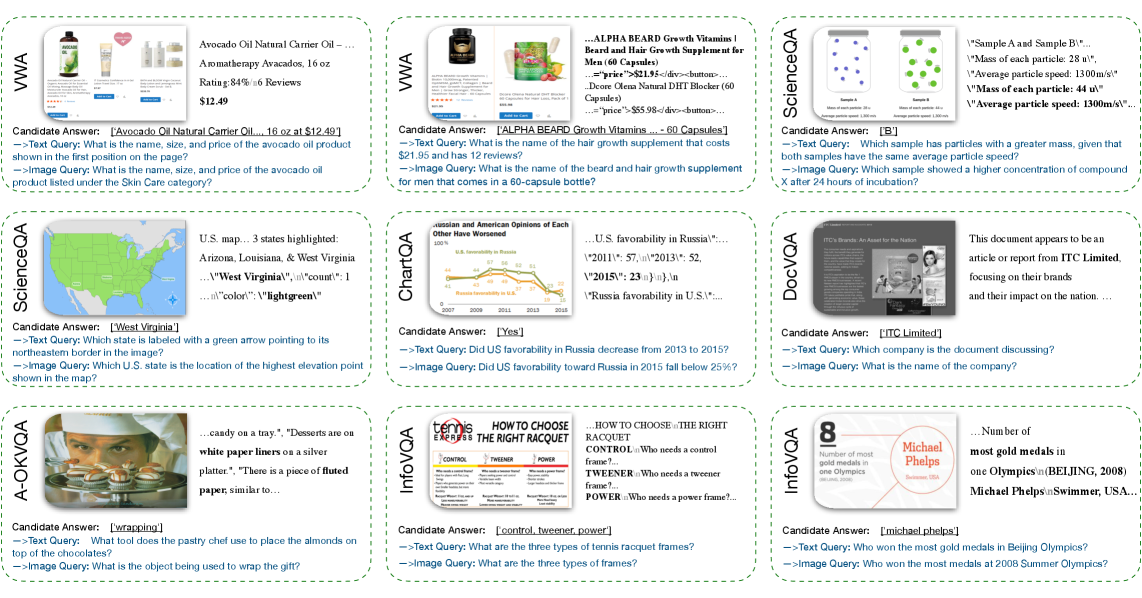 Figure 4: Given a candidate answer, the model generates distinct, semantically-grounded queries for both text and image modalities, enabling the cycle-consistency check.
Figure 4: Given a candidate answer, the model generates distinct, semantically-grounded queries for both text and image modalities, enabling the cycle-consistency check.
Tangible Gains in Consistency and Accuracy
The results are compelling. R-C2 doesn't just make models more consistent; it significantly boosts their accuracy. The paper reports improvements of up to 7.6 points in reasoning accuracy. This isn't a small tweak; it's a substantial jump that indicates a deeper, more robust understanding. When benchmarked against traditional methods and even simple voting baselines, R-C2 consistently outperforms them.
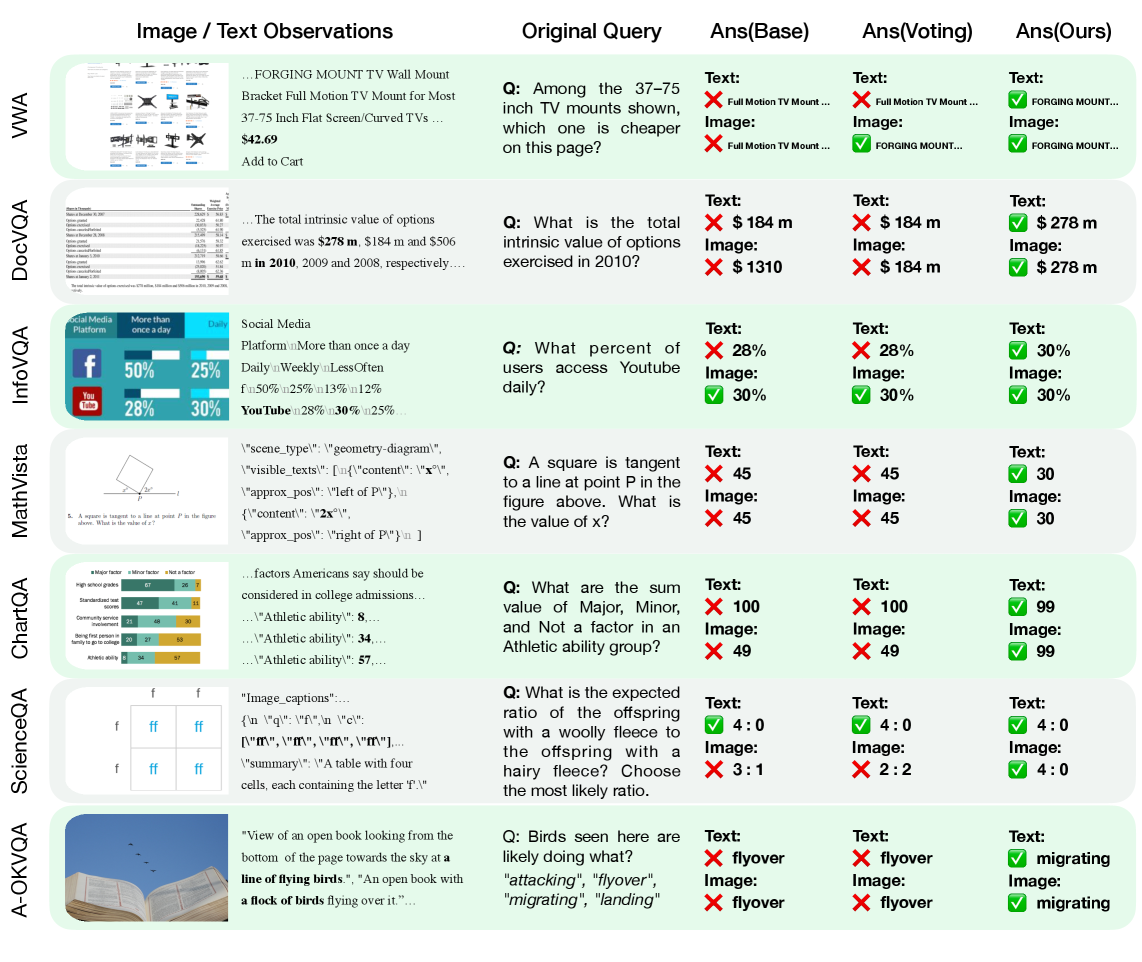 Figure 5: Visual comparison shows R-C2 producing answers that are both correct and consistent across modalities, unlike base models or voting baselines which often conflict or agree on incorrect predictions.
Figure 5: Visual comparison shows R-C2 producing answers that are both correct and consistent across modalities, unlike base models or voting baselines which often conflict or agree on incorrect predictions.
Looking at the numbers:
- Reasoning Accuracy: Improves by up to 7.6 points, showing a meaningful gain in core task performance.
- Cross-modal Consistency Ratio: Significantly increases, demonstrating the model's improved ability to provide the same correct answer regardless of the input modality. For example, on the ScienceQA dataset, R-C2 shows a marked improvement in average accuracy across image and text modalities (Figure 6) and a clear boost in cross-modal prediction consistency (Figure 7).
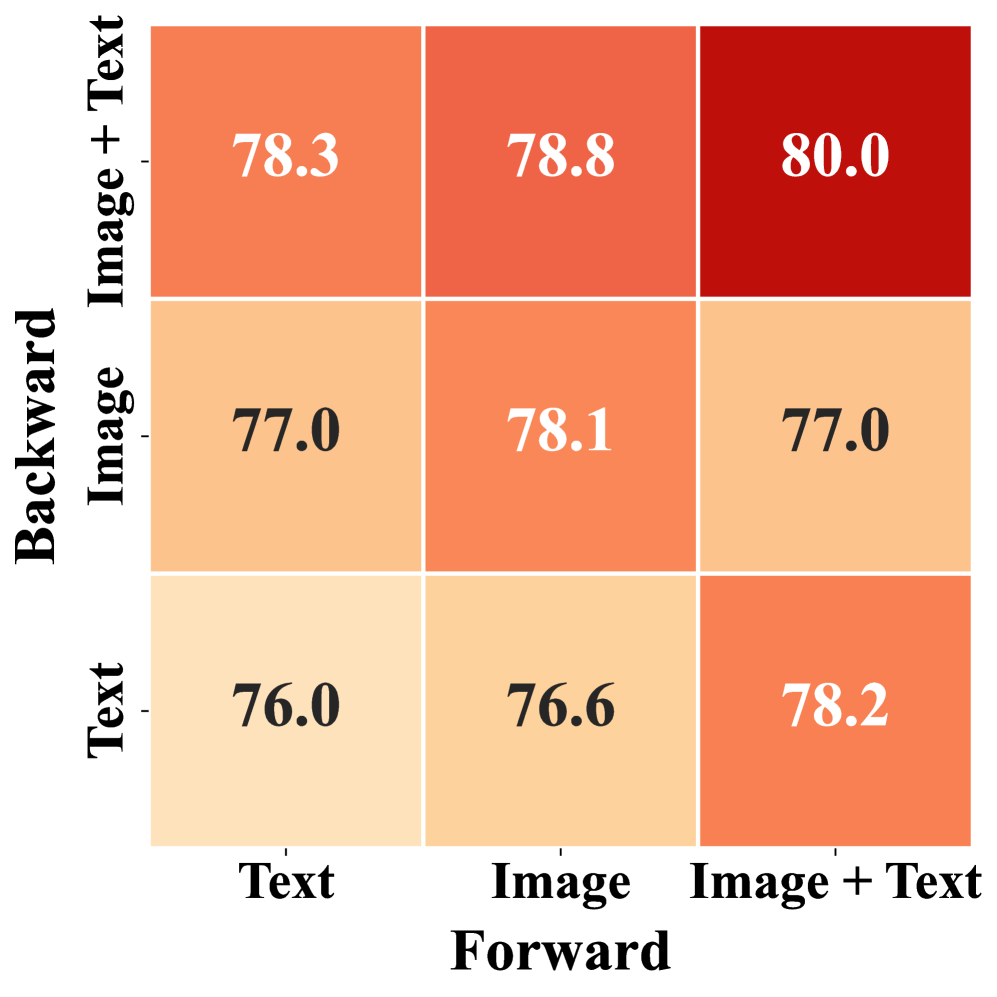 Figure 6: Average accuracy across image and text modalities, showing R-C2's performance improvement.
Figure 6: Average accuracy across image and text modalities, showing R-C2's performance improvement.
 Figure 7: Cross-modal predictions consistency ratio, indicating how often the model's predictions align across different input types.
Figure 7: Cross-modal predictions consistency ratio, indicating how often the model's predictions align across different input types.
Intriguingly, the authors found that training with more inconsistent samples actually improved both accuracy and consistency. As shown in Figure 8, pushing the model to confront more disagreements during training forces it to learn better internal alignment. This highlights the power of using inconsistency itself as a supervisory signal.
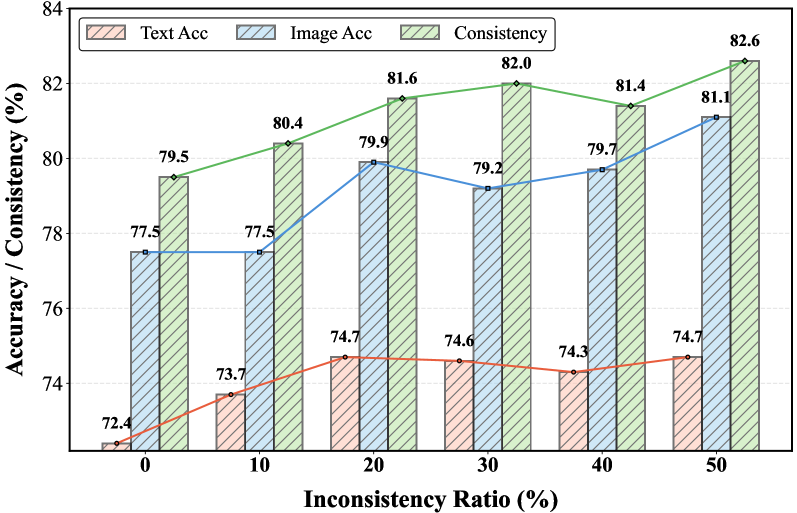 Figure 8: As the inconsistency ratio in training samples increases, both answer accuracy and cross-modal consistency systematically improve with R-C2, suggesting that conflicts provide a useful structural signal.
Figure 8: As the inconsistency ratio in training samples increases, both answer accuracy and cross-modal consistency systematically improve with R-C2, suggesting that conflicts provide a useful structural signal.
Why This Matters for Drones
For drone hobbyists, builders, and engineers, R-C2 represents a leap towards truly robust autonomous flight. Think about a drone navigating a complex urban environment. It needs to interpret camera feeds, LiDAR point clouds, and potentially textual instructions (e.g., "land on the red pad"). If its visual system identifies a "red pad" but its internal reasoning, perhaps influenced by a slightly ambiguous text label, thinks it's a "red path," you have a problem. R-C2 ensures that these interpretations are consistent. This translates directly to:
- Reliable Obstacle Avoidance: Consistent understanding of objects regardless of viewing angle or sensor noise.
- Accurate Navigation: Fusing GPS, visual odometry, and inertial data with higher confidence.
- Safer Human-Drone Interaction: Drones that interpret verbal commands and visual cues without internal conflict.
- Advanced Mission Execution: Enabling complex tasks where consistent understanding of environmental cues is paramount, like inspection or delivery. A drone equipped with R-C2 could, for example, consistently identify a specific type of damage on a structure, whether it's analyzing high-resolution imagery or interpreting textual reports from previous inspections. This is a foundational step toward drones that don't just react but truly understand their operational context.
The Road Ahead: Limitations and Real-World Hurdles
While R-C2 is a powerful advancement, it's not a magic bullet. The approach relies heavily on the ability of the underlying MLLM to perform credible backward inference (Answer -> Query). If the base model struggles with this fundamental step, the cycle-consistency reward might not be as effective. The paper primarily evaluates R-C2 on multimodal reasoning tasks involving images and text, often in a question-answering format. Applying this directly to real-time, high-dimensional drone sensor data (like streaming video, LiDAR, radar, thermal) would require significant engineering effort.
Real-world deployment faces challenges:
- Computational Overhead: The cyclic inference process, involving multiple forward and backward passes, could be computationally intensive. For edge devices like drones, optimizing this for low-power, real-time operation is crucial.
- Sensor Modality Diversity: While text and image are key, drones use many more modalities. Extending R-C2 to seamlessly integrate, say, LiDAR point clouds or acoustic data, would be complex but necessary for full autonomy.
- Dynamic Environments: The consistency needs to hold not just for static observations but across dynamic, rapidly changing scenes, which adds another layer of complexity.
- Dataset Limitations: The paper uses datasets like ScienceQA and a newly proposed VWA (Visual Webpage Answer) dataset for shopping webpages (Figures 9 and 10). While valuable, these don't directly mirror the chaotic, unpredictable environments drones operate in. More drone-specific, multimodal datasets with explicit inconsistencies would be needed for tailored training.
 Figure 9: Examples from the VWA multiple-choice dataset, used to evaluate multimodal reasoning on shopping webpages.
Figure 9: Examples from the VWA multiple-choice dataset, used to evaluate multimodal reasoning on shopping webpages.
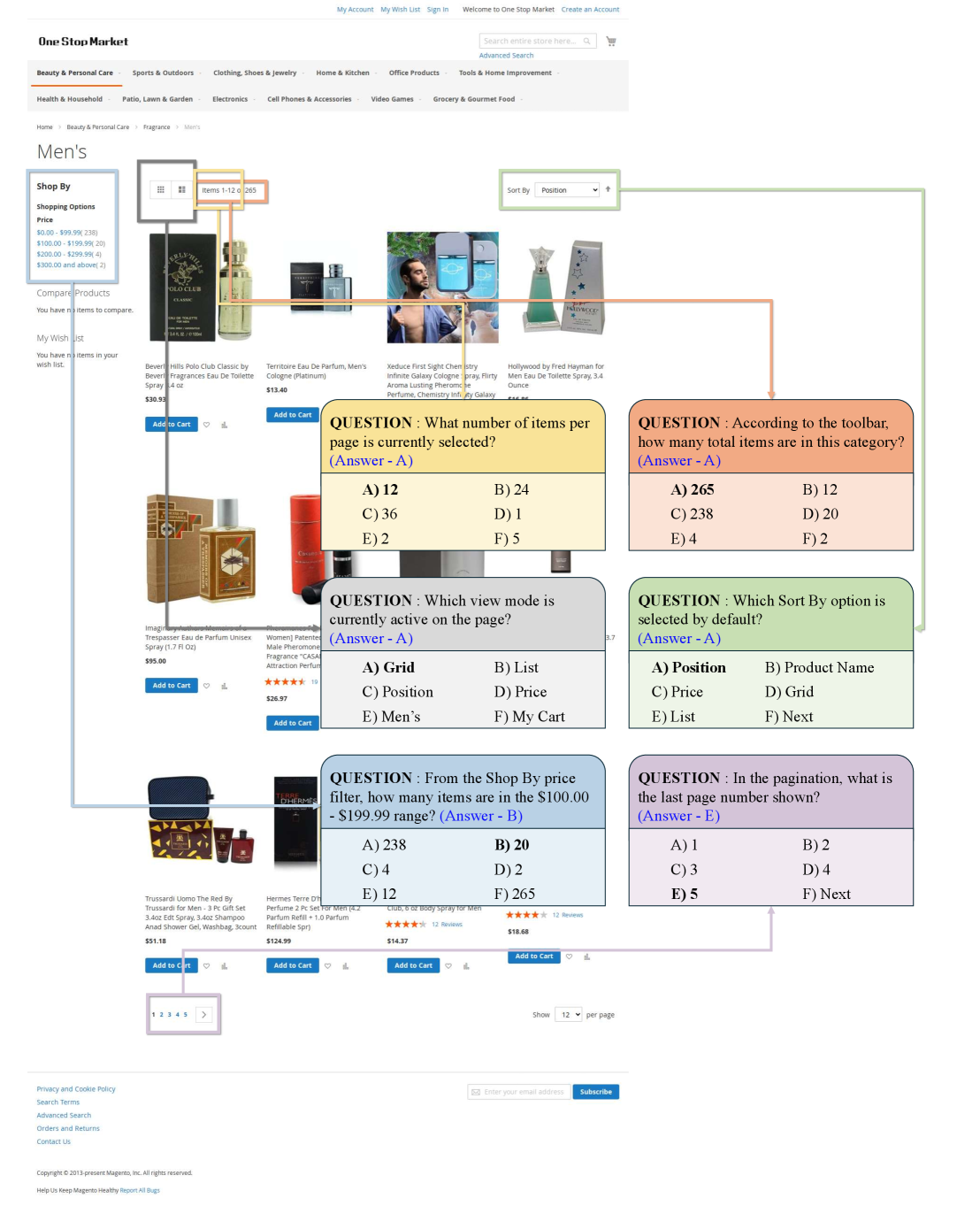 Figure 10: Further examples from the VWA dataset, highlighting the types of questions and multimodal inputs used for evaluation.
Figure 10: Further examples from the VWA dataset, highlighting the types of questions and multimodal inputs used for evaluation.
Can You Build This Yourself?
Replicating R-C2 at a hobbyist level would be challenging but not impossible for a dedicated builder with strong AI/ML experience. The core framework is based on reinforcement learning fine-tuning of existing Multimodal Large Language Models (MLLMs) like Qwen2.5-VL-3B-Instruct. You'd need access to significant GPU resources for training, as these models are substantial. The authors do not explicitly mention releasing code, but the principles are outlined. Adapting this to a drone's onboard computer would require efficient model quantization and specialized inference engines. For now, this is more in the realm of advanced research labs and well-funded development teams, but the concepts are open for exploration.
Aligning Perspectives: Broader AI Implications
This work fits into a broader trend of making AI more robust and trustworthy. For instance, Vega: Learning to Drive with Natural Language Instructions explores how autonomous systems can interpret natural language commands, which an R-C2-enhanced drone would need to process consistently alongside visual data. Similarly, MegaFlow: Zero-Shot Large Displacement Optical Flow provides crucial motion sensing, a fundamental visual 'sense' that R-C2 could ensure is consistently integrated with other perceptions for accurate navigation. The fine-grained temporal understanding in SlotVTG: Object-Centric Adapter for Generalizable Video Temporal Grounding is another complex visual task that would benefit from R-C2's consistency. Ultimately, ensuring models like those discussed in Drive My Way: Preference Alignment of Vision-Language-Action Model for Personalized Driving consistently apply learned preferences is vital for reliable personalized drone operations.
The R-C2 framework offers a compelling vision for AI systems that don't just perceive, but truly understand with unwavering consistency. This isn't just about better benchmarks; it's about building the foundation for the next generation of truly autonomous, trustworthy drones.
Paper Details
Title: R-C2: Cycle-Consistent Reinforcement Learning Improves Multimodal Reasoning Authors: Zirui Zhang, Haoyu Dong, Kexin Pei, Chengzhi Mao Published: March 2026 (arXiv preprint) arXiv: 2603.25720 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.