Teaching Drones Context: The Next Leap in Autonomy
A new benchmark, Referring Scenario Comprehension (RSC), pushes drone AI beyond basic object identification. It teaches systems to understand roles, intentions, and relational context from paragraph-length queries, unlocking advanced autonomous capabilities.
TL;DR: A new benchmark, Referring Scenario Comprehension (RSC), pushes visual grounding beyond simple object naming. It trains drone AI to understand complex situations, roles, and intentions from detailed text descriptions, enabling deeper contextual awareness for truly autonomous missions.
Beyond Object Detection: Drones That Understand the Story
We're all familiar with drones that can spot a person or a car. That's basic object detection, and it's table stakes now. But what if your drone needed to find "the person wearing a red hat, holding a package, who just exited the blue building, not the one talking on the phone"? That's a whole different level of understanding, one that moves beyond mere labels to grasp the full context of a situation. This new research introduces a benchmark called Referring Scenario Comprehension (RSC) that tackles exactly this challenge, aiming to build AI models that don't just see objects, but understand the entire story playing out in a scene.
The Limits of Current Drone Vision
Current visual grounding models are pretty good at matching a simple phrase like "the red car" to a specific object in an image. These benchmarks, like RefCOCO+ or RefCOCOg, focus on literal referring expressions. The problem? Real-world drone missions are rarely that simple. A drone isn't just looking for "a package"; it might be looking for "the package left unattended near the gate, possibly containing a hazardous material, and not the one being actively loaded onto the truck."
Existing systems often succeed by just finding a prominent category name. They lack the nuanced understanding of roles, intentions, and relational context necessary for complex tasks. This limitation means drones often get stuck on ambiguous instructions or fail to differentiate between visually similar but contextually distinct objects, leading to inefficient operations, missed targets, or even incorrect actions. For critical applications, this isn't just an inconvenience; it's a fundamental roadblock to true autonomy.
Training Drones to Read Between the Lines
The RSC benchmark fundamentally changes how we train visual AI. Instead of short, explicit object names, it uses paragraph-length text queries that describe user roles, goals, and contextual cues. These queries are designed to be challenging, often including deliberate references to distractor objects that require deep understanding to resolve.
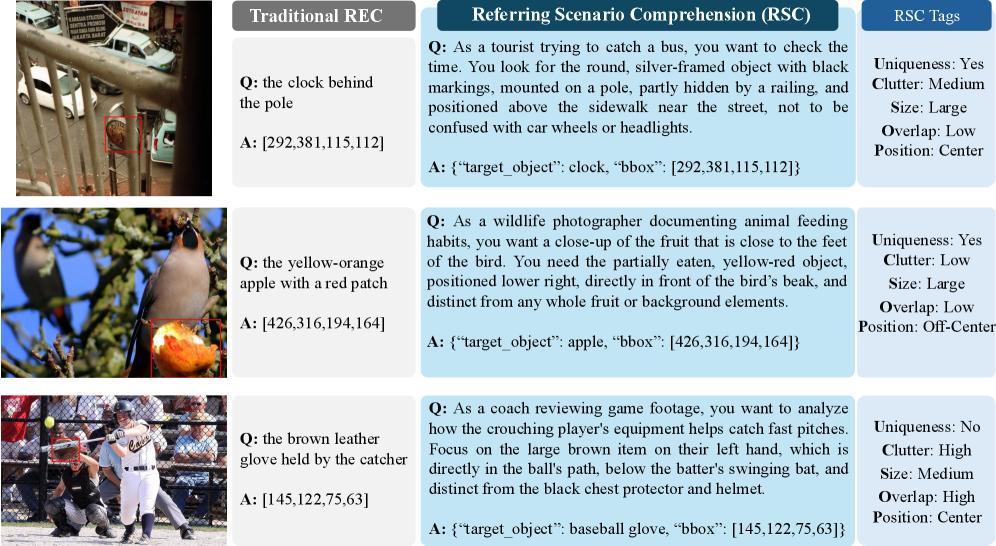 Figure 1: RSC queries demand a deeper understanding of context and relationships compared to traditional object naming.
Figure 1: RSC queries demand a deeper understanding of context and relationships compared to traditional object naming.
The researchers developed a method called ScenGround, a curriculum reasoning approach. It starts with supervised warm-starting and then uses difficulty-aware reinforcement learning. This means the model learns from easier examples first, then progressively tackles harder scenarios, getting better at interpreting the subtle cues and relationships. ScenGround is designed to reason through these complex scenarios, even ignoring distractors explicitly mentioned in the text.
![ScenGround prompt and output schema. Given an image and a user-driven scenario, the model is instructed to reason inside <think> and to emit a structured JSON inside <answer>. The JSON contains target_object and bbox [x,y,w,h]. Scenarios avoid category names and force disambiguation via attributes, relations, and spatial cues, while <think> must justify the selection and ignore distractors. This schema is used in both TP-SFT and IC-GRPO. To increase the robustness of ScenGround, IC-GRPO uses 7 other templates.](https://qawnehlcoileybzacnvr.supabase.co/storage/v1/object/public/article-covers/figures/teaching-drones-context-the-next-leap-in-autonomy-mnkiswgo/fig-2.png) Figure 3:
Figure 3: ScenGround processes detailed scenario prompts, generating a reasoned output to identify the target object and its bounding box.
The RSC dataset itself is massive, with approximately 31,000 training examples, 4,000 in-domain test examples, and a 3,000 out-of-distribution split. Each instance comes with interpretable difficulty tags—Uniqueness, Clutter, Size, Overlap, and Position—which are critical for fine-grained analysis and targeting specific failure modes. This granular tagging allows models to be specifically tuned for cluttered environments or small, overlapping objects, for example.
Beyond Simple Metrics: Understanding Why Models Fail
The experiments with RSC reveal systematic failures in current models that standard benchmarks simply don't expose. It's not just about a higher accuracy number; it's about why models fail.
- RSC queries are substantially longer than traditional ones, peaking around 50-60 words compared to under 10 words for
RefCOCO+andRefCOCOg. This requires models to process and understand significantly more information (Figure 5). - The dataset covers a broader range of instance sizes, with a higher density of smaller objects, which are notoriously difficult for vision systems (Figure 6).
ScenGround, the proposed reference model, showed significant improvements, particularly on these challenging slices of the data. For instance, on the RSC in-domain test set,ScenGroundachieves a 48.2% accuracy on the full test set, outperforming the strong baselineOFA-Large(42.2%) by a considerable margin.- Crucially, the improvements gained from training on RSC also transferred to standard benchmarks, indicating that this deeper contextual understanding isn't just for niche scenarios; it makes models generally more robust.
- Qualitative results demonstrate
ScenGround's ability to correctly identify targets based on complex relational and contextual cues, even when distractors are present (Figure 4).
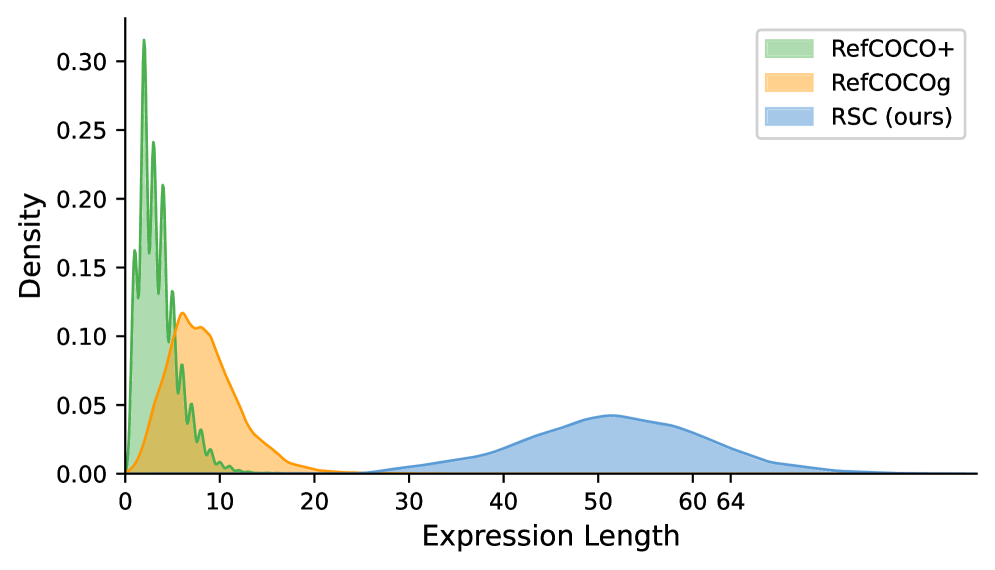 Figure 5: RSC queries are significantly longer and more complex, demanding deeper language comprehension from AI models.
Figure 5: RSC queries are significantly longer and more complex, demanding deeper language comprehension from AI models.
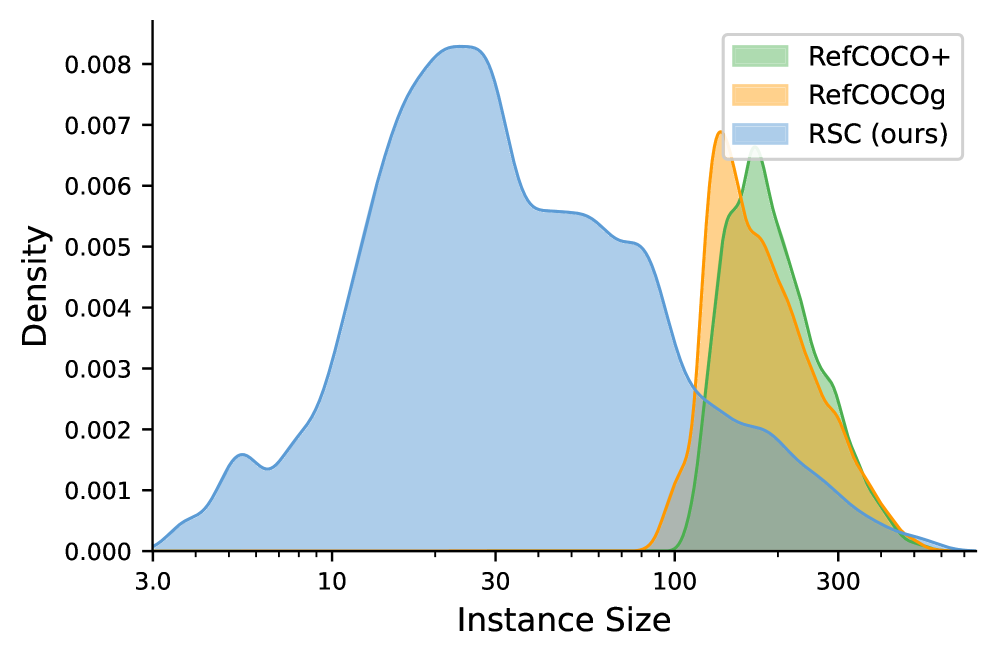 Figure 6: The RSC dataset includes a wider variety of object sizes, particularly smaller instances, posing a greater challenge for object detection.
Figure 6: The RSC dataset includes a wider variety of object sizes, particularly smaller instances, posing a greater challenge for object detection.
 Figure 4: Examples showing
Figure 4: Examples showing ScenGround's ability to accurately identify targets based on complex scenario descriptions.
Unlocking Truly Intelligent Drone Missions
This research fundamentally shifts drone autonomy from reactive object detection to proactive scenario comprehension. Instead of merely identifying "a drone," a system could identify "the drone with the malfunctioning rotor, flying erratically near the power lines, needing immediate intervention."
Consider these implications:
- Search and Rescue: A drone could be instructed to find "the person wearing a bright yellow jacket, signaling for help, near the overturned boat, but ignore the debris field."
- Automated Inspection: An inspection drone could identify "the pipe showing signs of leakage, specifically where the rust is most concentrated, not the general discoloration."
- Logistics and Delivery: A delivery drone might need to locate "the designated drop-off zone marked by a blue tarp, next to the white delivery van, avoiding the garden hose."
- Environmental Monitoring: Identify "the specific tree showing signs of infestation, characterized by unusual leaf discoloration and insect activity, separate from healthy foliage."
These aren't just advanced object detections; they are context-rich tasks that require understanding relationships, intentions, and potential problems. This level of intelligence is crucial for drones operating in complex, dynamic, and often ambiguous real-world environments.
The Road Ahead: Current Limitations
While RSC is a crucial step, it's important to be clear-eyed about its current scope.
- Still Images: The benchmark currently focuses on static images. Real-world drone missions involve continuous video streams, where temporal context and object trajectories are vital. Understanding how a scenario unfolds over time is the next frontier.
- Computational Cost: Processing paragraph-length queries and performing deep contextual reasoning isn't cheap. Deploying these models on edge hardware (like a typical drone flight controller) will require significant optimization for power and processing efficiency.
- Generalization to New Scenarios: While the out-of-distribution split helps, the sheer variety of real-world scenarios, especially those involving rare events or highly abstract concepts, will continue to challenge models. Robustness to truly novel situations remains a hurdle.
- Actionable Intelligence: RSC focuses on grounding visual elements. The next logical step is not just "what is it?" but "what should I do about it?" This involves integrating with planning and control systems.
Building Smarter Drone Brains for Enthusiasts
For hobbyists and builders keen on pushing the boundaries of drone intelligence, RSC offers a powerful new avenue. The dataset and benchmark are publicly available, enabling anyone with sufficient computational resources and machine learning expertise to train their own models.
While running ScenGround or similar large vision-language models (VLMs) might require GPU-equipped workstations or cloud access for training, the inference step could eventually be optimized for smaller, dedicated AI accelerators on drones. The challenge is in the model size and complexity. Developers working with NVIDIA Jetson platforms or similar edge AI hardware could experiment with quantizing or pruning these models for on-board deployment. This is not a weekend project on a Raspberry Pi, but for serious builders, it's a clear path to developing more intelligent drone behaviors.
Connecting the Pieces of Autonomy
This pursuit of deeper scenario understanding doesn't happen in a vacuum. Once a drone can comprehend a complex scenario with the depth provided by RSC, the next logical step is to navigate and act intelligently within that scenario. This is where research like "Stop Wandering: Efficient Vision-Language Navigation via Metacognitive Reasoning" by Li et al. becomes critical. It provides methods for efficient Vision-Language Navigation, directly enabling drones to use their newfound 'scenario understanding' to follow high-level instructions without redundant exploration, bridging comprehension with effective action.
Furthermore, comprehending complex scenarios, especially over long missions, means managing a vast amount of visual and textual information. The challenge of efficient memory management for autonomous agents is addressed in "Novel Memory Forgetting Techniques for Autonomous AI Agents: Balancing Relevance and Efficiency" by Fofadiya and Tiwari. This ensures drones can remember relevant details for scenario comprehension while discarding outdated or irrelevant information, vital for sustained, intelligent operation on limited edge hardware.
Finally, the ability to process continuous video streams efficiently is paramount for real-time scenario comprehension. The paper "A Simple Baseline for Streaming Video Understanding" by Shen et al. demonstrates that robust streaming video understanding can be achieved with surprisingly simple VLM techniques, making the ambitious goal of real-time scenario comprehension more feasible and practical for deployment on drones with limited computational resources. This is key for taking static image understanding into the dynamic world of drone flight.
The Future is Contextual
RSC is more than just another benchmark; it's a clear roadmap for developing drones that don't just see pixels and objects, but truly understand their world, allowing them to execute missions with unprecedented autonomy and intelligence. The future of drone operations hinges on this ability to grasp the full story.
Paper Details
Title: Beyond Referring Expressions: Scenario Comprehension Visual Grounding Authors: Ruozhen He, Nisarg A. Shah, Qihua Dong, Zilin Xiao, Jaywon Koo, Vicente Ordonez Published: April 2, 2026 arXiv: 2604.02323 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.