Why Your Smart Drone's Brain Might Be Stuck: The 'Compression Gap'
New research reveals a critical 'compression gap' preventing Vision-Language-Action (VLA) models from scaling effectively in physical AI systems like drones. When actions are discretized, improving the vision encoder often yields no performance gains.
TL;DR: Upgrading the vision encoder in Vision-Language-Action (VLA) models often fails to improve drone performance when actions are represented as discrete tokens. This is due to an information bottleneck—the "compression gap"—where rich visual data is lost during action discretization, making continuous action policies critical for true scaling.
Smarter Drones Aren't Just About Better Eyes
For years, the promise of truly autonomous drones has hinged on giving them better "eyes"—more sophisticated vision systems. The common assumption: improve the vision encoder in a Vision-Language-Action (VLA) model, and your drone will understand the world better, leading to more precise and intelligent actions. A new paper, "The Compression Gap: Why Discrete Tokenization Limits Vision-Language-Action Model Scaling," challenges this fundamental assumption for a significant class of AI models, and it has major implications for how we build the next generation of smart drones.
The Bottleneck You Didn't See Coming
We've all seen the incredible leaps in vision-language models (VLMs). Beefing up the vision component in these models often leads to better image understanding, more accurate descriptions, and improved reasoning. Naturally, we'd expect the same for VLA models, which are designed to act in the physical world. If a drone sees better, it should fly better, right?
This paper argues that for many current VLA architectures, this isn't true. The problem isn't with the vision encoder itself, but with how the model translates its understanding into actions. Many VLA models simplify action generation by discretizing them—turning a continuous range of movements into a fixed set of predefined "tokens." Think of it like choosing from a limited menu of pre-programmed maneuvers instead of fluidly adjusting every control input.
This approach, while computationally simpler and often easier to train, introduces a critical limitation. No matter how much more detail your drone's vision system captures, if its action vocabulary is limited, that extra visual information can't be used. It's like having a super-HD camera feeding into a system that can only output pixelated images. This isn't just inefficient; it's a hard limit on performance that wastes valuable compute resources and development effort.
Unpacking the "Compression Gap"
The authors introduce the concept of the "Compression Gap" to explain this phenomenon. They propose an information-theoretic principle: scaling behavior in any visuomotor pipeline is dictated by its tightest information bottleneck. When actions are continuous, the vision encoder is indeed the primary constraint. Upgrade it, and performance improves across the board.
However, when actions are discretized using a fixed-capacity codebook (as seen in models like OAT—Observation-Action Transformer), that codebook becomes the bottleneck. The rich information from an upgraded vision encoder simply cannot propagate past this discrete action representation. It gets compressed and lost, irrespective of how sophisticated the upstream vision processing becomes.
To illustrate, consider the two pathways below:
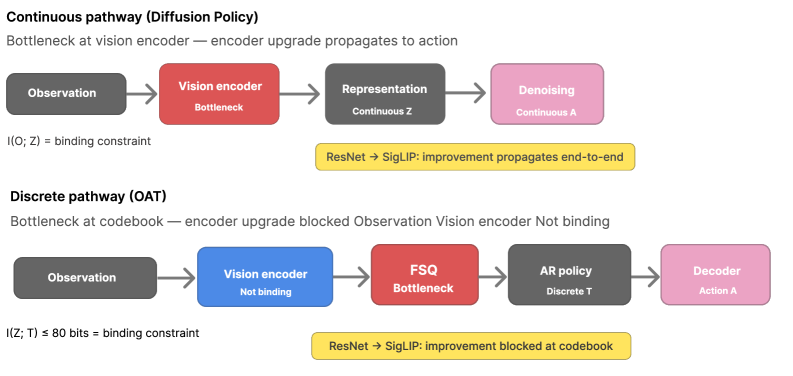 Figure 1: The Compression Gap. In the continuous pathway (Diffusion Policy), the vision encoder is the binding bottleneck; upgrading it propagates end-to-end. In the discrete pathway (OAT), the codebook (I(Z;T)≤80 bits) is the binding bottleneck; encoder upgrades are blocked at quantization.
Figure 1: The Compression Gap. In the continuous pathway (Diffusion Policy), the vision encoder is the binding bottleneck; upgrading it propagates end-to-end. In the discrete pathway (OAT), the codebook (I(Z;T)≤80 bits) is the binding bottleneck; encoder upgrades are blocked at quantization.
In the continuous pathway (represented by Diffusion Policy), the system can leverage every bit of information from the vision encoder to generate nuanced, continuous control signals. In contrast, the discrete pathway (like OAT) hits a wall. The codebook, with its limited capacity, acts like a filter, preventing more detailed visual insights from translating into finer motor control. This means building a bigger, more expensive vision encoder for a discrete action VLA model might just be throwing money away.
The Hard Numbers: Where Scaling Falls Flat
The researchers validated the Compression Gap principle using the LIBERO benchmark, a standard for robotic manipulation tasks. Their findings are stark:
- Encoder Upgrades: Upgrading vision encoders improved
Diffusion Policy(a continuous action model) by over 21 percentage points in manipulation performance. - Attenuated Gains for OAT: For
OAT(a discrete action model), encoder upgrades resulted in substantially attenuated gains across different model scales. In practical terms, performance barely budged. - Encoder Quality Gradient: When testing across four different vision encoders of varying quality,
Diffusion Policyshowed a monotonic improvement in performance directly tracking encoder quality.OAT, however, remained flat, indicating it couldn't utilize the better visual inputs. - Codebook Capacity: Crucially, when the researchers increased the codebook size for
OAT, it partially recovered its sensitivity to encoder upgrades. This provides strong causal evidence that the codebook's fixed capacity was indeed the bottleneck. Relaxing that constraint allowed more visual information to pass through.
Why This Matters for Your Next Drone Project
For drone hobbyists, builders, and engineers, this paper isn't just academic; it's a blueprint for future development. Autonomous drones performing complex tasks—like precision agriculture, intricate inspection, or search and rescue—require highly granular control. If your VLA model relies on discrete actions, investing in a top-tier vision encoder might be a fruitless endeavor. You'll be paying for capabilities that your drone's "action language" can't express.
This insight pushes us toward prioritizing VLA architectures that support continuous action spaces, like Diffusion Policy. This means designing systems that can translate visual understanding directly into fluid control signals, rather than predefined commands. For real-world drone applications, this could unlock more agile flight, better obstacle avoidance, and more precise interaction with the environment, moving beyond simple waypoint navigation or basic object following.
Consider the practical implications: you might be able to achieve superior performance with a moderately powerful vision encoder paired with a continuous action policy, rather than an expensive, cutting-edge encoder hobbled by a discrete action bottleneck. This could lead to more efficient, lighter, and more cost-effective autonomous drone systems.
The Road Ahead: Limitations and Unanswered Questions
While compelling, this research opens up several new avenues and highlights existing challenges:
- Computational Cost:
Diffusion Policyand other continuous action models can be computationally more intensive, which is a significant hurdle for edge AI deployments on drones where weight, power, and latency are critical constraints. - Hybrid Approaches: The paper focuses on purely discrete or purely continuous action spaces. Could a hybrid approach, combining the simplicity of discrete actions for high-level planning with continuous refinement for low-level execution, offer a middle ground?
- Codebook Optimization: While increasing codebook size helps, there's a trade-off. How large can codebooks realistically get before training complexity or memory requirements become prohibitive for drone hardware?
- Task Complexity: The
LIBERObenchmark is excellent, but real-world drone tasks often involve dynamic environments, unpredictable elements, and multi-modal sensory inputs. How do these findings generalize to even more complex scenarios? - Beyond Actions: The "compression gap" might exist in other parts of the VLA pipeline. Are there similar bottlenecks in how models understand natural language commands or integrate different sensor modalities?
Can You Build Around This?
For the ambitious hobbyist or research engineer, this paper offers clear guidance. If you're building a VLA system for a drone, strongly consider continuous action policies. While the LIBERO benchmark relies on specific robotic manipulation platforms, the underlying principles apply directly to drone control.
Open-source implementations of Diffusion Policy are available, making it feasible to experiment. The challenge lies in adapting these models for drone-specific kinematics and dynamics, and running them efficiently on onboard hardware. This might mean exploring quantized versions of continuous policies or leveraging more efficient Vision-Language Models (VLMs) as backbones. As mentioned in the related work, papers like "EffiMiniVLM: A Compact Dual-Encoder Regression Framework" are directly relevant here, offering strategies for creating compact and efficient VLMs that could potentially work within resource constraints, even if the action space is continuous. These efficient VLMs could serve as the upgraded vision encoders without excessive computational overhead.
Furthermore, the quality of your base VLM matters. "CoME-VL: Scaling Complementary Multi-Encoder Vision-Language Learning" highlights methods for improving these foundational components, which are crucial for feeding rich, relevant information into any action policy. And critically, even with the best vision and action policies, issues like "Understanding the Role of Hallucination in Reinforcement Post-Training of Multimodal Reasoning Models" remind us that reliable, non-hallucinatory outputs are paramount for truly autonomous and safe drone operation. After all, a drone that 'hallucinates' an action is just as dangerous as one that can't understand its environment.
The Future of Drone Intelligence
This research is a wake-up call: simply throwing more compute at vision encoders won't magically make our drones smarter if we're not also re-evaluating how they translate perception into action. For truly intelligent, adaptable drones, we must meticulously design our AI pipelines to avoid information bottlenecks, ensuring that every bit of processing power contributes to a more capable and precise machine.
Paper Details
Title: The Compression Gap: Why Discrete Tokenization Limits Vision-Language-Action Model Scaling Authors: Takuya Shiba Published: Unpublished (arXiv) arXiv: 2604.03191 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.