SelfEvo: Drones Learning to 'See' Better, All By Themselves
SelfEvo is a new framework enabling drone perception models to continuously improve 4D environmental understanding using only unlabeled video. It boosts depth and camera estimation accuracy, fostering truly autonomous and adaptable operations.
TL;DR: SelfEvo is a new framework that allows drone perception models to continuously improve their understanding of dynamic 4D environments using only unlabeled video. It leverages a clever self-distillation technique, boosting depth and camera estimation accuracy significantly without requiring expensive manual annotations. This means smarter, more adaptable drones.
For years, autonomous drones have been held back by a fundamental constraint: they learn to "see" the world by being shown countless examples, each meticulously labeled by humans. This process is slow, expensive, and struggles with the unpredictable, ever-changing reality our drones operate in. Now, a new research paper introduces SelfEvo, a framework that could change this by allowing drones to learn to perceive dynamic environments in 4D—that's 3D space plus time—all by themselves, using nothing but raw video footage.
The Annotation Bottleneck for Autonomous Vision
Current multi-view reconstruction models, which are crucial for a drone's ability to map its surroundings and track its own movement (SLAM), are heavily reliant on fully supervised training. This means feeding them ground-truth 3D and 4D annotations, essentially pre-labeled maps and motion paths. For static scenes, this is already a monumental task. For dynamic scenes—think bustling city streets, moving vehicles, or swaying trees—these annotations are incredibly scarce and prohibitively expensive to create.
This dependency severely limits the scalability of our drone AI. It means a drone trained in one environment might struggle in another, or fail to adapt as its operational area changes, because it can't independently refine its understanding of a new, dynamic reality. The cost and time involved in manual data labeling are a significant drag on progress for truly adaptable autonomous systems.
How SelfEvo Teaches Itself to See in 4D
SelfEvo tackles this annotation bottleneck head-on with an ingenious "self-distillation" approach. Instead of needing external ground truth, it creates its own pseudo-targets for improvement. The core idea revolves around what the authors call "spatiotemporal context asymmetry."
Here’s the breakdown of how it works:
- Teacher-Student Setup: SelfEvo uses a pre-trained multi-view reconstruction model and sets it up in a teacher-student configuration.
- Context Asymmetry: The "teacher" model is fed a richer, more complete set of video frames (a broader spatiotemporal context) to generate its perception of the scene. This "richer context" allows it to create more accurate depth maps and camera poses.
- Pseudo-Targets: The teacher's high-quality outputs—depth estimations and camera poses—are then used as "stop-gradient pseudo targets" for the "student" model.
- Reduced Context: The student model, however, is trained on a reduced set of frames or a narrower spatiotemporal context. This forces the student to learn to infer accurate 4D perception even with less input, guided by the teacher's more informed estimates.
- Continuous Improvement: The teacher itself is not static; it's updated as an Exponential Moving Average (
EMA) of the student after each training step. This creates a continuous feedback loop where the model constantly refines its own understanding. This entire process happens with unlabeled videos, meaning any raw video footage captured by the drone can be used to improve its perception capabilities.
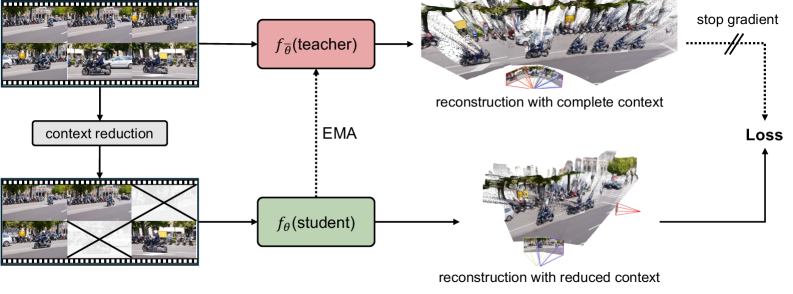 Figure 2: We propose an annotation-free self-improving framework that continually post-trains pretrained multi-view reconstruction models using unlabeled videos. Our method forms an online self-distillation loop where a richer-context teacher provides stop-gradient pseudo targets to a student operating on reduced context, and is updated as an EMA of the student after each step.
Figure 2: We propose an annotation-free self-improving framework that continually post-trains pretrained multi-view reconstruction models using unlabeled videos. Our method forms an online self-distillation loop where a richer-context teacher provides stop-gradient pseudo targets to a student operating on reduced context, and is updated as an EMA of the student after each step.
The key insight, as shown in the paper's analysis, is that more context leads to better initial reconstruction quality. By letting the teacher leverage this richer context, it can guide the student effectively.
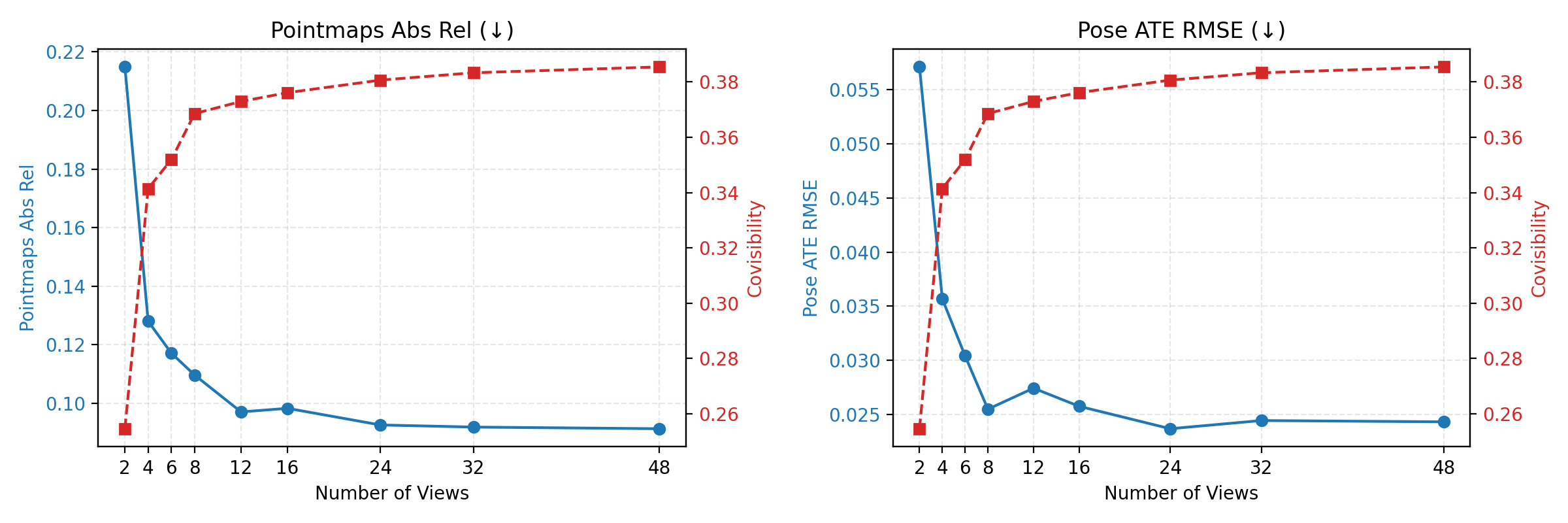 Figure 5: Context improves feedforward reconstruction quality. Starting from two temporally distant anchor frames, we progressively add intermediate frames as context and evaluate performance only on the anchors. As the number of input views increases, the overall covisibility increases, while both pointmap and pose errors decrease.
Figure 5: Context improves feedforward reconstruction quality. Starting from two temporally distant anchor frames, we progressively add intermediate frames as context and evaluate performance only on the anchors. As the number of input views increases, the overall covisibility increases, while both pointmap and pose errors decrease.
Real Gains, No Labels Required
The authors put SelfEvo through its paces on eight different benchmarks, spanning diverse datasets and domains, and the results are compelling. SelfEvo consistently improved pre-trained baselines like VGGT and π³ (Pi-cubed), demonstrating its versatility.
The most significant gains were observed in dynamic scenes, which is exactly where current supervised methods struggle. Specifically, SelfEvo achieved:
- Up to 36.5% relative improvement in video depth estimation.
- Up to 20.1% relative improvement in camera estimation.
Crucially, these improvements were achieved without using any labeled data. This means a drone can get smarter just by flying around and observing. The paper's qualitative results also show impressive improvements in reconstructing complex scenes and object motion, even for unseen domains like animal motion or robotic scenes.
 Figure 3: Visual result on unseen-domain data, including animal motion, robotics and ego-centric.
Figure 3: Visual result on unseen-domain data, including animal motion, robotics and ego-centric.
 Figure 4: Qualitative results for camera and geometry on in the wild videos.
Figure 4: Qualitative results for camera and geometry on in the wild videos.
The checkpoint-wise evaluations further illustrate this continuous learning, showing sustained improvement over time on various metrics.
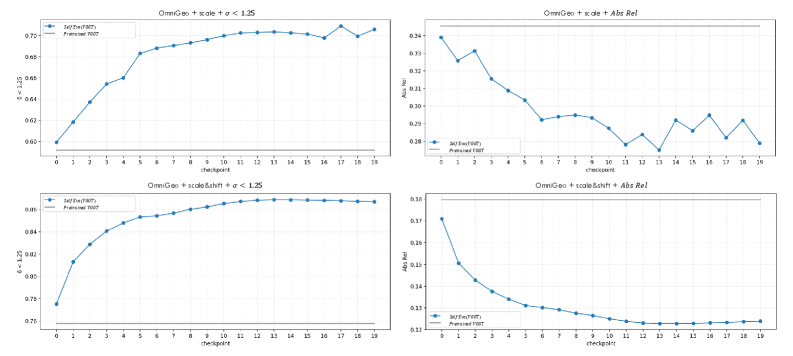 Figure 6: Checkpoint-wise depth evaluation on the held-out OmniGeo benchmark. We retrospectively evaluate all training checkpoints of SelfEvo(VGGT) on OmniGeo after training is completed. Top row: scale alignment; bottom row: scale-and-shift alignment. Left: δ<1.25\delta<1.25 (higher is better); right: Abs Rel (lower is better). The horizontal gray line denotes the pretrained VGGT baseline. Across both alignment settings, self-improvement leads to substantial gains over the pretrained model throughout training, showing self-improvement on held-out depth benchmarks.
Figure 6: Checkpoint-wise depth evaluation on the held-out OmniGeo benchmark. We retrospectively evaluate all training checkpoints of SelfEvo(VGGT) on OmniGeo after training is completed. Top row: scale alignment; bottom row: scale-and-shift alignment. Left: δ<1.25\delta<1.25 (higher is better); right: Abs Rel (lower is better). The horizontal gray line denotes the pretrained VGGT baseline. Across both alignment settings, self-improvement leads to substantial gains over the pretrained model throughout training, showing self-improvement on held-out depth benchmarks.
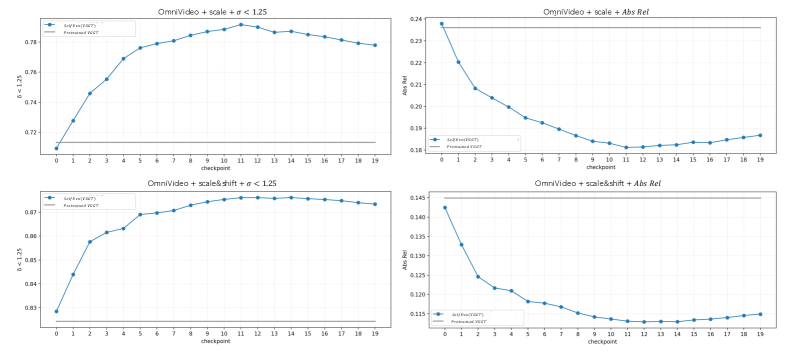 Figure 7: Checkpoint-wise depth evaluation on the held-out OmniVideo benchmark. We retrospectively evaluate all training checkpoints of SelfEvo(VGGT) on OmniVideo after training is completed. Top row: scale alignment; bottom row: scale-and-shift alignment. Left: δ<1.25\delta<1.25 (higher is better); right: Abs Rel (lower is better). The horizontal gray line denotes the pretrained VGGT baseline. The curves show clear and sustained improvement across checkpoints, with rapid gains in the early stage and mild saturation later, again supporting self-improvement on depth benchmarks.
Figure 7: Checkpoint-wise depth evaluation on the held-out OmniVideo benchmark. We retrospectively evaluate all training checkpoints of SelfEvo(VGGT) on OmniVideo after training is completed. Top row: scale alignment; bottom row: scale-and-shift alignment. Left: δ<1.25\delta<1.25 (higher is better); right: Abs Rel (lower is better). The horizontal gray line denotes the pretrained VGGT baseline. The curves show clear and sustained improvement across checkpoints, with rapid gains in the early stage and mild saturation later, again supporting self-improvement on depth benchmarks.
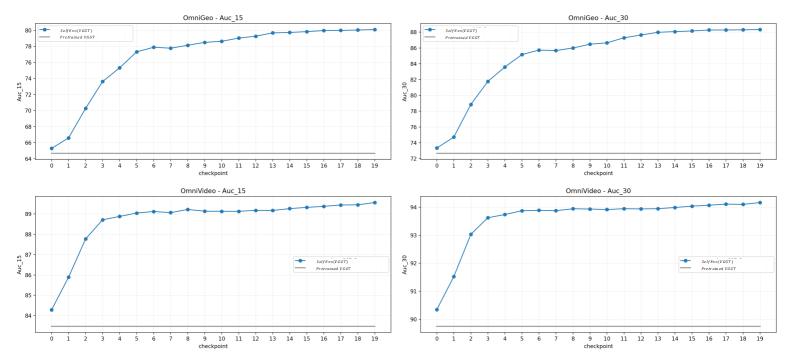 Figure 8: Checkpoint-wise camera evaluation on held-out OmniGeo and OmniVideo benchmarks. We retrospectively evaluate all training checkpoints of SelfEvo(VGGT) after training is completed. Top row: OmniGeo; bottom row: OmniVideo. Left: AUC@15; right: AUC@30. Higher is better for all metrics. The horizontal gray line denotes the pretrained VGGT baseline. Camera estimation improves consistently throughout training on both held-out benchmarks, further demonstrating the self-improvement ability of our framework beyond depth prediction alone.
Figure 8: Checkpoint-wise camera evaluation on held-out OmniGeo and OmniVideo benchmarks. We retrospectively evaluate all training checkpoints of SelfEvo(VGGT) after training is completed. Top row: OmniGeo; bottom row: OmniVideo. Left: AUC@15; right: AUC@30. Higher is better for all metrics. The horizontal gray line denotes the pretrained VGGT baseline. Camera estimation improves consistently throughout training on both held-out benchmarks, further demonstrating the self-improvement ability of our framework beyond depth prediction alone.
SelfEvo also demonstrated qualitative improvements when trained on additional unlabeled video sources like DynPose-100K and Egocentric-10K data.
 Figure 9: Qualitative results on additional training sources. We further apply SelfEvo to VGGT using two additional unlabeled video sources beyond our main setup: DynPose-100K and Egocentric-10K. The first three examples show results after training on a very small fully in-the-wild subset of DynPose-100K, using only 85 internet videos, while the last example shows results after training on egocentric data. In each pair, the left result is from the pretrained VGGT model and the right result is from SelfEvo(VGGT).
Figure 9: Qualitative results on additional training sources. We further apply SelfEvo to VGGT using two additional unlabeled video sources beyond our main setup: DynPose-100K and Egocentric-10K. The first three examples show results after training on a very small fully in-the-wild subset of DynPose-100K, using only 85 internet videos, while the last example shows results after training on egocentric data. In each pair, the left result is from the pretrained VGGT model and the right result is from SelfEvo(VGGT).
Why This Matters for Your Drone
This research is a significant step forward for autonomous drones. If a drone can learn to accurately perceive and understand dynamic environments in 4D without explicit human supervision, it opens the door to truly adaptable and resilient autonomous operations.
- Real-time Adaptability: Drones could continuously refine their understanding of changing environments, like construction sites, disaster zones, or dynamic urban landscapes. This means better obstacle avoidance, more robust navigation, and more reliable mapping in real-time.
- Reduced Development Costs: The need for expensive, time-consuming manual 3D/4D data labeling is drastically reduced. Instead, drones can improve just by flying and collecting video, making development cycles faster and cheaper.
- Enhanced Autonomy: For tasks like package delivery, infrastructure inspection, or search and rescue, drones often encounter novel or unpredictable conditions. SelfEvo allows them to learn from these experiences on the fly, improving their perception of complex scenarios involving moving objects, varying illumination, and occlusions.
- Better Foundation for AI: Accurate 4D perception is the bedrock for higher-level AI functions like intelligent decision-making and complex task execution. A drone that "sees" better can "think" better.
Limitations & What's Next
While SelfEvo represents a significant step forward, it's important to acknowledge its current scope and limitations:
- Perception Only: This framework focuses purely on improving perception (depth and camera pose estimation). It doesn't directly address the challenges of high-level reasoning, decision-making, or control for a drone. A drone still needs a "brain" to act wisely based on this enhanced perception.
- Post-Training: SelfEvo works by improving pretrained multi-view reconstruction models. It's not designed to learn complex 4D perception from scratch using only unlabeled data, but rather to fine-tune and enhance existing capabilities.
- Computational Overhead: While the paper doesn't detail hardware requirements for deployment, the online self-distillation loop, especially with a "richer-context teacher," likely demands significant computational resources. Implementing this on small, power-constrained drone edge hardware (like an
NVIDIA JetsonorQualcomm Snapdragon Flight) would require careful optimization and might be a hurdle for real-time application in some scenarios. - Reliance on Base Model: The quality of improvement is inherently tied to the quality of the initial pretrained model. While it shows consistent gains, a weak base model might still yield sub-optimal results.
- Environmental Generalization: While promising results are shown on unseen domains, the paper doesn't deeply explore extreme edge cases like heavy fog, rain, or very low light conditions, which are common challenges for drone vision systems.
Can You Build This?
For the average hobbyist builder, fully replicating the training of SelfEvo from scratch, especially with large base models like VGGT or π³, is likely beyond reach. These models demand substantial GPU resources and deep machine learning expertise.
However, the authors have provided a project page (https://self-evo.github.io/). If they release pre-trained models or the framework's code, it could open avenues for more accessible experimentation. A hobbyist might be able to:
- Utilize a pre-trained SelfEvo-improved model: If the researchers release models fine-tuned with SelfEvo, integrating these into existing drone projects for enhanced depth and pose estimation would be feasible.
- Fine-tune with personal data: With access to the framework's code and a powerful workstation (e.g., a gaming PC with a high-end GPU), a dedicated hobbyist could potentially fine-tune a smaller pre-trained model on their own unlabeled drone footage to adapt it to specific environments.
The barrier to entry here is primarily computational power and familiarity with advanced machine learning frameworks, rather than specialized drone hardware beyond a capable camera.
The Broader AI Landscape
This pursuit of smarter, more autonomous drones isn't happening in a vacuum. SelfEvo pushes the boundaries of perception, but what happens after the drone "sees" its world better?
A drone equipped with SelfEvo's improved perception still needs a sophisticated brain to make sense of it. This is where work like "Act Wisely: Cultivating Meta-Cognitive Tool Use in Agentic Multimodal Models" comes in. If a drone can self-improve its 4D perception, the next critical step is for its AI to decide when to trust that self-learned knowledge and when to seek external assistance. It's about knowing how to use the perception effectively.
Conversely, "Seeing but Not Thinking: Routing Distraction in Multimodal Mixture-of-Experts" highlights a crucial challenge. Even if a drone's perception system, enhanced by SelfEvo, accurately "sees" the environment, the AI might still fail to reason correctly about it. This paper serves as an important reminder that advanced perception needs robust reasoning to be truly effective for autonomous navigation and decision-making—a challenge that future drone AI must overcome.
Finally, "OpenVLThinkerV2: A Generalist Multimodal Reasoning Model for Multi-domain Visual Tasks" shows us what that advanced "brain" might look like. Such a generalist model could process the rich 4D perception data generated by SelfEvo, enabling the drone to perform complex, multi-domain tasks, moving beyond just perception to full intelligent autonomy.
SelfEvo offers a tangible path towards drones that truly learn from experience, autonomously improving their understanding of the world without constant human intervention. The future of adaptable, intelligent drone operations just got a clear upgrade.
Paper Details
Title: Self-Improving 4D Perception via Self-Distillation Authors: Nan Huang, Pengcheng Yu, Weijia Zeng, James M. Rehg, Angjoo Kanazawa, Haiwen Feng, Qianqian Wang Published: April 2026 arXiv: 2604.08532 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.